概述:
- 面向过程:根据业务逻辑从上到下写垒代码
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
面向对象编程是一种编程方式,此编程方式的落地需要使用 “类” 和 “对象” 来实现,所以,面向对象编程其实就是对 “类” 和 “对象” 的使用。
1,类就是一个模板,模板里可以包含多个函数,函数里实现一些功能
2,对象则是根据模板创建的实例,通过实例对象可以执行类中的函数

- class是关键字,表示类
- 创建对象,类名称后加括号即可
类中定义的函数叫做 “方法”
1 #!/usr/bin/python 2 # -*-coding:utf-8 -*- 3 #创建类 4 class foo: 5 def bar(self): 6 print('bar') 7 def hello(self,name): 8 print('i am %s' %name) 9 #根据类foo创建对象obj 10 obj=foo() 11 obj.bar() #执行bar方法 12 obj.hello('gongxu') #执行hello方法(传参)
使用函数式编程和面向对象编程方式来执行一个“方法”时函数要比面向对象简便
- 面向对象:【创建对象】【通过对象执行方法】
- 函数编程:【执行函数】
观察上述对比答案则是肯定的,然后并非绝对,场景的不同适合其的编程方式也不同。
总结:函数式的应用场景 --> 各个函数之间是独立且无共用的数据
面向对象三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
为什么要封装?
封装不是单纯意义的隐藏:
1:封装数据的主要原因是:保护隐私
2:封装的主要原因是:隔离复杂度
为什么要用property
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则
除此之外,看下
面向对象的封装有三种方式
public(这种其实就是不封装,是对外公开的)
protected(这种封装方式对外不公开,但对朋友(friend)或者子类(形象的说法是“儿子”,但我不知道为什么大家不说“女儿”,就像“parent”本来是父母的意思,但中文都是叫“父类”)公开)
private(这种封装对谁都不公开)
封装其实分为两个层面,但无论哪种层面的封装,都要对外界提供好访问你内部隐藏内容的接口(接口可以理解为入口,有了这个入口,使用者无需且不能够直接访问到内部隐藏的细节,只能走接口,并且我们可以在接口的实现上附加更多的处理逻辑,从而严格控制使用者的访问)
第一个层面的封装(什么都不用做):创建类和对象会分别创建二者的名称空间,我们只能用类名,或者obj.的方式去访问里面的名字,这本身就是一种封装。
第二个层面的封装:类中把某些属性和方法隐藏起来(或者说定义成私有的),只在类的内部使用,外部无法访问,或者留下少量接口(函数)供外部访问
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容
在python中用双下划线的方式实现隐藏属性(设置成私有的)
第一步:将内容封装到某处
class Foo: def __init__(self,name,age): #称为构造方法,根据类创建对象时自动执行 self.name=name self.age=age #根据类Foo创建对象 #自动执行Foo类的__init__方法 obj=Foo('gongxu',18) #将gongxu和18分别封装到obj,self的name和age属性中 #根据类foo创建对象 obj2=Foo('haha',18) #将haha和18分别封装到obj2,self的name和age属性中
self 是一个形式参数,当执行 obj = Foo('gongxu', 18 ) 时,self 等于 obj1
当执行 obj2 = Foo('haha', 18) 时,self 等于 obj2
所以,内容其实被封装到了对象 obj 和 obj2 中,每个对象中都有 name 和 age 属性,
第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
- 通过对象直接调用
- 通过self间接调用
1、通过对象直接调用被封装的内容
1 class foo: 2 def __init__(self,name,age): 3 self.name=name 4 self.age=age 5 6 obj1=foo('gongxu',18) 7 print(obj1.name) #直接调用obj1对象的name属性 8 print(obj1.age) #直接调用obj1对象的age属性 9 10 obj2=foo('haha',23) 11 print(obj2.name) #直接调用obj2对象的name属性 12 print(obj2.age) #直接调用obj2对象的age属性
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容
1 class foo: 2 3 def __init__(self,name,age): 4 self.name=name 5 self.age=age 6 7 def tail(self): 8 print(self.name) 9 print(self.age) 10 11 obj=foo('gongxu',18) 12 obj.tail() #python默认会将obj传给self参数,即:obj.tail(obj),所以,此时方法内部的 self = obj,即:self.name 是 gongxu ;self.age 是 18 13 14 obj1=foo('haha',18) 15 obj1.tail() #python默认会将obj1传给self参数,即:obj.tail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 haha ;self.age 是 18
综上所述,对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封装的内容。
1 函数式编程 2 def kanchai(name,age,gender): 3 print("%s,%s岁,%s,上山去砍柴" %(name,age,gender)) 4 5 def tiaoshui(name,age,gender): 6 print("%s,%s岁,%s,下河去挑水" %(name,age,gender)) 7 8 def heshui(name,age,gender): 9 print("%s,%s岁,%s,heshui" %(name,age,gender)) 10 11 kanchai('haha',18,'男') 12 tiaoshui('xixi',18,'女') 13 heshui('zizi',19,'男')
面向对象
1 面向对象 2 class foo: 3 def __init__(self,name,age,gender): 4 self.name=name 5 self.age=age 6 self.gender=gender 7 8 def kanchai(self): 9 print("%s,%s岁,%s,上山去砍柴" %(self.name,self.age,self.gender)) 10 11 def tiaoshui(self): 12 print("%s,%s岁,%s,下河去挑水" %(self.name,self.age,self.gender)) 13 14 def heshui(self): 15 print("%s,%s岁,%s,heshui" %(self.name,self.age,self.gender)) 16 17 haha=foo('gx ',20,'女') 18 haha.kanchai() 19 haha.tiaoshui() 20 haha.heshui()
上述对比可以看出,如果使用函数式编程,需要在每次执行函数时传入相同的参数,如果参数多的话,又需要粘贴复制了... ;而对于面向对象只需要在创建对象时,将所有需要的参数封装到当前对象中,之后再次使用时,通过self间接去当前对象中取值即可。
什么是继承?
