关于缓存的使用,个人经验还是比较欠缺,对于缓存在应用系统中的使用也只是前几个月在公司实习的时候,简单的使用过,且使用的都是人家把框架搭建好的,至于缓存在并发情况下会产生的一系列问题都已经被框架处理好了,我所做的只是set和get,至于使用时缓存在并发情况下到底会出现什么样的问题,该如何去解决和避免这些问题,没有去深究。
秉着“学而时习之”的态度(T_T自己太懒,厚着脸皮),这两天在鼓捣redis,至于redis的基本使用还是挺简单的,今天要说的是我在这个过程中看到网上博客一直提的关于缓存使用的各种问题,看到好多前辈在高并发下使用缓存都踩了不少大坑,总结他人的经验也是给自己以后警醒。今天这篇博客只讲我对一个问题的理解与思路的想法,并不会去罗列缓存在各种场景下各种解决方案以及各种解决方案之间的优劣,我没有实际解决缓存问题的经验,不敢妄自下结论。以下是个人学习过程的记录,希望各路大侠交流学习。
场景描述:高并发情况缓存未命中从而访问数据库造成压力陡增崩溃
最终解决方案:java中利用读写锁处理并发并发情形
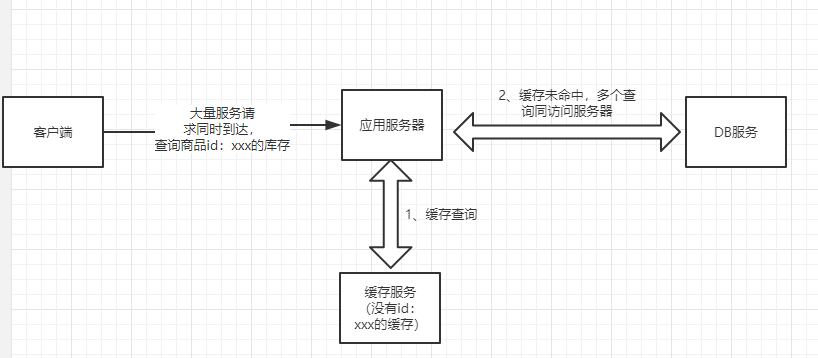
业务场景假设:现有一张商品库存表,业务请求需要根据商品id查询相应商品的库存情况,服务端收到请求返回对应商品的库存。
一、少量请求下缓存的简单使用
首先,我们知道使用缓存的基本流程,首先根据key查询缓存,查询成功直接返回,查询失败(缓存未命中),则查询数据库得到结果写入缓存再返回。根据前面的场景假设和缓存使用逻辑,请看下面的一段代码:
1 /** 2 * 根据商品id(也是主键)查询商品库存记录 3 */ 4 public GoodsStock selectByPrimaryKey(Integer id) { 5 GoodsStock result; 6 //缓存中查找 7 String goodsStockJsonStr = RedisCache.get(id); 8 9 //缓存中查找成功 10 if(!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 11 logger.info("=====query from cache====="); 12 return JSONObject.parseObject(goodsStockJsonStr,GoodsStock.class); 13 } 14 //没有命中缓存,数据库中查找,并将结果写入缓存 15 logger.info("=====query from DB====="); 16 result = goodsStockMapper.selectByPrimaryKey(id); 17 //查询结果写入缓存 18 RedisCache.set(id, JSONArray.toJSONString(result)); 19 return result; 20 }
以上代码运行结果,第一次运行缓存中参照失败是从数据库中查找,后面每次运行查找相同的id,都是从缓存中得到(这里咱先不讨论缓存的失效时间之类),只查询了数据库一次,由于每次运行都是单个请求,这段代码没有任何问题,现在在多线程下测试这个查询服务,看看会出现什么情况:
1 /** 2 * 10个线程并发调用服务 3 */ 4 @Test 5 public void testMultiThreadQuery() throws Exception{ 6 for(int i = 0; i < 10; i++) { 7 new Thread(new QueryTask()).start(); 8 countDownLatch.countDown(); //启动线程达到10个时,10个线程同时执行查询 9 } 10 Thread.sleep(5000); 11 } 12 13 private class QueryTask implements Runnable { 14 @Override 15 public void run() { 16 try { 17 countDownLatch.await(); 18 } catch (InterruptedException e) { 19 e.printStackTrace(); 20 } 21 GoodsStock goodsStock = goodsStockService.selectByPrimaryKey(GOODS_ID); 22 } 23 }
运行前我们先将缓存清空,让服务请求缓存是出现缓存未命中的情况,正常情况是只要有一个请求查询出现缓存未命中,那么就回去查询数据库,查询成功后将结果写入缓存,这样后续的请求再查询统一记录时,就应该直接从缓存返回,而不再去查询数据库。我们来看看运行结果,运行结果也在预料之中。
1918 [Thread-12] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-5] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-13] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-8] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-7] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-9] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-6] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-4] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-10] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 1918 [Thread-11] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB=====
