使用Docker-compose实现Tomcat+Nginx负载均衡
-
-
理解nginx反向代理原理
反向代理(Reverse Proxy)方式是指以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器;并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。

-
nginx代理tomcat集群
下载tomcat
sudo docker pull tomcat目录结构
配置文件
default.conf
upstream tomcat_client{ server t01:8080; server t02:8080; server t03:8080; } server { server_name localhost; listen 2504; location / { proxy_pass http://tomcat_client; } }docker-compose.yml
version: "3" services: tomcat001: image: tomcat:8.5.0 ports: - "8081:8080" restart: "always" container_name: tomcat001 volumes: - ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录 tomcat002: image: tomcat:8.5.0 ports: - "8082:8080" container_name: tomcat002 restart: "always" volumes: - ./tomcat2:/usr/local/tomcat/webapps/ROOT tomcat003: image: tomcat:8.5.0 ports: - "8083:8080" container_name: tomcat003 restart: "always" volumes: - ./tomcat3:/usr/local/tomcat/webapps/ROOT nginx: image: nginx volumes: - ./nginx/default.conf:/etc/nginx/conf.d/default.conf ports: - "80:2504" container_name: ngx_lr links: - tomcat001:t01 - tomcat002:t02 - tomcat003:t03启动docker-compose之前日常
service apache2 stop关闭占用端口80的apache2启动docker-compose
sudo docker-compose up -d查看容器
sudo docker ps -a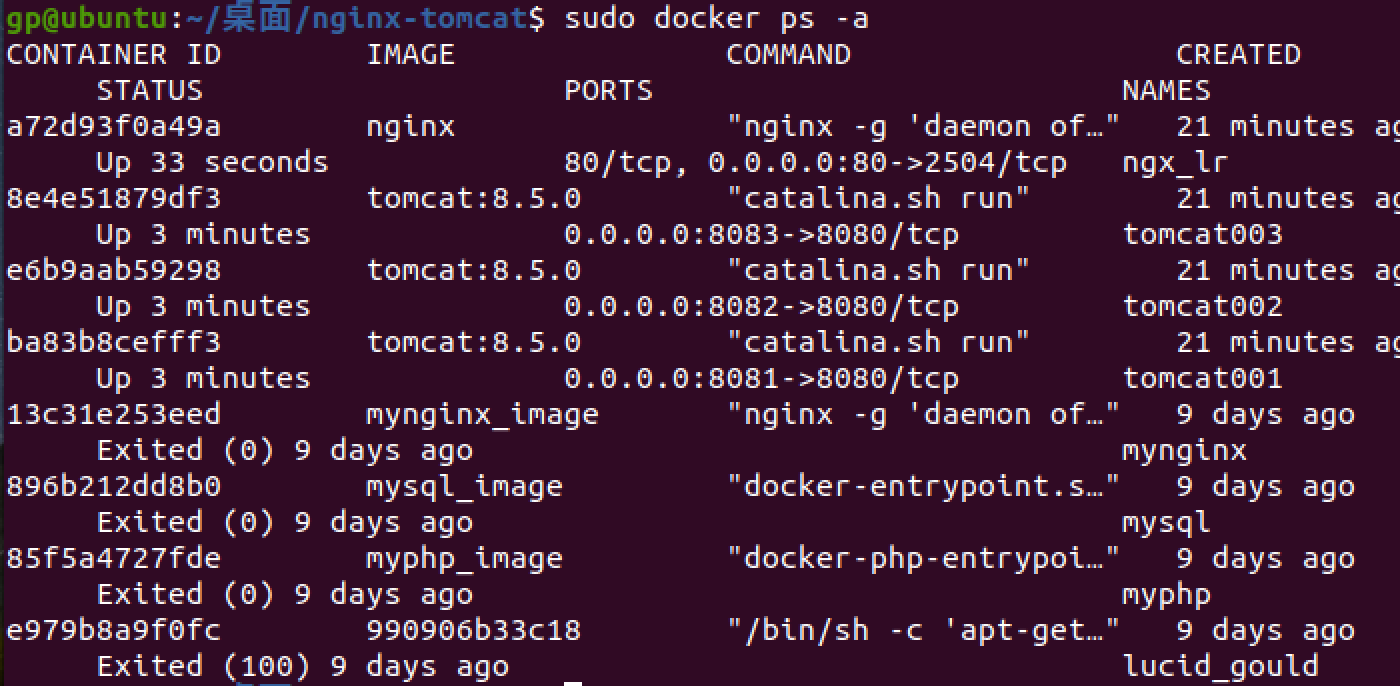
访问localhost



-
检查负载均衡
-
轮询

-
权重
在轮询的基础上指定轮询概率(weight),访问与权重成正比
upstream tomcats_client { server t01:8080 weight=1; server t02:8080 weight=2; server t03:8080 weight=3; }
-
-
使用Docker-compose部署javaweb运行环境
使用参考的教程
目录结构
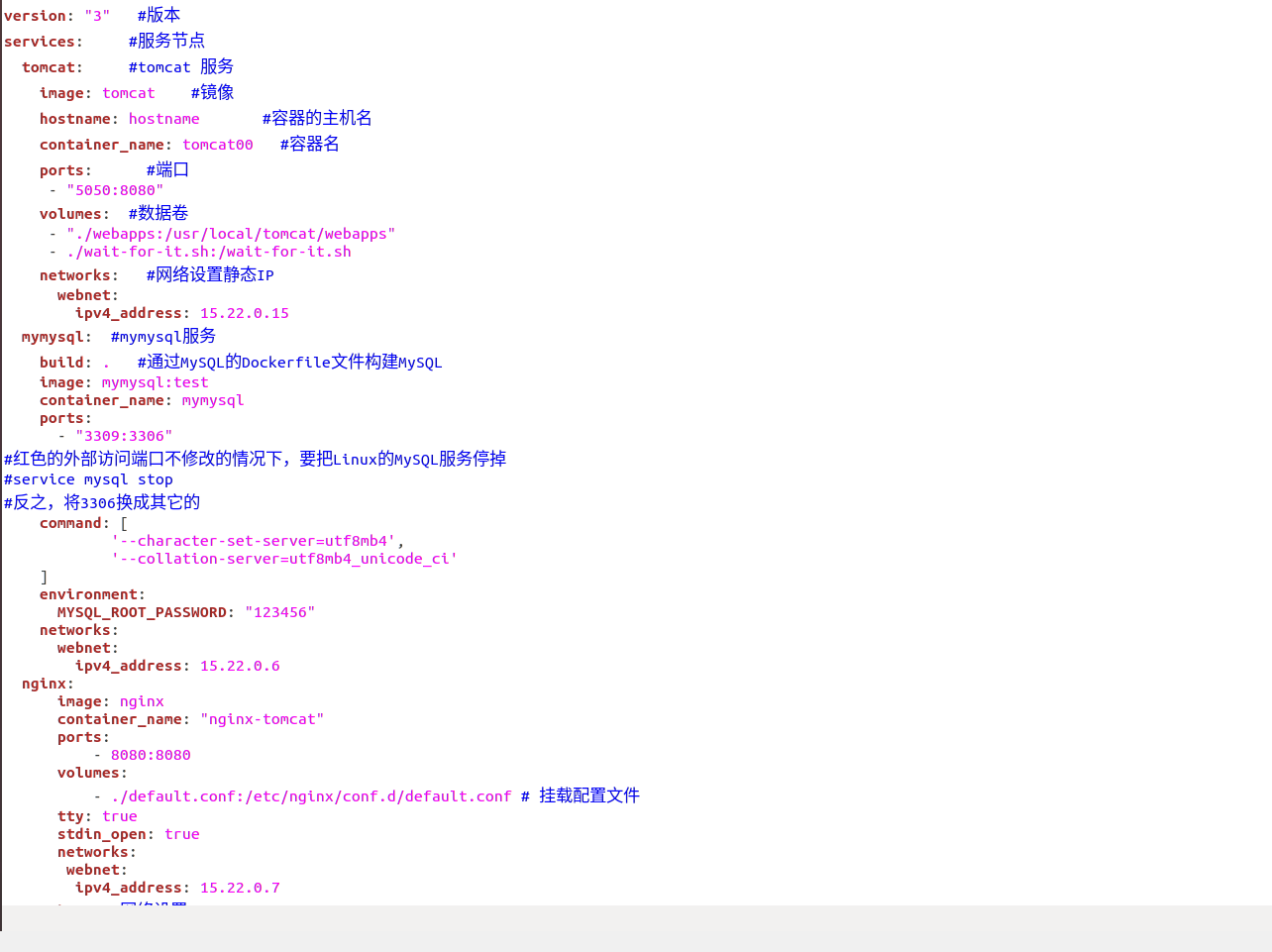
docker-compose.yml
default.conf
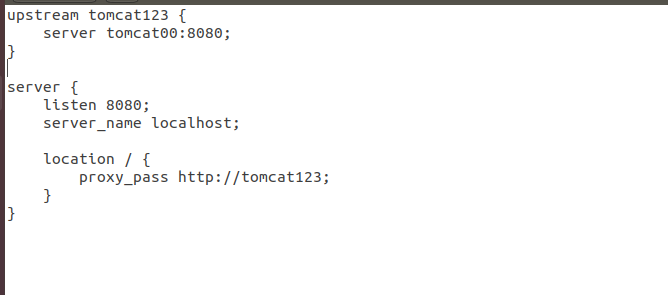
jdbc.properties

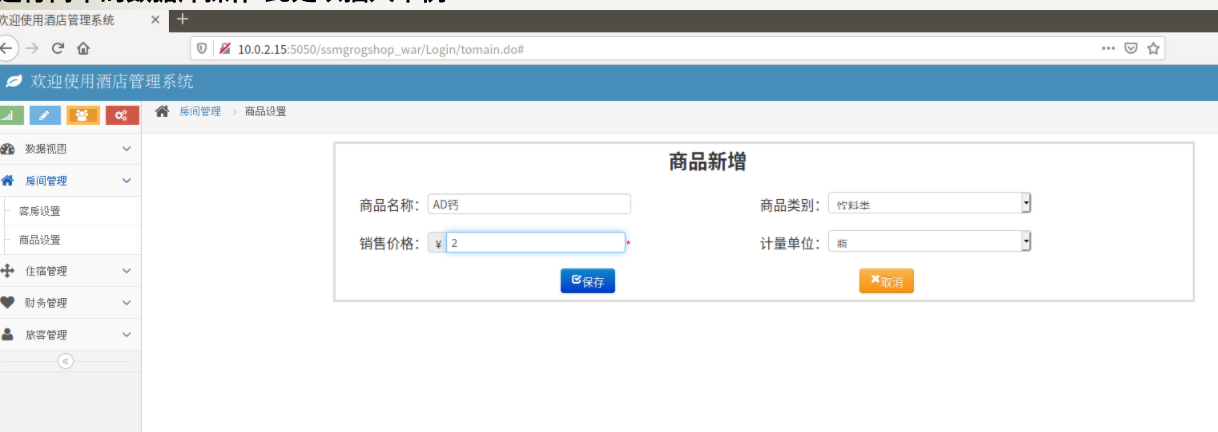
运行后进入http://10.0.2.15:5050/ssmgrogshop_war

进行简单的数据库操作
###使用Docker搭建大数据集群环境
-
pull ubuntu 镜像
sudo docker pull ubuntu dokcer images #查看镜像 cd ~ mkdir build sudo docker run -it -v /home/hadoop/build:/root/build --name ubuntu ubuntu -
