Scrapy爬虫(四):imdb.cn爬虫实例
该章节将实现爬取imdb.cn所有影视资料的scrapy爬虫。
imdb.cn网站结构分析
imdb.cn是国内的一个影视资料库,应该也是作者爬取别人的数据生成的一个网站,并不是imdb的中文网站。学会爬虫后其实我们也可以做一个这样的网站。
我们打开http://www.imdb.cn/NowPlaying/ 影视资料库页面,如图
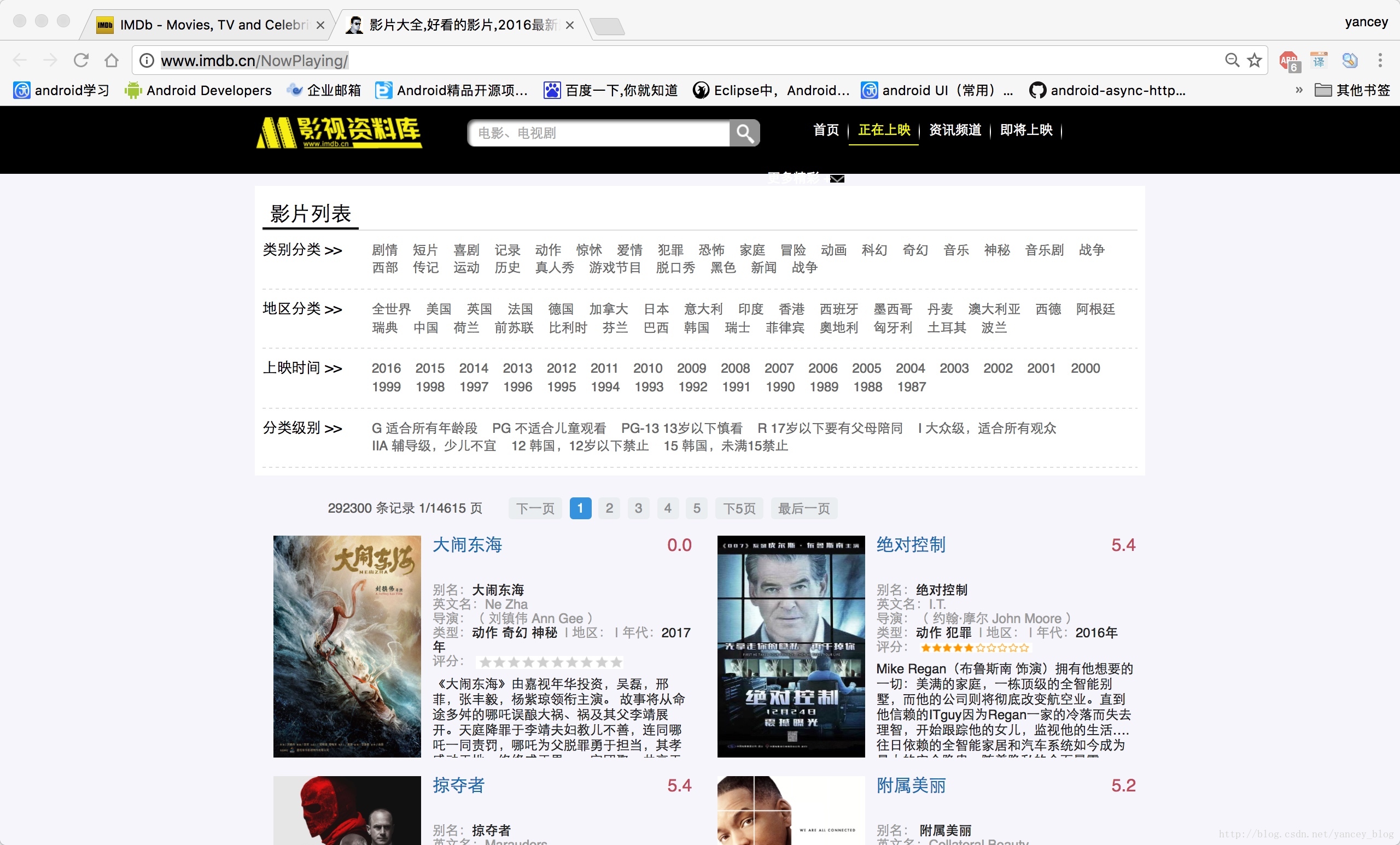
该资料库共有292300 条记录 14615 页

通过分析可以知道页码对应的url为http://www.imdb.cn/nowplaying/{页码}
例如:
第一页的url为http://www.imdb.cn/nowplaying/1
14615页的url为http://www.imdb.cn/nowplaying/14615
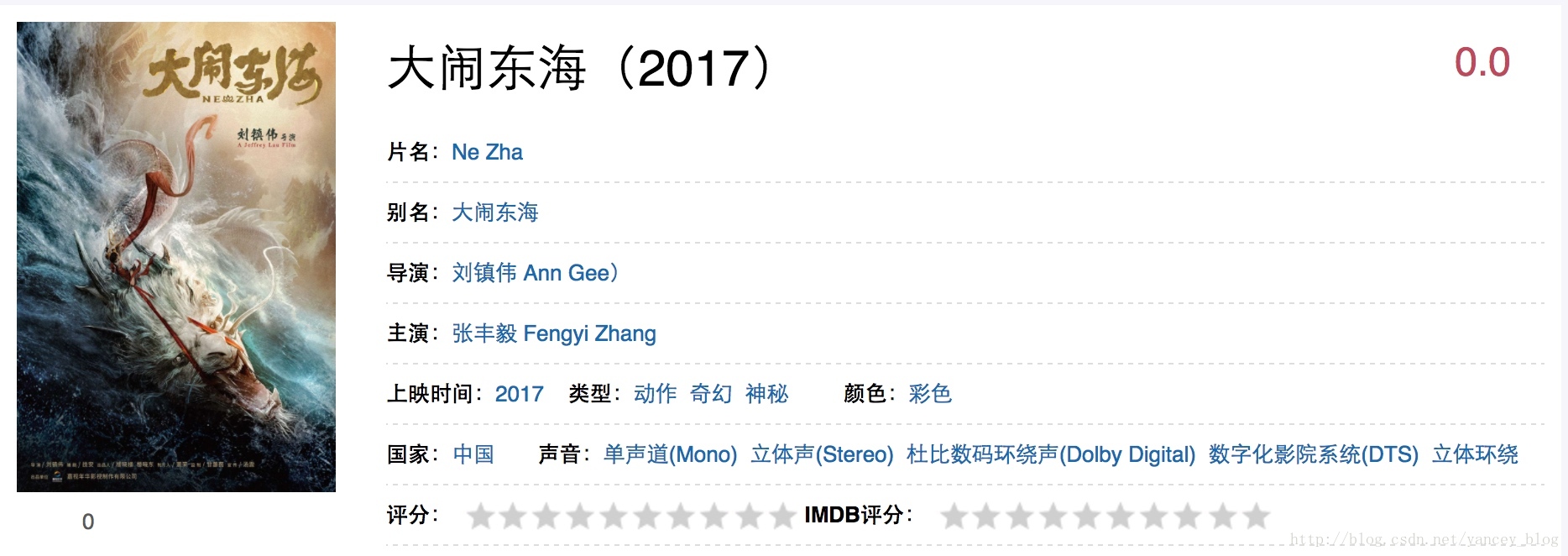
接下来我们分析每个电影的url,我们点开《大脑东海》它的url为http://www.imdb.cn/title/tt4912402 同样的点开其他的电影,可以发现一个规律,url的格式为http://www.imdb.cn/title/tt{多个数字}
好,现在我们已经找到两个规律,一个是所有电影资料列表的url规律,另一个是每个电影的url规律。我们现在要通过所有的列表,下载每个电影的详细信息,比如电影名称、导演、演员、上映时间、国家等信息。
创建爬虫项目
使用命令创建一个项目scrapy startproject imdb
MACBOOK:~ yancey$ scrapy startproject imdb
New Scrapy project 'imdb', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/yancey/imdb
You can start your first spider with:
cd imdb
scrapy genspider example example.com使用pycharm打开我们创建的imdb项目,项目结构如下
根据我们需要的信息重写items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ImdbItem(scrapy.Item):
# define the fields for your item here like:
url = scrapy.Field() #url
title = scrapy.Field() #影片名在spiders目录下创建一个imdbspider.py
# coding:utf-8
from scrapy.spiders import CrawlSpider, Request, Rule
from imdb.items import ImdbItem
from scrapy.linkextractors import LinkExtractor
class ImdbSpider(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.cn']
rules = (
Rule(LinkExtractor(allow=r"/title/ttd+$"), callback="parse_imdb", follow=True),
)
def start_requests(self):
pages = []
