CUDA Learning.
#@author: gr
#@date: 2014-04-06
#@email: forgerui@gmail.com
1. Introduction
CPU和GPU的区别。GPU拥有更多的核心数,可以对简单逻辑、大量数据进行并行计算,大大提高了计算能力。
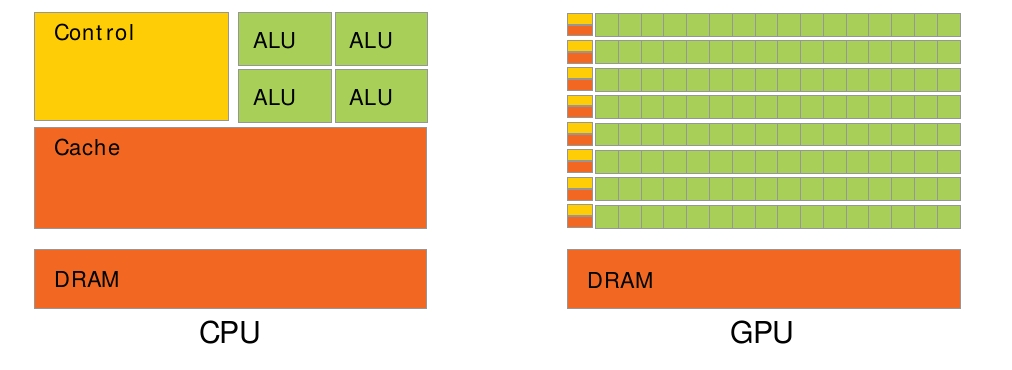
有更多的SM会有更好的性能。
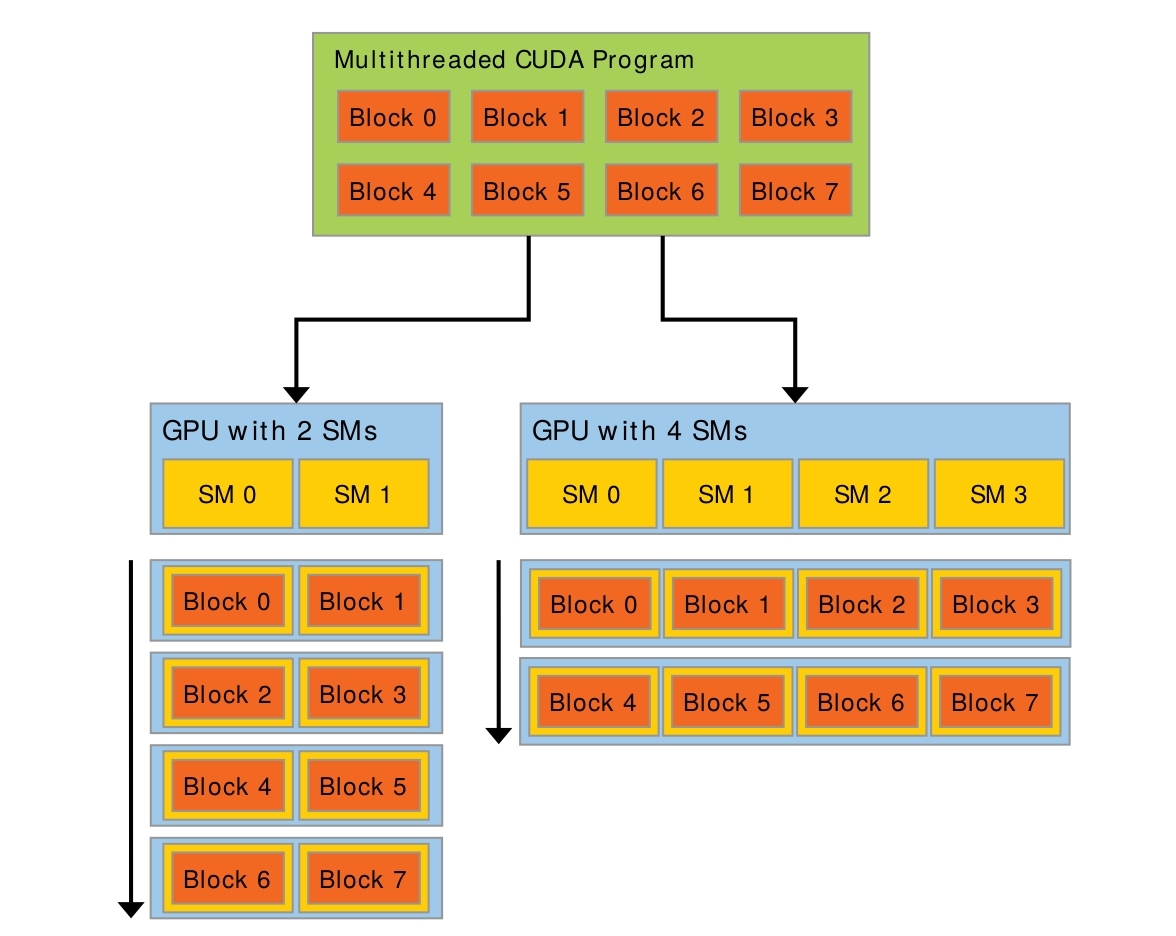
2. General
1.1. kernel
核函数通过__global__声明。通过<<<...>>>指定执行的线程数。
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
1.2. Thread, Block, Grid
一次任务就可以算是一个Grid。在Grid里,可以分成几块Block。而Block里就是每个要处理的Thread。
核函数的形式是kernel<<<G, B, Ns, S>>>(...)。
G代表grid的尺寸,可以是三维的,也可以是int。
B是线程块block的大小。
Ns是每个block除了静态分配的shared memory之外,最多能动态分配的shared memory大小。
S是一个cudaStream_t类型的可选参数,默认值为0, 表示核函数处于哪个流中。
目前的GPU,block中线程的大小最大为1024, 一般取256,而(G = N / B),(N) 是线程总数,但我们需要对(G)的计算结果取上整,我们这里不是使用ceil函数,而是使用下面的式子(G = (N + B - 1) / B)来达到取上整的目的。
取上整会导致启动的线程总数大于需要的整数,我们可以利用条件进行检查。
if (tid < N)
