Netflix 个性化推荐核心:排序
很多监督学习方法都能被用来设计排序模型:
Logistic 回归,
支持向量机(SVM),
神经网络
决策树类的算法(GBDT)。
另一方面,近几年来许多算法被应用到“Learn to rank(排序学习)”中,比如 RankSVM 和 RankBoost
个性化推荐用到的的机器学习算法:
线性回归(Linear Regression)
逻辑斯特回归(Logistic Regression)
弹性网络(Elastic Nets)
奇异值分解(SVD : Singular Value Decomposition)
RBM(Restricted Boltzmann Machines)
马尔科夫链(Markov Chains)
LDA(Latent Dirichlet Allocation)
关联规则(Association Rules)
GBDT(Gradient Boosted Decision Trees)
随机森林(Random Forests)
聚类方法,从最简单的k-means到图模型,例如Affinity Propagation
矩阵分解(Matrix Factorization)
消费者法则:
以数据驱动的方式来组织产品,通过创新让用户获得便利,新文化要求我们能够高效地通过实验来实践我们的想法。
消费者法则的执行:
1. 提出假设。(离线测试(机器学习算法验证优化算法,相关指标评价))2. 设计实验。(设计A/B 测试)3. 执行测试。4. 让数据说话
如何把我们的机器学习算法整合到 Netflix 以数据为驱动的 A/B 测试文化中。我们的做法是结合离线-在线测试:
在线测试之前,我们会进行离线测试,先优化并检验我们的算法。评测算法的指标:‘
采用了机器学习领域的很多种指标:排序指标(NDGC(Normalized Discounted Cumulative
Gain)、Mean Reciprocal Rank、Fraction of Concordant
Pairs)分类指标(精准度、查准率、查全率、F-score), Netflix:RMSE(均方根误差)和其他一些独特的指标如:多样性指标。
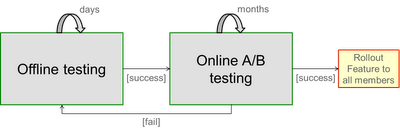
一旦离线测试验证了一个假设,我们就准备设计和发布 A/B 测试,从用户的视角证明新的特征的有效性。如果这一步通过了,我们便将其加入到我们的主要系统中,为我们的用户提供服务。跟踪比较这些离线指标和线上效果的吻合程度,发现它们并不是完全一致的。因此,离线指标只能作为最终决定的参考。
整个创新周期:
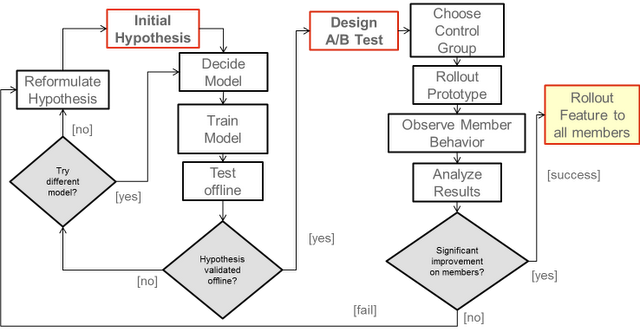
ref:http://blog.csdn.net/bornhe/article/details/8222497