Scrapy爬虫(二):爬虫简介
什么是爬虫?
爬虫的本质就是将互联网网页(数据)下载下来的程序。
爬虫通常为PC端爬虫、以及移动端爬虫(接口数据窃取 抓包 wap站),当然我们更多的是使用PC端的爬虫。
如下图可以看出爬虫相对于人浏览网页的不同,可以在脑袋里有个简单的概念。

通过对互联网无数个url数据的下载,url之间可能又有关联,于是形成了犹如蜘蛛网状的结构,而爬虫就守在这张大网之上,因此我们通常又将爬虫成为蜘蛛。
爬虫的价值?
列几个简单的例子,看看就行
- 搜索引擎
- 今日头条
- 比价网
- 大数据
最简单的python爬虫
urllib库 基于python3.5
# encoding:UTF-8
import urllib.request
def download_data():
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
print(response.getcode())
if response.getcode() == 200:
print(response.read())
download_data()运行结果如下

可以看出爬虫下载都是网页源码。
爬虫基本架构
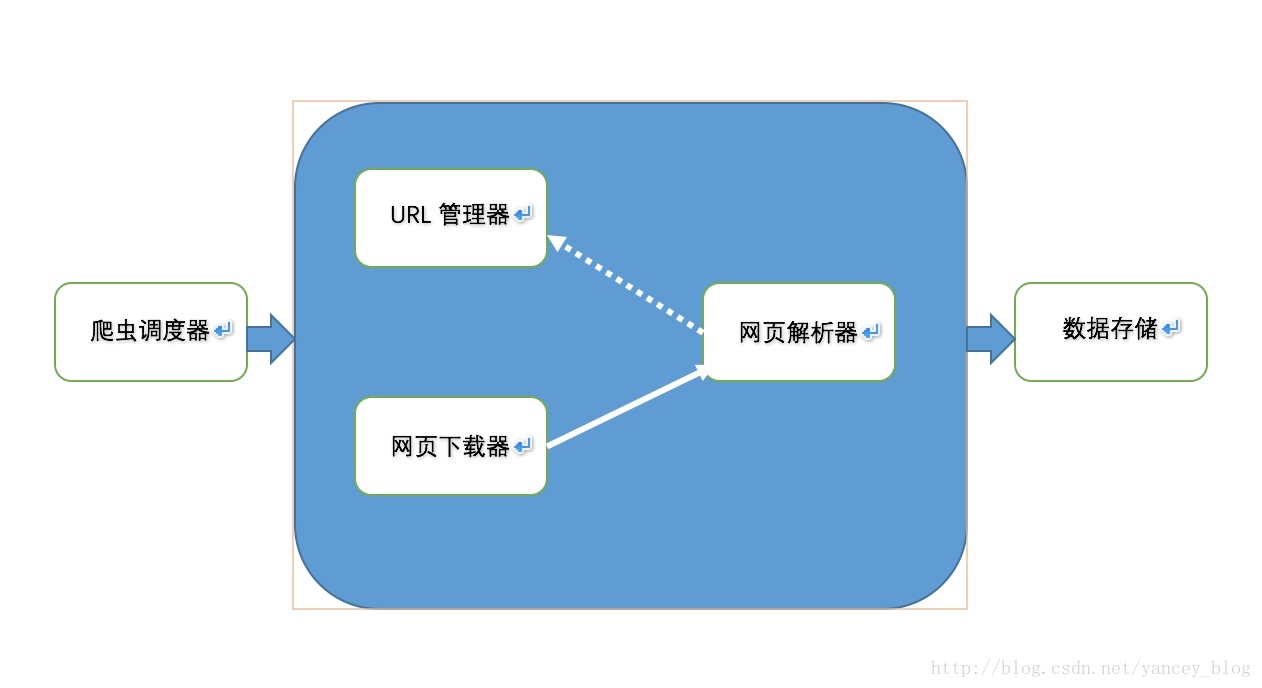
由上图可以看出爬虫一般由爬虫调度器、URL管理器、网页下载器、网页解析器、数据存储这几个模块组成。
爬虫调度器主要是对url管理器、网页下载器网页解析器进行管理。
URL管理器主要通过初始url及网页解析器获得的url进行存储管理,并为调度器提供接口,为网页下载器提供下载入口。
网页下载器主要功能就是下载该url下的网页数据(源码)
网页解析器一方面解析出我们需要的价值数据,一方面又将网页下载器下载数据中的url存储到url管理器中。
数据存储是将网页解析器的解析的价值数据存储到内存、数据库、文件等。
scrapy环境配置
本处只介绍ubuntu下scrapy的环境配置,其它环境下学习的话请自行配置,要求大概都是这样的。
- 安装更新python
ubuntu16.04自带python2.7.11+、3.5.1+
执行如下命令更新就可
sudo apt-get update
sudo apt-get upgrade- 安装pycharm
下载http://www.jetbrains.com/pycharm/download/
解包
sudo -zxvf pycharm-professional-2016.2.3.tar.gz安装
sudo sh /pycharm-professional-2016.2.3/bin/pycharm.sh快捷方式
把/usr/share/applications/Pychram用鼠标拖出来就可- 1
- 更新pip
sudo pip install --upgrade pip- 1
pip更新有问题时,执行如下命令在更新pip就可
sudo rm -rf ~/.pip/cache/
sudo rm -rf /root/.pip/cache- 1
- 2
- 安装scrapy
pip install --upgrade Twisted- 1
sudo apt-get install libssl-dev- 1
pip install Scrapy- 1