容器初始化
安装必要工具:
sudo apt-get update sudo apt-get install vim安装sshd
sudo apt-get install ssh开启sshd服务器,将命令写入~/.bashrc最后一行实现登录自启
/etc/init.d/ssh start配置ssh无密码连接本地服务
ssh-keygen -t rsa #一直按回车键即可 cat id_dsa.pub >> authorized_keys安装jdk
直接从官方或其他途径下载java jdk压缩包解压或者使用指令
sudo apt-get install default-jdk直接安装(用时较长);在文件~/.bashrc添加 JAVA_HOME、PATH配置;
通过指令
source ~/.bashrc生效;通过java -version检查配置是否成功保存镜像文件
-
在Docker内部的容器做的修改是不会自动保存到镜像的。因此我们需要保存当前的配置;为了达到复用配置信息,我们在每个步骤完成之后,都保存成一个新的镜像,然后开启保存的新镜像即可
保存到镜像
sudo docker commint 容器id [name] -
安装hadoop
开启保存的ubuntu/jdkinstalled镜像
docker run -it -v /home/hadoop/build:/root/build --name ubuntu-jdkinstalled ubuntu/jdkinstalled把hadoop压缩包放在共享文件夹/home/hadoop/build下面
安装hadoop
docker cp ./build/hadoop-3.1.3.tar.gz 容器ID:/root/build cd /root/build tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local vim ~/.bashrc #添加 export HADOOP_HOME=/usr/local/hadoop-3.1.3 export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin source ~/.bashrc # 使.bashrc生效 hadoop version #检测hadoop安装成功 -
