任务一:26个英文字母不分大小统计个数
代码:
package analyse_word;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.text.DecimalFormat;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.text.DecimalFormat;
public class English_letter {
public static void main(String args[]) {
DecimalFormat df = new DecimalFormat("0.00%");
try {
char shu[] = new char[100000];
char zimu[] = new char[52];
int j = 0;
long count[] = new long [52];
String pathname = "D:\Englis_letter.txt";
File filename = new File(pathname);
InputStreamReader reader = new InputStreamReader(new FileInputStream(filename));
BufferedReader br = new BufferedReader(reader);
String line[] = new String[100000];
;
for (int i = 0; i < line.length; i++) {
line[i] = br.readLine();
}
br.close();
int k = 0;
while (line[k] != null) {
for (int i = 0; i < line[k].length(); i++) {
shu[j] = line[k].charAt(i);
j++;
}
k++;
}
for (int i = 0; i < shu.length; i++) {
switch (shu[i]) {
case 'a':
zimu[0] = 'a';
count[0]++;
break;
case 'b':
zimu[1] = 'b';
count[1]++;
break;
case 'c':
zimu[2] = 'c';
count[2]++;
break;
case 'd':
zimu[3] = 'd';
count[3]++;
break;
case 'e':
zimu[4] = 'e';
count[4]++;
break;
case 'f':
zimu[5] = 'f';
count[5]++;
break;
case 'g':
zimu[6] = 'g';
count[6]++;
break;
case 'h':
zimu[7] = 'h';
count[7]++;
break;
case 'i':
zimu[8] = 'i';
count[8]++;
break;
case 'j':
zimu[9] = 'j';
count[9]++;
break;
case 'k':
zimu[10] = 'k';
count[10]++;
break;
case 'l':
zimu[11] = 'l';
count[11]++;
break;
case 'm':
zimu[12] = 'm';
count[12]++;
break;
case 'n':
zimu[13] = 'n';
count[13]++;
break;
case 'o':
zimu[14] = 'o';
count[14]++;
break;
case 'p':
zimu[15] = 'p';
count[15]++;
break;
case 'q':
zimu[16] = 'q';
count[16]++;
break;
case 'r':
zimu[17] = 'r';
count[17]++;
break;
case 's':
zimu[18] = 's';
count[18]++;
break;
case 't':
zimu[19] = 't';
count[19]++;
break;
case 'u':
zimu[20] = 'u';
count[20]++;
break;
case 'v':
zimu[21] = 'v';
count[21]++;
break;
case 'w':
zimu[22] = 'w';
count[22]++;
break;
case 'x':
zimu[23] = 'x';
count[23]++;
break;
case 'y':
zimu[24] = 'y';
count[24]++;
break;
case 'z':
zimu[25] = 'z';
count[25]++;
break;
case 'A':
zimu[26] = 'A';
count[26]++;
break;
case 'B':
zimu[27] = 'B';
count[27]++;
break;
case 'C':
zimu[28] = 'C';
count[28]++;
break;
case 'D':
zimu[29] = 'D';
count[29]++;
break;
case 'E':
zimu[30] = 'E';
count[30]++;
break;
case 'F':
zimu[31] = 'F';
count[31]++;
break;
case 'G':
zimu[32] = 'G';
count[32]++;
break;
case 'H':
zimu[33] = 'H';
count[33]++;
break;
case 'I':
zimu[34] = 'I';
count[34]++;
break;
case 'J':
zimu[35] = 'G';
count[35]++;
break;
case 'K':
zimu[36] = 'K';
count[36]++;
break;
case 'L':
zimu[37] = 'L';
count[37]++;
break;
case 'M':
zimu[38] = 'M';
count[38]++;
break;
case 'N':
zimu[39] = 'N';
count[39]++;
break;
case 'O':
zimu[40] = 'O';
count[40]++;
break;
case 'P':
zimu[41] = 'P';
count[41]++;
break;
case 'Q':
zimu[42] = 'Q';
count[42]++;
break;
case 'R':
zimu[43] = 'R';
count[43]++;
break;
case 'S':
zimu[44] = 'S';
count[44]++;
break;
case 'T':