继承指的是类与类之间的关系,是一种什么是什么的关系,功能之一就是用来解决代码重用问题(比如练习7中Garen与Riven类有很多冗余的代码)
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类,新建的类称为派生类或子类
class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass pass class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 pass
继承,面向对象中的继承和现实生活中的继承相同,即:子可以继承父的内容。
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构
继承是一种创建新类的方式,新建的类可以继承一个或多个父类,父类又可称为基类或超类,新建的类称为派生类或子类
继承的好处:减少冗余代码
在子类定义新的属性,覆盖掉父类的属性,称为派生
例如:
猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我们要分别为猫和狗创建一个类,那么就需要为 猫 和 狗 实现他们所有的功能,如下所示:
1 class 猫: 2 3 def 喵喵叫(self): 4 print '喵喵叫' 5 6 def 吃(self): 7 # do something 8 9 def 喝(self): 10 # do something 11 12 def 拉(self): 13 # do something 14 15 def 撒(self): 16 # do something 17 18 class 狗: 19 20 def 汪汪叫(self): 21 print '喵喵叫' 22 23 def 吃(self): 24 # do something 25 26 def 喝(self): 27 # do something 28 29 def 拉(self): 30 # do something 31 32 def 撒(self): 33 # do something
上述代码不难看出,吃、喝、拉、撒是猫和狗都具有的功能,而我们却分别的猫和狗的类中编写了两次。如果使用 继承 的思想,如下实现:
动物:吃、喝、拉、撒
猫:喵喵叫(猫继承动物的功能)
狗:汪汪叫(狗继承动物的功能)
class Animal: def eat(self): print "%s 吃 " %self.name def drink(self): print "%s 喝 " %self.name def shit(self): print "%s 拉 " %self.name def pee(self): print "%s 撒 " %self.name class Cat(Animal): def __init__(self, name): self.name = name self.breed = '猫' def cry(self): print '喵喵叫' class Dog(Animal): def __init__(self, name): self.name = name self.breed = '狗' def cry(self): print '汪汪叫' # ######### 执行 ######### c1 = Cat('我家的小黑猫') c1.eat() c2 = Cat('他家的小白猫') c2.drink() d1 = Dog('谁家的小瘦狗') d1.eat()
所以,对于面向对象的继承来说,其实就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。
注:除了子类和父类的称谓,你可能看到过 派生类 和 基类 ,他们与子类和父类只是叫法不同而已。

那么问题又来了,多继承呢?
- 是否可以继承多个类
- 如果继承的多个类每个类中都定了相同的函数,那么那一个会被使用呢?