我们可以看到,10个同时到达的请求基本上都是去查询的数据库,这点很好理解,因为10个请求同时到达,同时查询缓存,同时发现缓存没命中,同时去查数据库。在这种情况下,本来后面的请求应该读取缓存从而达到减轻数据库压力的效果,然而在前面这么多“同时”的情形下,缓存失去了它原有的效果。如果这里不只10个请求同时到达,而是在类似秒杀场景下同时有成千上万个请求到达,那么数据库肯定不能承受之重直至崩溃。这种场景就很类似于高并发情况下的缓存击穿(缓存击穿是指在高并发情况下,大量请求查询一个并不存在的数据,由于数据不存在,肯定会出现缓存不命中,然后去查询数据库,然后导致数据库崩溃。)
既然我们清楚得知道问题出现在同时查询数据库这里,那么很容易就想到利用锁机制,只让一个请求去查询数据库。
二、高并发情况下缓存使用
利用java提供的锁机制,让所有请求到达查询服务时,若缓存没有命中,就去竞争一把锁,得到锁的请求才去查询数据库,并将查询结果写回缓存,后面的请求就直接从缓存中读取,并发情况下改进代码如下:
1 /** 2 * 根据商品id(也是主键)查询商品库存记录 3 */ 4 public GoodsStock selectByPrimaryKey(Integer id) { 5 GoodsStock result; 6 //缓存中查找 7 String goodsStockJsonStr = RedisCache.get(id); 8 9 //缓存中查找成功 10 if(!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 11 logger.info("=====query from cache====="); 12 return JSONObject.parseObject(goodsStockJsonStr,GoodsStock.class); 13 } 14 //没有命中缓存,这里加锁去数据库中查找,并将结果写入缓存 15 //后续获得锁的线程会直接从缓存中读取,而不再是访问数据库 16 synchronized(this) { 17 goodsStockJsonStr = RedisCache.get(id); 18 if(!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 19 logger.info("=====query from cache====="); 20 return JSONObject.parseObject(goodsStockJsonStr,GoodsStock.class); 21 } 22 logger.info("=====query from DB====="); 23 result = goodsStockMapper.selectByPrimaryKey(id); 24 //查询结果写入缓存 25 RedisCache.set(id, JSONArray.toJSONString(result)); 26 } 27 return result; 28 }
这里,我们对缓存未命中查询数据库的部分进行加锁进行同步处理,同步代码块中再查询了一次缓存,这样就保证了同时到达但未获得锁的线程后面会直接读取缓存中的数据而不再访问数据库。从而大量减少了同一时刻对数据库的访问量。
我们看看运行结果,可以发现,只有第一次查询是从数据库中查询,后续查询全来自缓存:
1 1907 [Thread-11] INFO g.s.impl.GoodsStockServiceImpl - =====query from DB===== 2 2550 [Thread-12] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 3 2578 [Thread-8] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 4 2579 [Thread-7] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 5 2580 [Thread-10] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 6 2581 [Thread-13] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 7 2581 [Thread-5] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 8 2581 [Thread-4] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 9 2582 [Thread-6] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache===== 10 2582 [Thread-9] INFO g.s.impl.GoodsStockServiceImpl - =====query from cache=====
至此,上面提到的在并发的情况查询缓存的问题基本上可以解决,但是我们都知道,在java中sychronized属于重量级锁,读写锁更适合这样的场景。
三、高并发情况下缓存使用,利用读写锁提高效率
这个地方为甚么加上读写锁的性能就更高些,这里涉及到java中的锁机制问题,就不展开写,待后面研究清楚再另外单独记录。
1 /** 2 * 根据商品id(也是主键)查询商品库存记录 3 */ 4 public GoodsStock selectByPrimaryKey(Integer id) { 5 GoodsStock result; 6 readWriteLock.readLock().lock();//添加读锁 7 try { 8 //缓存中查找 9 String goodsStockJsonStr = RedisCache.get(id); 10 //缓存中查找成功 11 if (!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 12 logger.info("=====query from cache====="); 13 result = JSONObject.parseObject(goodsStockJsonStr, GoodsStock.class); 14 } else { 15 //若缓存读取失败,则需要去数据库中查询 16 readWriteLock.readLock().unlock();//释放读锁 17 readWriteLock.writeLock().lock();//添加写锁 18 try { 19 goodsStockJsonStr = RedisCache.get(id); 20 if (!