zimu[45] = 'T';
count[45]++;
break;
case 'U':
zimu[46] = 'U';
count[46]++;
break;
case 'V':
zimu[47] = 'V';
count[47]++;
break;
case 'W':
zimu[48] = 'W';
count[48]++;
break;
case 'X':
zimu[49] = 'X';
count[49]++;
break;
case 'Y':
zimu[50] = 'Y';
count[50]++;
break;
case 'Z':
zimu[51] = 'Z';
count[51]++;
}
}
int ci = 0;
int sum = 0;
System.out.println("短文中各字母出现情况统计如下:");
for (int i = 0; i < 26; i++) {
count[i]+=count[i+26];
if (count[i] != 0) {
ci++;
sum += count[i];
System.out.println(ci + ".字母" + zimu[i] + "的出现次数是:" + count[i]);
}
}
for (int i = 0; i < 26; i++) {
System.out.println(zimu[i]+"出现的百分比为:"+df.format(count[i]*1.0/sum));
}
System.out.println("字母共计:" + sum + "个");
} catch (Exception e) {
e.printStackTrace();
}
}
DecimalFormat df = new DecimalFormat("0.00%");
try {
char shu[] = new char[100000];
char zimu[] = new char[52];
int j = 0;
long count[] = new long [52];
String pathname = "D:\Englis_letter.txt";
File filename = new File(pathname);
InputStreamReader reader = new InputStreamReader(new FileInputStream(filename));
BufferedReader br = new BufferedReader(reader);
String line[] = new String[100000];
;
for (int i = 0; i < line.length; i++) {
line[i] = br.readLine();
}
br.close();
int k = 0;
while (line[k] != null) {
for (int i = 0; i < line[k].length(); i++) {
shu[j] = line[k].charAt(i);
j++;
}
k++;
}
for (int i = 0; i < shu.length; i++) {
switch (shu[i]) {
case 'a':
zimu[0] = 'a';
count[0]++;
break;
case 'b':
zimu[1] = 'b';
count[1]++;
break;
case 'c':
zimu[2] = 'c';
count[2]++;
break;
case 'd':
zimu[3] = 'd';
count[3]++;
break;
case 'e':
zimu[4] = 'e';
count[4]++;
break;
case 'f':
zimu[5] = 'f';
count[5]++;
break;
case 'g':
zimu[6] = 'g';
count[6]++;
break;
case 'h':
zimu[7] = 'h';
count[7]++;
break;
case 'i':
zimu[8] = 'i';
count[8]++;
break;
case 'j':
zimu[9] = 'j';
count[9]++;
break;
case 'k':
zimu[10] = 'k';
count[10]++;
break;
case 'l':
zimu[11] = 'l';
count[11]++;
break;
case 'm':
zimu[12] = 'm';
count[12]++;
break;
case 'n':
zimu[13] = 'n';
count[13]++;
break;
case 'o':
zimu[14] = 'o';
count[14]++;
break;
case 'p':
zimu[15] = 'p';
count[15]++;
break;
case 'q':
zimu[16] = 'q';
count[16]++;
break;
case 'r':
zimu[17] = 'r';
count[17]++;
break;
case 's':
zimu[18] = 's';
count[18]++;
break;
case 't':
zimu[19] = 't';
count[19]++;
break;
case 'u':
zimu[20] = 'u';
count[20]++;
break;
case 'v':
zimu[21] = 'v';
count[21]++;
break;
case 'w':
zimu[22] = 'w';
count[22]++;
break;
case 'x':
zimu[23] = 'x';
count[23]++;
break;
case 'y':
zimu[24] = 'y';
count[24]++;
break;
case 'z':
zimu[25] = 'z';
count[25]++;
break;
case 'A':
zimu[26] = 'A';
count[26]++;
break;
case 'B':
zimu[27] = 'B';
count[27]++;
break;
case 'C':
zimu[28] = 'C';
count[28]++;
break;
case 'D':
zimu[29] = 'D';
count[29]++;
break;
case 'E':
zimu[30] = 'E';
count[30]++;
break;
case 'F':
zimu[31] = 'F';
count[31]++;
break;
case 'G':
zimu[32] = 'G';
count[32]++;
break;
case 'H':
zimu[33] = 'H';
count[33]++;
break;
case 'I':
zimu[34] = 'I';
count[34]++;
break;
case 'J':