1、Python的类可以继承多个类,Java和C#中则只能继承一个类
2、Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先
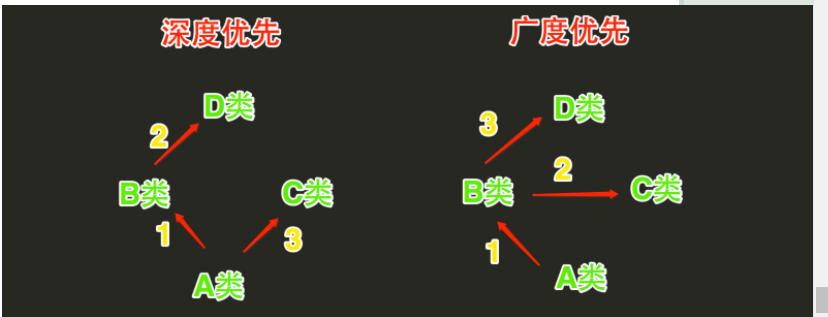
- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。
1.只有在python2中才分新式类和经典类,python3中统一都是新式类 2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类 3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类 3.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类
class A1: #A1是经典类 pass class A2: #A2是经典类 pass class B1(object): #B1是新式类 pass class B2(B1): #B2是新式类 pass
经典类多继承
1 class D: 2 3 def bar(self): 4 print 'D.bar' 5 6 7 class C(D): 8 9 def bar(self): 10 print 'C.bar' 11 12 13 class B(D): 14 15 def bar(self): 16 print 'B.bar' 17 18 19 class A(B, C): 20 21 def bar(self): 22 print 'A.bar' 23 24 a = A() 25 # 执行bar方法时 26 # 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错 27 # 所以,查找顺序:A --> B --> D --> C 28 # 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了 29 a.bar()
新式类多继承
1 class D(object): 2 3 def bar(self): 4 print 'D.bar' 5 6 7 class C(D): 8 9 def bar(self): 10 print 'C.bar' 11 12 13 class B(D): 14 15 def bar(self): 16 print 'B.bar' 17 18 19 class A(B, C): 20 21 def bar(self): 22 print 'A.bar' 23 24 a = A() 25 # 执行bar方法时 26 # 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错 27 # 所以,查找顺序:A --> B --> C --> D 28 # 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了 29 a.bar()
经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
继承与抽象
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
抽象只是分析和设计的过程中,一个动作或者说一种技巧,通过抽象可以得到类

多态
Pyhon不支持Java和C#这一类强类型语言中多态的写法,但是原生多态,其Python崇尚“鸭子类型”。
在程序设计中,鸭子类型(英语:duck typing)是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定。这个概念的名字来源于由James Whitcomb Riley提出的鸭子测试,“鸭子测试”可以这样表述:
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
在鸭子类型中,关注的不是对象的类型本身,而是它是如何使用的。例如,在不使用鸭子类型的语言中,我们可以编写一个函数,它接受一个类型为鸭的对象,并调用它的走和叫方法。在使用鸭子类型的语言中,这样的一个函数可以接受一个任意类型的对象,并调用它的走和叫方法。如果这些需要被调用的方法不存在,那么将引发一个运行时错误。任何拥有这样的正确的走和叫方法的对象都可被函数接受的这种行为引出了以上表述,这种决定类型的方式因此得名。
鸭子类型通常得益于不测试方法和函数中参数的类型,而是依赖文档、清晰的代码和测试来确保正确使用。从静态类型语言转向动态类型语言的用户通常试图添加一些静态的(在运行之前的)类型检查,从而影响了鸭子类型的益处和可伸缩性,并约束了语言的动态特性。


1 class A: 2 def prt(self): 3 print("A") 4 class B(A): 5 def prt(self): 6 print("B") 7 class C(A): 8 def prt(self): 9 print("C") 10 class D(A): 11 pass 12 class E: 13 def prt(self): 14 print("E") 15 class F: 16 pass 17 def test(arg): 18 arg.prt() 19 a = A() 20 b = B() 21 c = C() 22 d = D() 23 e = E() 24 f = F() 25 26 test(a) 27 test(b) 28 test(c) 29 test(d) 30 test(e) 31 test(f) 32 33 输出结果 34 A 35 B 36 C 37 A 38 E 39 Traceback (most recent call last): 40 File "/Users/shikefu678/Documents/Aptana Studio 3 Workspace/demo/demo.py", line 33, in <module> 41 test(a),test(b),test(c),test(d),test(e),test(f) 42 File "/Users/shikefu678/Documents/Aptana Studio 3 Workspace/demo/demo.py", line 24, in test 43 arg.prt() 44 AttributeError: F instance has no attribute 'prt'
a,b,c,d都是A类型的变量,所以可以得到预期的效果(从java角度的预期),e并不是A类型的变量但是根据鸭子类型,走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子,e有prt方法,所以在test方法中e就是一个A类型的变量,f没有prt方法,所以f不是A类型的变量。
以上是从java的角度分析的,其实上边都是一派胡言,只是为了说明python中的运行方法。没有谁规定test方法是接收的参数是什么类型的。test方法只规定,接收一个参数,调用这个参数的prt方法。在运行的时候如果这个参数有prt方法,python就执行,如果没有,python就报错,因为abcde都有prt方法,而f没有,所以得到了上边得结果,这就是python的运行方式