c[tid] = a[tid] + b[tid]
上面实现的一个问题是,G同样也是有限制大小的,如果(N+B-1)/B大于65535时,核函数调用kernel<<<G, B>>>就会出错。为了确保不会启动过多的线程块,可以将线程块固定为某个确定的值。如下,取<<<256, 256>>>,让每个线程多做几个任务:
__global__ void add (int *a, int *b, int *c){
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N){
c[tid] = a[tid] + b[tid];
// blockDim.x * gridDim.x表示的是启动的总共线程数量
tid += blockDim.x * gridDim.x;
}
}
add<<<256, 256>>>(d_a, d_b, d_c);
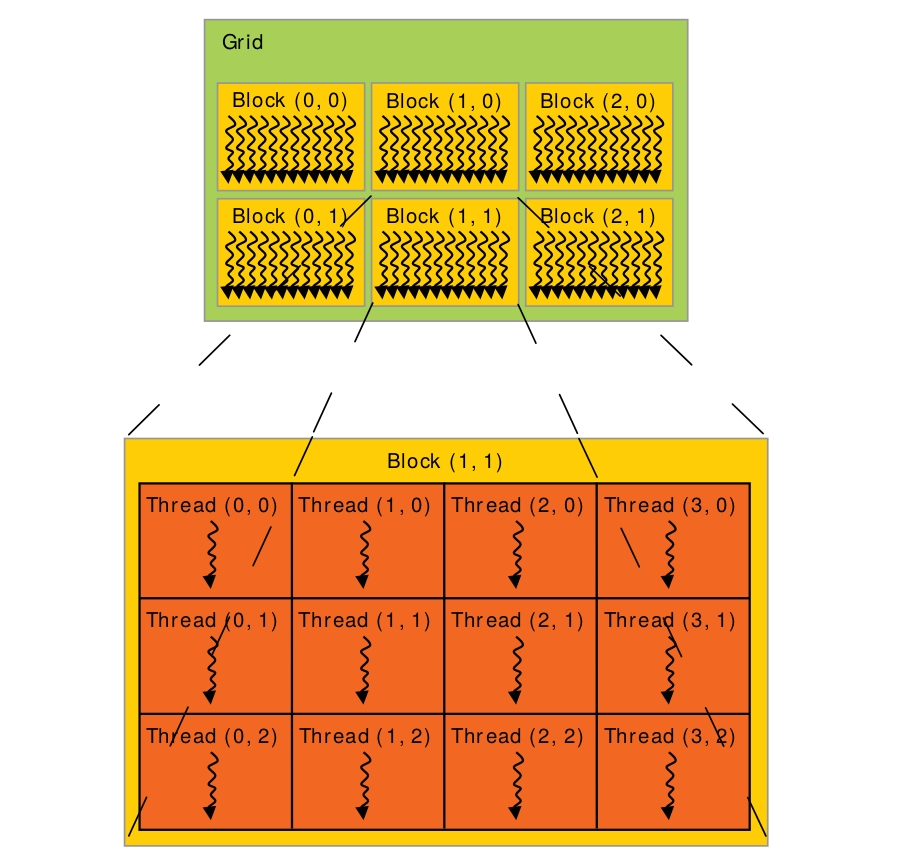
核函数中的一些内置变量:
gridDim: 线程格的尺寸。上图中,gridDim = (3, 2, 1)
blockIdx: 线程块的索引值。上图中,Block(1, 1)的索引值blockIdx = (1, 1, 1)
blockDim: 线程块的尺寸。上图中,blockDim = (4, 3, 1)
threadIdx: 线程索引值。上图中,Thread(1, 1)的索引值threadIdx = (1, 1, 1)
代码如下:
void main(){
int a;
}
__global__ void MatAdd(float** A, float** B, float** C, int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C, N);
...