zimu[35] = 'G';
count[35]++;
break;
case 'K':
zimu[36] = 'K';
count[36]++;
break;
case 'L':
zimu[37] = 'L';
count[37]++;
break;
case 'M':
zimu[38] = 'M';
count[38]++;
break;
case 'N':
zimu[39] = 'N';
count[39]++;
break;
case 'O':
zimu[40] = 'O';
count[40]++;
break;
case 'P':
zimu[41] = 'P';
count[41]++;
break;
case 'Q':
zimu[42] = 'Q';
count[42]++;
break;
case 'R':
zimu[43] = 'R';
count[43]++;
break;
case 'S':
zimu[44] = 'S';
count[44]++;
break;
case 'T':
zimu[45] = 'T';
count[45]++;
break;
case 'U':
zimu[46] = 'U';
count[46]++;
break;
case 'V':
zimu[47] = 'V';
count[47]++;
break;
case 'W':
zimu[48] = 'W';
count[48]++;
break;
case 'X':
zimu[49] = 'X';
count[49]++;
break;
case 'Y':
zimu[50] = 'Y';
count[50]++;
break;
case 'Z':
zimu[51] = 'Z';
count[51]++;
}
}
int ci = 0;
int sum = 0;
System.out.println("短文中各字母出现情况统计如下:");
for (int i = 0; i < 26; i++) {
count[i]+=count[i+26];
if (count[i] != 0) {
ci++;
sum += count[i];
System.out.println(ci + ".字母" + zimu[i] + "的出现次数是:" + count[i]);
}
}
for (int i = 0; i < 26; i++) {
System.out.println(zimu[i]+"出现的百分比为:"+df.format(count[i]*1.0/sum));
}
System.out.println("字母共计:" + sum + "个");
} catch (Exception e) {
e.printStackTrace();
}
}
}
截图:

任务二:统计单词出现的次数并在控制台设置输出前多少个频率最高的单词,“the,a”等无用字符不出现
package analyse_word;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
public class English_word {
public static void main(String[] args) throws FileNotFoundException {
File file = new File("D:\Englis_letter.txt");// 读取文件
String words[] = new String [100000];
int out_words[] = new int [100000];
if (!file.exists()) {// 如果文件打不开或不存在则提示错误
System.out.println("文件不存在");
return;
}
Scanner x = new Scanner(file);
HashMap<String, Integer> hashMap = new HashMap<String, Integer>();
while (x.hasNextLine()) {
String line = x.nextLine();
String[] lineWords = line.split("[\s+ ”“();,.?! ]");
Set<String> wordSet = hashMap.keySet();
for (int i = 0; i < lineWords.length; i++) {
if (wordSet.contains(lineWords[i])) {
Integer number = hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
} else {
hashMap.put(lineWords[i], 1);
}
}
}
Iterator<String> iterator = hashMap.keySet().iterator();
int max = 0,i=0;
while (iterator.hasNext()) {
String word = iterator.next();
if(!"".equals(word)&&word!=null&&!"a".equals(word)&&!"the".equals(word)&&!" ".equals(word)) {
System.out.println(word);
words[i]=word;
out_words[i]=hashMap.get(word);
i++;
}
}
int change=0;
String change_word=null;
for(int j=0;j<=i;j++)
{
for(int k=j;k<=i;k++)
{
if(out_words[k]>out_words[j])
{
change=out_words[j];
change_word=words[j];
out_words[j]=out_words[k];
words[j]=words[k];
out_words[k]=change;
words[k]=change_word;
}
}
}
Scanner scan = new Scanner(System.in);
int ms = scan.nextInt();
for(int j=0;j<ms;j++)
{
System.out.println(words[j]+" 出现次数:"+out_words[j]);
}
}
}
public static void main(String[] args) throws FileNotFoundException {
File file = new File("D:\Englis_letter.txt");// 读取文件
String words[] = new String [100000];
int out_words[] = new int [100000];