配置hadoop集群
进入配置目录
cd /usr/local/hadoop-3.1.3/etc/hadoophadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ # 在任意位置添加core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value> </property> </configuration>yarn-site.xml
<?xml version="1.0" ?> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <!--虚拟内存和物理内存比,不加这个模块程序可能跑不起来--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.5</value> </property> </configuration>进入脚本目录
cd /usr/local/hadoop-3.1.3/sbin
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root对于start-yarn.sh和stop-yarn.sh,添加下列参数
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root构建镜像
docker commit 容器ID ubuntu/hadoop利用构建好的镜像运行主机
# 第一个终端 docker run -it -h master --name master ubuntu/hadoop # 第二个终端 docker run -it -h slave01 --name slave01 ubuntu/hadoop # 第三个终端 docker run -it -h slave02 --name slave02 ubuntu/hadoop


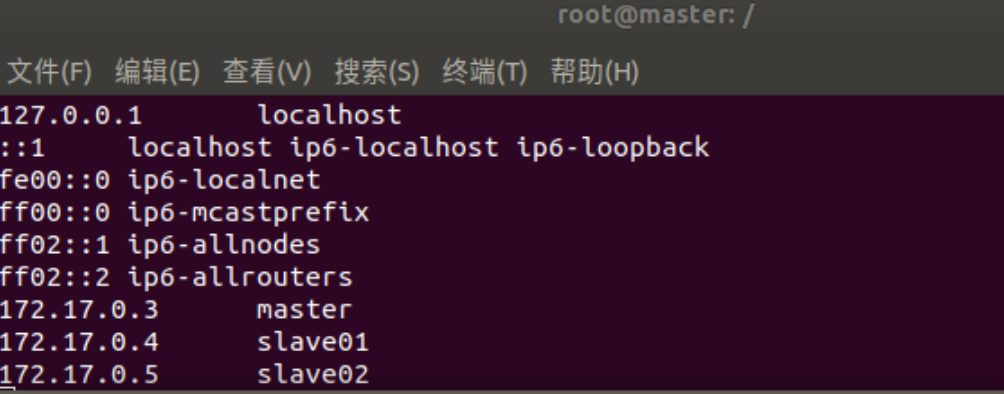