多态与多态性
一:多态:同一种事物的多种形态
1:序列类型有多种形态:字符串,列表,元组
2:动物有多种形态:人,狗,猪
1 文件有多种形态:文本文件,可执行文件 2 import abc 3 class File(metaclass=abc.ABCMeta): 4 @abc.abstractmethod 5 def click(self): 6 pass 7 8 class Txt(File): #文件的形态之一:文本文件 9 def click(self): 10 print('open txt') 11 12 class Exe(File): #文件的形态之二:可执行文件 13 def click(self): 14 print('exe file')
二:多态性:
1 import abc 2 class Animal(metaclass=abc.ABCMeta): 3 @abc.abstractmethod 4 def talk(self): 5 pass 6 7 class People(Animal): #动物的形态之一:人 8 def talk(self): 9 print('hello') 10 11 class Dog(Animal): #动物的形态之二:狗 12 def talk(self): 13 print('汪汪汪') 14 15 class Pig(Animal): #动物的形态之三:猪 16 def talk(self): 17 print('哼唧哼唧哼唧') 18 19 20 p=People() 21 pig=Pig() 22 dog=Dog() 23 24 def func(animal): 25 animal.talk() 26 27 func(p) 28 func(pig) 29 func(dog) 30 31
为什么要用多态性(多态性的好处)
1.增加了程序的灵活性
以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal)
2.增加了程序额可扩展性
通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用
!!!obj.func():是调用了obj的方法func,又称为向obj发送了一条消息func
多态性指的是具有不同功能的函数可以使用相同的函数名,这样就可以用一个函
数名调用不同功能的函数。
在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息(!!!obj.func():是调用了obj的方法func,又称为向obj发送了一条消息func),不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
比如:老师.下课铃响了(),学生.下课铃响了(),老师执行的是下班操作,学生执行的是放学操作,虽然二者消息一样,但是执行的效果不同
多态性分为静态多态性和动态多态性
静态多态性:如任何类型都可以用运算符+进行运算
三:为何要用多态性
1:增加了程序的灵活性
以不变应万变,不论对象如何变化,使用者都用同一种方式去调用,如func(animal)
2:增加了程序的可扩展性
1 class Animal: 2 def talk(self): 3 print("说哈哈") 4 class people(Animal): 5 def talk(self): 6 print('sey hello') 7 class pig(Animal): 8 def talk(self): 9 print("哼哼哼") 10 class dog(Animal): 11 def talk(self): 12 print("汪汪汪") 13 peo1=people() 14 pig1=pig() 15 dog1=dog()
抽象类
1 什么是抽象类
与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化
2 为什么要有抽象类
如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。
比如我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉,要么是吃一个具体的桃子。。。。。。你永远无法吃到一个叫做水果的东西。
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。这一点与接口有点类似,但其实是不同的,
#抽象类 import abc class File(metaclass=abc.ABCMeta): #定义接口Interface类来模仿接口的概念,python中压根没有interface关键字来定义一个接口 @abc.abstractclassmethod def read(self): #定义接口函数read pass @abc.abstractclassmethod def write(self): #定义接口函数write pass class Process(File): def read(self): #print('进程数据的读取方法) pass def write(self): print('进程数据的读取方法') p=Process() p.read()
抽象类与接口
抽象类的本质还是类,指的是一组类的相似性,包括数据属性(如all_type)和函数属性(如read、write),而接口只强调函数属性的相似性。
抽象类是一个介于类和接口直接的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计
绑定方法与非绑定方法
类中定义的函数分成两大类:
一:绑定方法(绑定给谁,谁来调用就自动将它本身当作第一个参数传入):
1. 绑定到类的方法:用classmethod装饰器装饰的方法。
为类量身定制
类.boud_method(),自动将类当作第一个参数传入
(其实对象也可调用,但仍将类当作第一个参数传入)
2. 绑定到对象的方法:没有被任何装饰器装饰的方法。
为对象量身定制
对象.boud_method(),自动将对象当作第一个参数传入
(属于类的函数,类可以调用,但是必须按照函数的规则来,没有自动传值那么一说)
二:非绑定方法:用staticmethod装饰器装饰的方法
1. 不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说。就是一个普通工具而已
注意:与绑定到对象方法区分开,在类中直接定义的函数,没有被任何装饰器装饰的,都是绑定到对象的方法,可不是普通函数,对象调用该方法会自动传值,而staticmethod装饰的方法,不管谁来调用,都没有自动传值一说
绑定方法
#绑定到类的方法 class Foo: @classmethod def test(cls): print(cls) f=Foo() f.test() #非绑定方法 class Foo: @staticmethod def test(x,y): print('test',x,y) Foo.test(1,3) f=Foo() f.test(1,10)