if (!file.exists()) {// 如果文件打不开或不存在则提示错误
System.out.println("文件不存在");
return;
}
Scanner x = new Scanner(file);
HashMap<String, Integer> hashMap = new HashMap<String, Integer>();
while (x.hasNextLine()) {
String line = x.nextLine();
String[] lineWords = line.split("[\s+ ”“();,.?! ]");
Set<String> wordSet = hashMap.keySet();
for (int i = 0; i < lineWords.length; i++) {
if (wordSet.contains(lineWords[i])) {
Integer number = hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
} else {
hashMap.put(lineWords[i], 1);
}
}
}
Iterator<String> iterator = hashMap.keySet().iterator();
int max = 0,i=0;
while (iterator.hasNext()) {
String word = iterator.next();
if(!"".equals(word)&&word!=null&&!"a".equals(word)&&!"the".equals(word)&&!" ".equals(word)) {
System.out.println(word);
words[i]=word;
out_words[i]=hashMap.get(word);
i++;
}
}
int change=0;
String change_word=null;
for(int j=0;j<=i;j++)
{
for(int k=j;k<=i;k++)
{
if(out_words[k]>out_words[j])
{
change=out_words[j];
change_word=words[j];
out_words[j]=out_words[k];
words[j]=words[k];
out_words[k]=change;
words[k]=change_word;
}
}
}
Scanner scan = new Scanner(System.in);
int ms = scan.nextInt();
for(int j=0;j<ms;j++)
{
System.out.println(words[j]+" 出现次数:"+out_words[j]);
}
}
}

任务三:遍历目录下所有.txt文本并按任务二要求进行统计
package analyse_word;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
public class test {
static String words[] = new String [100000];
static int out_words[] = new int [100000];
static int i=0;
static HashMap<String, Integer> hashMap = new HashMap<String, Integer>();
public static void English_words(File ms) throws FileNotFoundException {
File file = new File(ms.toString());// 读取文件
if (!file.exists()) {// 如果文件打不开或不存在则提示错误
System.out.println("文件不存在");
return;
}
Scanner x = new Scanner(file);
while (x.hasNextLine()) {
String line = x.nextLine();
String[] lineWords = line.split("[\s+ ”“();,.?! ]");
Set<String> wordSet = hashMap.keySet();
for (int i = 0; i < lineWords.length; i++) {
if (wordSet.contains(lineWords[i])) {
Integer number = hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
} else {
hashMap.put(lineWords[i], 1);
}
}
}
}
public static void main(String[] args) throws FileNotFoundException {
String path = "d:/";
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
if (tempList[i].toString().endsWith("txt")) {
System.out.println("文 件:" + tempList[i]);
English_words(tempList[i]);
}
}
Iterator<String> iterator = hashMap.keySet().iterator();
int max = 0;
while (iterator.hasNext()) {
String word = iterator.next();
if(!"".equals(word)&&word!=null&&!"a".equals(word)&&!"the".equals(word)&&!" ".equals(word)) {
words[i]=word;
out_words[i]=hashMap.get(word);
i++;
}
}
int change=0;
String change_word=null;
for(int j=0;j<=i;j++)
{
for(int k=j;k<=i;k++)
{
if(out_words[k]>out_words[j])
{
change=out_words[j];
change_word=words[j];
out_words[j]=out_words[k];
words[j]=words[k];
out_words[k]=change;
words[k]=change_word;
}
}
}
Scanner scan = new Scanner(System.in);
int ms = scan.nextInt();
for(int j=0;j<ms;j++)
