WHERE用于过滤行,如果想过滤分组,需要使用HAVING。
实例:
列出具有两个以上产品且价格大于等于4的供应商。
SELECT vend_id,COUNT(*) AS num_prods FROM Products
WHERE prod_price>=4
GROUP BY vend_id
HAVING COUNT(*)>=2
面试容易被坑:FROM子句一定必须使用吗? 不是的。SELECT 1+1也是合法的。
爱出的面试题:
1.找出表中重复数据。
SELECT D_ADDRESS,COUNT(D_ADDRESS) AS ADDRESS_COUNT FROM T_DEMO
GROUP BY D_ADDRESS HAVING COUNT(D_ADDRESS)>1

注意下面这种情况:
SELECT D_ADDRESS,COUNT(1) AS ADDRESS_COUNT FROM T_DEMO
GROUP BY D_ADDRESS HAVING COUNT(1)>1
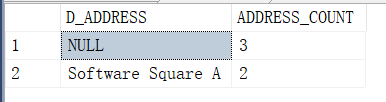
值为NULL的也会被抓出来,具体需要哪种看具体情况。
2.删除重复数据。(注意:这里有坑,不是让你全删了,其实是希望你删掉重复的,并保留一条数据。)
2.1 如果只有一个字段重复:D_ADDRESS
SELECT * FROM T_DEMO
WHERE D_ADDRESS IN
(SELECT D_ADDRESS FROM T_DEMO GROUP BY D_ADDRESS HAVING COUNT(D_ADDRESS)>1)
AND D_NAME NOT IN
(SELECT MIN(D_NAME) FROM T_DEMO GROUP BY D_ADDRESS HAVING COUNT(D_ADDRESS)>1)
把SELECT * 换成DELETE就行了。
注意:建议在做任何Insert,Update,Delete操作前,都用SELECT查一下,“预览”一下结果。
当然也可以用Transaction来检查,如果结果不对就rollback,但是多个人同时操作一张表时,transaction可能会锁死表(因为某个人没提交)。
另一种写法:
2.2 把IN换成EXISTS:
SELECT * FROM T_DEMO AS T
WHERE EXISTS
(SELECT 1 FROM T_DEMO WHERE T.D_ADDRESS=D_ADDRESS GROUP BY D_ADDRESS HAVING COUNT(D_ADDRESS)>1)
AND NOT EXISTS
(SELECT 1 FROM T_DEMO GROUP BY D_ADDRESS HAVING COUNT(D_ADDRESS)>1 AND T.D_NAME=MIN(D_NAME))
2.3 如果有多个字段重复:D_ADDRESS 和 D_REMARKS
SELECT * FROM T_DEMO AS T WHERE EXISTS
(SELECT 1 FROM T_DEMO WHERE T.D_REMARKS=D_REMARKS AND T.D_ADDRESS=D_ADDRESS GROUP BY D_ADDRESS,D_REMARKS HAVING COUNT(1)>1)
AND NOT EXISTS
(SELECT 1 FROM T_DEMO GROUP BY D_ADDRESS,D_REMARKS HAVING COUNT(1)>1 AND T.D_NAME=MIN(D_NAME))
注意:这里已经不能使用IN了