for i in range(1, 14616):
url = "http://www.imdb.cn/nowplaying/" + str(i)
yield Request(url=url, callback=self.parse)
def parse_imdb(self, response):
item = ImdbItem()
item['url'] = response.url
item['title'] = "".join(response.xpath('//*[@class="fk-3"]/div[@class="hdd"]/h3/text()').extract())
pass简单解释一下
- name是运行spider的唯一名称
- allowed_domains允许的域名前缀
- rules url规则,上面allow=r”/title/ttd+$”就是我们分析后的正则表达式,title前匹配allowed_domains,满足rules的callback=”parse_imdb”,意思是满足这个条件就执行parse_imdb方法。
- start_requests 由于分析得到imdb.cn的url规律较为简单,我们可以通过遍历所有的url到初始请求url集合中,start_requests方法可以轻松做到。
- parse_imdb方法,item[‘url’] = response.url得到url地址,item[‘title’]通过xpath解析得到电影的title,如《大脑东海》。
运行imdb爬虫
运行我们刚写的imdb爬虫,进入imdb目录,使用命令scrapy crawl imdb
MACBOOK:imdb yancey$ scrapy crawl imdb
/Users/yancey/imdb/imdb/spiders/imdbspider.py:3: ScrapyDeprecationWarning: Module `scrapy.spider` is deprecated, use `scrapy.spiders` instead
from scrapy.spider import CrawlSpider, Request, Rule
2016-12-26 23:24:22 [scrapy] INFO: Scrapy 1.2.0 started (bot: imdb)
2016-12-26 23:24:22 [scrapy] INFO: Overridden settings: {'BOT_NAME': 'imdb', 'ROBOTSTXT_OBEY': True, 'NEWSPIDER_MODULE': 'imdb.spiders', 'SPIDER_MODULES': ['imdb.spiders']}
2016-12-26 23:24:22 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.logstats.LogStats']
2016-12-26 23:24:22 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-12-26 23:24:22 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-12-26 23:24:22 [scrapy] INFO: Enabled item pipelines:
[]
2016-12-26 23:24:22 [scrapy] INFO: Spider opened
2016-12-26 23:24:22 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-12-26 23:24:22 [scrapy] DEBUG: Crawled (404) <GET http://www.imdb.cn/robots.txt> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/1> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/8> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/7> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/2> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/5> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/3> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/4> (referer: None)
2016-12-26 23:24:23 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/6> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/9> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/10> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/14> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/11> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/12> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/15> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/16> (referer: None)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/nowplaying/13> (referer: None)
... ...
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/title/tt4912402> (referer: http://www.imdb.cn/nowplaying/1)
2016-12-26 23:24:24 [scrapy] DEBUG: Crawled (200) <GET http://www.imdb.cn/title/tt0414387> (referer: http://www.imdb.cn/nowplaying/7)
2016-12-26 23:24:24 [scrapy] DEBUG: Scraped from <200 http://www.imdb.cn/title/tt4912402>
{'title': '大闹东海(2017)', 'url': 'http://www.imdb.cn/title/tt4912402'}