{
System.out.println(words[j]+" 出现次数:"+out_words[j]);
}
}
static String words[] = new String [100000];
static int out_words[] = new int [100000];
static int i=0;
static HashMap<String, Integer> hashMap = new HashMap<String, Integer>();
public static void English_words(File ms) throws FileNotFoundException {
File file = new File(ms.toString());// 读取文件
if (!file.exists()) {// 如果文件打不开或不存在则提示错误
System.out.println("文件不存在");
return;
}
Scanner x = new Scanner(file);
while (x.hasNextLine()) {
String line = x.nextLine();
String[] lineWords = line.split("[\s+ ”“();,.?! ]");
Set<String> wordSet = hashMap.keySet();
for (int i = 0; i < lineWords.length; i++) {
if (wordSet.contains(lineWords[i])) {
Integer number = hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
} else {
hashMap.put(lineWords[i], 1);
}
}
}
}
public static void main(String[] args) throws FileNotFoundException {
String path = "d:/";
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
if (tempList[i].toString().endsWith("txt")) {
System.out.println("文 件:" + tempList[i]);
English_words(tempList[i]);
}
}
Iterator<String> iterator = hashMap.keySet().iterator();
int max = 0;
while (iterator.hasNext()) {
String word = iterator.next();
if(!"".equals(word)&&word!=null&&!"a".equals(word)&&!"the".equals(word)&&!" ".equals(word)) {
words[i]=word;
out_words[i]=hashMap.get(word);
i++;
}
}
int change=0;
String change_word=null;
for(int j=0;j<=i;j++)
{
for(int k=j;k<=i;k++)
{
if(out_words[k]>out_words[j])
{
change=out_words[j];
change_word=words[j];
out_words[j]=out_words[k];
words[j]=words[k];
out_words[k]=change;
words[k]=change_word;
}
}
}
Scanner scan = new Scanner(System.in);
int ms = scan.nextInt();
for(int j=0;j<ms;j++)
{
System.out.println(words[j]+" 出现次数:"+out_words[j]);
}
}
}

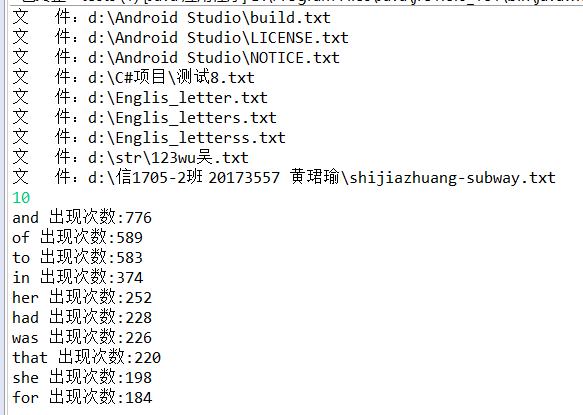
任务四:统计目录下的所有子.txt文件以及子目录下.txt文件
package analyse_word;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
public class tests {
static String words[] = new String [100000];
static int out_words[] = new int [100000];
static int i=0;
static HashMap<String, Integer> hashMap = new HashMap<String, Integer>();
public static void English_words(File ms) throws FileNotFoundException {
File file = new File(ms.toString());// 读取文件
if (!file.exists()) {// 如果文件打不开或不存在则提示错误
System.out.println("文件不存在");
return;
}
Scanner x = new Scanner(file);
while (x.hasNextLine()) {
String line = x.nextLine();
String[] lineWords = line.split("[\s+ ”“();,.?! ]");
Set<String> wordSet = hashMap.keySet();
for (int i = 0; i < lineWords.length; i++) {
if (wordSet.contains(lineWords[i])) {
Integer number = hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
} else {
hashMap.put(lineWords[i], 1);
}
}
}
}
public static void main(String[] args) throws FileNotFoundException {
String path = "d:/";
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
if (tempList[i].toString().endsWith("txt")) {
System.out.println("文 件:" + tempList[i]);
English_words(tempList[i]);
}
if (tempList[i].isDirectory()) {