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 21 logger.info("=====query from cache====="); 22 return JSONObject.parseObject(goodsStockJsonStr, GoodsStock.class); 23 } 24 logger.info("=====query from DB====="); 25 result = goodsStockMapper.selectByPrimaryKey(id); 26 //查询结果写入缓存 27 RedisCache.set(id, JSONArray.toJSONString(result)); 28 } finally { 29 readWriteLock.writeLock().unlock(); 30 readWriteLock.readLock().lock(); 31 } 32 } 33 } finally { 34 readWriteLock.readLock().unlock(); 35 } 36 return result; 37 }
这个地方补充一下,从上面的代码我们可以看到,其实整个查询方法,主要的业务代码只有一行:
1 result = goodsStockMapper.selectByPrimaryKey(id);
剩余的其他代码都是无关于业务的其他处理,我们在业务中应该尽量将非业务的代码抽离出来包装,使真正的业务代码简单高效。对于类似以上这种场景,我们可以使用模板方法,在此简单补充一下:
查询业务的模板方法:
1 /** 2 * 并发处理的缓存查询模板方法 3 * @param queryKey 查询键值 4 * @param expire 缓存过期时间 5 * @param unit 时间单位 6 * @param typeReference 传入泛型类型的类对象 7 * @param cacheLoadable 业务回调类 8 * @param <T> 9 * @return 10 */ 11 public <T> T queryByCache(String queryKey, long expire, TimeUnit unit, 12 TypeReference<T> typeReference, CacheLoadable<T> cacheLoadable) { 13 T result; 14 readWriteLock.readLock().lock();//添加读锁 15 try { 16 //缓存中查找 17 String goodsStockJsonStr = RedisCache.get(queryKey); 18 //缓存中查找成功 19 if (!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 20 logger.info("=====query from cache====="); 21 result = JSONObject.parseObject(goodsStockJsonStr, typeReference); 22 } else { 23 //若缓存读取失败,则需要去数据库中查询 24 readWriteLock.readLock().unlock();//释放读锁 25 readWriteLock.writeLock().lock();//添加写锁 26 try { 27 goodsStockJsonStr = RedisCache.get(queryKey); 28 if (!StringUtils.isEmpty(goodsStockJsonStr) && !"null".equals(goodsStockJsonStr)) { 29 logger.info("=====query from cache====="); 30 return JSONObject.parseObject(goodsStockJsonStr, typeReference); 31 } 32 logger.info("=====query from DB====="); 33 //这里调用业务传入的回调方法,真正处理业务的地方只有这一行 34 result = cacheLoadable.load(); 35 RedisCache.set(queryKey, JSONArray.toJSONString(result)); 36 } finally { 37 readWriteLock.writeLock().unlock(); 38 readWriteLock.readLock().lock(); 39 } 40 } 41 } finally { 42 readWriteLock.readLock().unlock(); 43 } 44 return result; 45 }
然后我们再业务使用的时候,只需要像如下调用即可:
1 public GoodsStock queryByTemplate(Integer id) { 2 return cacheServiceTemplate.queryByCache(String.valueOf(id), 0, null, 3 new TypeReference<GoodsStock>() {}, new CacheLoadable<GoodsStock>() { 4 @Override 5 public GoodsStock load() { 6 return goodsStockMapper.selectByPrimaryKey(id); 7 } 8 }); 9 }
四、总结
文章中完整源码:https://github.com/Gonjan/javaPractice/tree/master/src
写到最后,这篇文章也没多少干货,其实就是将自己动手实践的一部分记录下来而已,看来毕竟是博客写得太少,没有啥章法,想到哪儿写到哪,比较乱,写着写着就跑偏了(T_T真是哭死),还需多多练习才行。