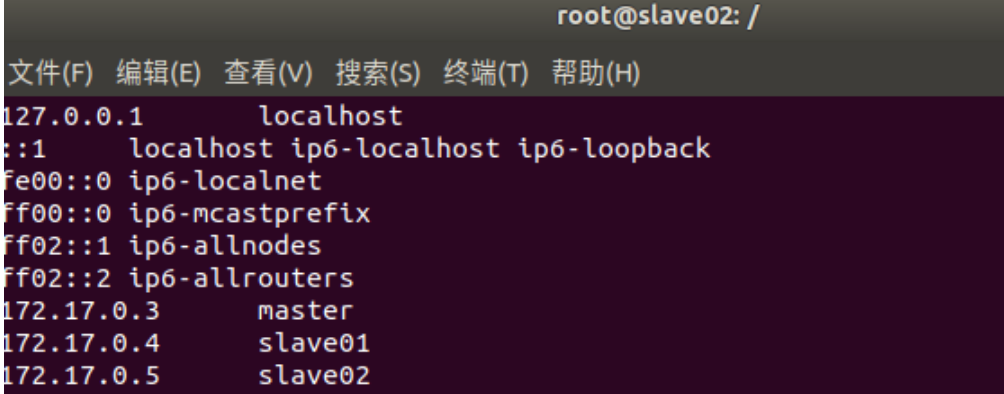
三个终端分别打开/etc/hosts,根据各自ip修改为如下形式
172.17.0.3 master 172.17.0.4 slave01 172.17.0.5 slave02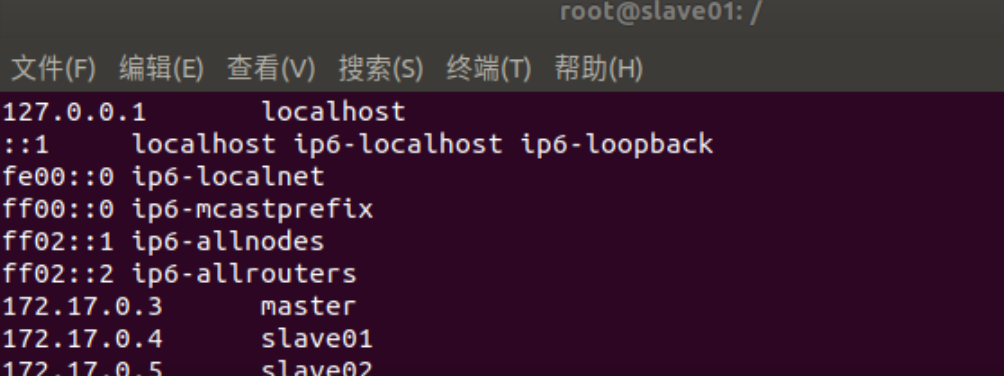
在master结点测试ssh;连接到slave结点
ssh slave01 ssh slave02 exit #退出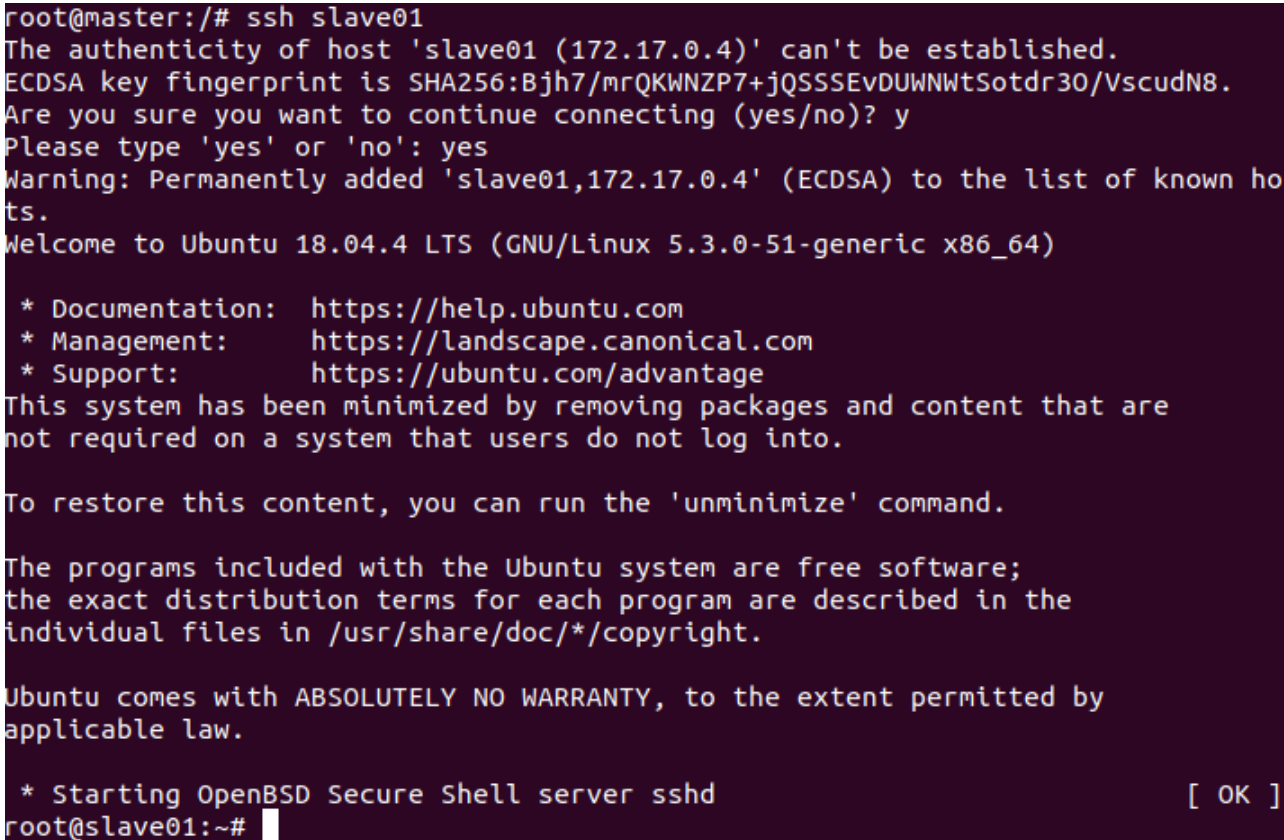
master主机上修改workers
vim /usr/local/hadoop-3.1.3/etc/hadoop/workersslave01 slave02测试Hadoop集群
#在master上操作 cd /usr/local/hadoop-3.1.3 bin/hdfs namenode -format #首次启动Hadoop需要格式化 sbin/start-all.sh #启动所有服务 jps #分别查看三个终端 
...
...运行Hadoop实例程序
bin/hdfs dfs -mkdir -p /user/hadoop/input bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input bin/hdfs dfs -ls /user/hadoop/input执行实例并查看运行结果
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep /user/hadoop/input output 'dfs[a-z.]+' bin/hdfs dfs -cat output/*
-
总结
这次实验量较大,做的比较崎岖,尤其最后一个实验,前前后后大概花了12个小时左右,从中碰到很多问题,也解决了很多问题,收获了很多。
第一个实验相对比较顺利,第二个实验用了老师的参考程序大体上也没碰到什么问题。最后一个实验相对量比较大,好在有之间昨晚的同学的参考,加上大数据实践课上学习,相对之前几次实践少踩了些坑。