}
流的并行处理:
cudaStream_t stream[5];
for(int i = 0; i<5; i++)
{
cudaStreamCreate(&stream[i]); //创建流
}
// Launch a kernel on the GPU with one thread for each element.
for(int i = 0; i<5; i++)
{
addKernel<<<1, 1, 0, stream[i]>>>(dev_c+i, dev_a+i, dev_b+i); //执行流
}
cudaDeviceSynchronize();
for(int i = 0;i<5;i++)
{
cudaStreamDestroy(stream[i]); //销毁流
}
进行规约(Reduction)的代码:
int i = blockDim.x / 2;
cacheIndex = threadIdx.x;
while (i != 0){
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
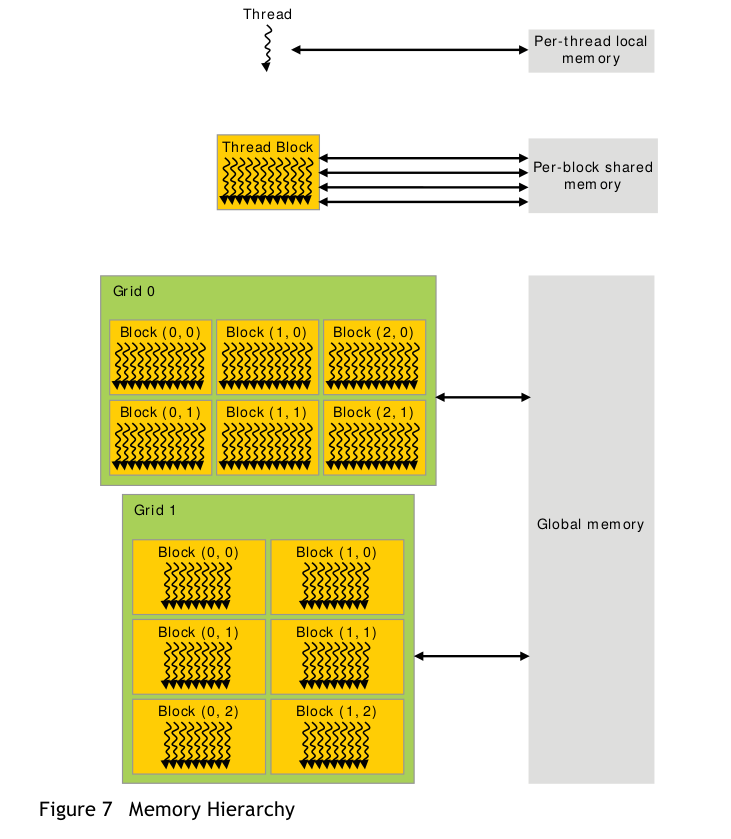
3. Memory
**register: ** 线程私有,有缓存,比较快。
**local memory: ** 线程私有,无缓存。
**shared memory: ** block内线程共享,速度较快。
**global memory: ** 线程共享,较慢。
**constant memory: ** 只读,常量存储,线程共享,有缓存。
**texture memory: ** 只读,具有纹理缓存。
4. cuda-gdb
编译时需要加上调试选项:
nvcc -g -G test.cu -o test
cuda-gdb的使用和gdb很多是一样的,列出一些cuda特有的命令:
thread: 列出当前的主机线程
cuda thread: 显示当前活跃的GPU线程
Note
- 如果核函数访问内存出现问题,因为GPU有着完善的内存管理机制,会强行结束所有违反内存访问规则的进程,后面的代码也就不会执行。