File files = new File(tempList[i].toString() + "\");
File[] tempLists = files.listFiles();
if(tempLists!=null)
for (int j = 0; j < tempLists.length; j++) {
if (tempLists[j].toString().endsWith(".txt")) {
System.out.println("文 件:" + tempLists[j]);
English_words(tempLists[j]);
}
}
}
}
Iterator<String> iterator = hashMap.keySet().iterator();
int max = 0;
while (iterator.hasNext()) {
String word = iterator.next();
if(!"".equals(word)&&word!=null&&!"a".equals(word)&&!"the".equals(word)&&!" ".equals(word)) {
words[i]=word;
out_words[i]=hashMap.get(word);
i++;
}
}
int change=0;
String change_word=null;
for(int j=0;j<=i;j++)
{
for(int k=j;k<=i;k++)
{
if(out_words[k]>out_words[j])
{
change=out_words[j];
change_word=words[j];
out_words[j]=out_words[k];
words[j]=words[k];
out_words[k]=change;
words[k]=change_word;
}
}
}
Scanner scan = new Scanner(System.in);
int ms = scan.nextInt();
for(int j=0;j<ms;j++)
{
System.out.println(words[j]+" 出现次数:"+out_words[j]);
}
}
static String words[] = new String [100000];
static int out_words[] = new int [100000];
static int i=0;
static HashMap<String, Integer> hashMap = new HashMap<String, Integer>();
public static void English_words(File ms) throws FileNotFoundException {
File file = new File(ms.toString());// 读取文件
if (!file.exists()) {// 如果文件打不开或不存在则提示错误
System.out.println("文件不存在");
return;
}
Scanner x = new Scanner(file);
while (x.hasNextLine()) {
String line = x.nextLine();
String[] lineWords = line.split("[\s+ ”“();,.?! ]");
Set<String> wordSet = hashMap.keySet();
for (int i = 0; i < lineWords.length; i++) {
if (wordSet.contains(lineWords[i])) {
Integer number = hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
} else {
hashMap.put(lineWords[i], 1);
}
}
}
}
public static void main(String[] args) throws FileNotFoundException {
String path = "d:/";
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
if (tempList[i].toString().endsWith("txt")) {
System.out.println("文 件:" + tempList[i]);
English_words(tempList[i]);
}
if (tempList[i].isDirectory()) {
File files = new File(tempList[i].toString() + "\");
File[] tempLists = files.listFiles();
if(tempLists!=null)
for (int j = 0; j < tempLists.length; j++) {
if (tempLists[j].toString().endsWith(".txt")) {
System.out.println("文 件:" + tempLists[j]);
English_words(tempLists[j]);
}
}
}
}
Iterator<String> iterator = hashMap.keySet().iterator();
int max = 0;
while (iterator.hasNext()) {
String word = iterator.next();
if(!"".equals(word)&&word!=null&&!"a".equals(word)&&!"the".equals(word)&&!" ".equals(word)) {
words[i]=word;
out_words[i]=hashMap.get(word);
i++;
}
}
int change=0;
String change_word=null;
for(int j=0;j<=i;j++)
{
for(int k=j;k<=i;k++)
{
if(out_words[k]>out_words[j])
{
change=out_words[j];
change_word=words[j];
out_words[j]=out_words[k];
words[j]=words[k];
out_words[k]=change;
words[k]=change_word;
}
}
}
Scanner scan = new Scanner(System.in);
int ms = scan.nextInt();
for(int j=0;j<ms;j++)
{
System.out.println(words[j]+" 出现次数:"+out_words[j]);
}
}
}