历史
埃里克·布鲁尔(因此 CAP 定理又被称为 Brewer's theorem )大约在 1998 年就有了相关想法,然后在 1999 年作为一个原则将其发表出来,并且最终在 1999 年的 PODC 上作为一个猜想将其正式提出。2002 年,MIT 的 Seth Gilbert 和 Nancy Lynch 做了一个非常收束条件下的证明,使其成为一个定理。
这里想说明的一点是,说到 CAP 原则(类似的意思,这个是我随口起的),可以是定义模糊、涵盖广泛、启发分布式系统设计的原则。但是 CAP 定理,则属于每个性质都有严格数学定义、结论有完善推导的理论计算科学范畴的概念。大多数人想表达前者的意思,但用的却是后者的术语。DDIA 作者 Martin Kleppmann 大佬,还专门就此吐槽了一番。
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
最多满足其中的两个特性。也就是下图所描述的。分布式系统要么满足CA,要么CP,要么AP。无法同时满足CAP。
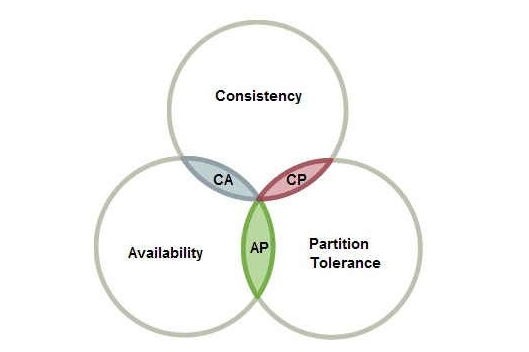
C、 A、P的含义
借用一下维基百科CAP理论一文中关于C、A、P三者的定义。
Consistency : Every read receives the most recent write or an error
Availability : Every request receives a (non-error) response – without the guarantee that it contains the most recent write
Partition tolerance : The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
三者的定义及个人理解如下:
-
Consistency:一致性,原文翻译过来是说,对于任何从客户端发达到分布式系统的数据读取请求,要么读到最新的数据要么失败。换句话说,一致性是站在分布式系统的角度,对访问本系统的客户端的一种承诺:要么我给您返回一个错误,要么我给你返回绝对一致的最新数据,不难看出,其强调的是数据正确。
-
Availability:可用性,原文翻译过来是说,对于任何求从客户端发达到分布式系统的数据读取请求,都一定会收到数据,不会收到错误,但不保证客户端收到的数据一定是最新的数据。换句话说,可用性是站在分布式系统的角度,对访问本系统的客户的另一种承诺:我一定会给您返回数据,不会给你返回错误,但不保证数据最新,强调的是不出错。
-
Partition tolerance:分区容忍性,这个词有点怪,如果直接看中文的确有点不太好理解。那么看原文翻译怎么说的,分布式系统应该一直持续运行,即使在不同节点间同步数据的时候,出现了大量的数据丢失或者数据同步延迟。
(PS:^V^,您瞧瞧,包容度多高,简直是打不死的小强,现在应该能够理解为什么用tolerance容忍度这个词了吧。)
换句话说,分区容忍性是站在分布式系统的角度,对访问本系统的客户端的再一种承诺:我会一直运行,不管我的内部出现何种数据同步问题,强调的是不挂掉。
搞明白三个字母的准确含义之后,结合到上面那张图,应该比较容易理解了。
对于一个分布式系统而言,P是前提,必须保证,因为只要有网络交互就一定会有延迟和数据丢失,这种状况我们必须接受,必须保证系统不能挂掉。试想一下,如果稍微出现点数据丢包,我们的整个系统就挂掉的话,我们为什么还要做分布式呢?所以,按照CAP理论三者中最多只能同时保证两者的论断,对于任何分布式系统,设计时架构师能够选择的只有C或者A,要么保证数据一致性(保证数据绝对正确),要么保证可用性(保证系统不出错)
PS:其实维基百科的原文里面也有这么一段,说的也是上面的意思,我就不翻译了:
CAP is frequently misunderstood as if one has to choose to abandon one of the three guarantees at all times. In fact, the choice is really between consistency and availability only when a network partition or failure happens; at all other times, no trade-off has to be made.
总结
现如今,对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,节点只会越来越多,所以节点故障、网络故障是常态,因此分区容错性也就成为了一个分布式系统必然要面对的问题。那么就只能在C和A之间进行取舍。但对于传统的项目就可能有所不同,拿银行的转账系统来说,涉及到金钱的对于数据一致性不能做出一丝的让步,C必须保证,出现网络故障的话,宁可停止服务,可以在A和P之间做取舍。
总而言之,没有最好的策略,好的系统应该是根据业务场景来进行架构设计的,只有适合的才是最好的。
参考:
https://blog.csdn.net/guitar___/article/details/80656681
https://blog.csdn.net/yeyazhishang/article/details/80758354
https://zhuanlan.zhihu.com/p/105907157?utm_source=wechat_session