#绑定到对象的方法 class Foo: def test(self): print('test',self) def test1(self): print('test1',self) def test2(self): print('test2',self) f=Foo() f.test() f.test1() f.test2()
1 父类改变 子类只需要改变类调用 不需要改函数 2 class Foo1: #父类名改变 3 def test(self): 4 print("from foo.test") 5 class Bar(Foo1): #子类名改变,不需要改子类的test函数 6 def test(self): 7 #Foo.test(self) 相对于如下 8 super(Bar,self).test() #使用super,父类改变 子类只需要改变类调用 不需要改函数 9 print("bar222") 10 a=Bar() 11 a.test() 12 #from foo.test 13 #bar222
statimethod不与类或对象绑定,谁都可以调用,没有自动传值效果,python为我们内置了函数staticmethod来把类中的函数定义成静态方法
import hashlib import time class MySQL: def __init__(self,host,port): self.id=self.create_id() self.host=host self.port=port @staticmethod def create_id(): #就是一个普通工具 m=hashlib.md5(str(time.clock()).encode('utf-8')) return m.hexdigest() print(MySQL.create_id) #<function MySQL.create_id at 0x0000000001E6B9D8> #查看结果为普通函数 conn=MySQL('127.0.0.1',3306) print(conn.create_id) #<function MySQL.create_id at 0x00000000026FB9D8> #查看结果为普通函数
classmehtod是给类用的,即绑定到类,类在使用时会将类本身当做参数传给类方法的第一个参数(即便是对象来调用也会将类当作第一个参数传入),python为我们内置了函数classmethod来把类中的函数定义成类方法
1 HOST='127.0.0.1' 2 PORT=3306 3 DB_PATH=r'C:UsersAdministratorPycharmProjects est面向对象编程 est1db'
1 import settings 2 import hashlib 3 import time 4 class MySQL: 5 def __init__(self,host,port): 6 self.host=host 7 self.port=port 8 9 @classmethod 10 def from_conf(cls): 11 print(cls) 12 return cls(settings.HOST,settings.PORT) 13 14 print(MySQL.from_conf) #<bound method MySQL.from_conf of <class '__main__.MySQL'>> 15 conn=MySQL.from_conf() 16 17 print(conn.host,conn.port) 18 conn.from_conf() #对象也可以调用,但是默认传的第一个参数仍然是类 19 复制代码
#statcimethod 与 classmethod的区别 import settings class MySQL: def __init__(self,host,port): self.host=host self.port=port @classmethod def from_conf(cls): return cls(settings.HOST,settings.PORT) #Mariadb(127.0.0.1,3306) #@staticmethod #def from_conf(): # return MySQL(settings.HOST,settings.PORT) #MySQL(127.0.0.1,3306) def __str__(self): return '就不告诉你' def __str__(self): return '就不告诉你' #conn=MySQL.from_conf() #print(conn.host) class Maeiab(MySQL): def __str__(self): return 'host:%s port:%s' %(self.host,self.port) pass conn1=Maeiab.from_conf() print(conn1)
class Foo: def __init__(self): return 123 #抛出异常,不能有返回 f=Foo()
什么样的代码才是面向对象?
答:从简单来说,如果程序中的所有功能都是用 类 和 对象 来实现,那么就是面向对象编程了。
问题二:函数式编程 和 面向对象 如何选择?分别在什么情况下使用?
答:须知:对于 C# 和 Java 程序员来说不存在这个问题,因为该两门语言只支持面向对象编程(不支持函数式编程)。而对于 Python 和 PHP 等语言却同时支持两种编程方式,且函数式编程能完成的操作,面向对象都可以实现;而面向对象的能完成的操作,函数式编程不行(函数式编程无法实现面向对象的封装功能)。
所以,一般在Python开发中,全部使用面向对象 或 面向对象和函数式混合使用
面向对象的应用场景:
1.多函数需使用共同的值,如:数据库的增、删、改、查操作都需要连接数据库字符串、主机名、用户名和密码
1 class SqlHelper: 2 3 def __init__(self, host, user, pwd): 4 5 self.host = host 6 self.user = user 7 self.pwd = pwd 8 9 def 增(self): 10 # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 11 # do something 12 # 关闭数据库连接 13 14 def 删(self): 15 # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 16 # do something 17 # 关闭数据库连接 18 19 def 改(self): 20 # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 21 # do something 22 # 关闭数据库连接 23 24 def 查(self): 25 # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 26 # do something 27 # 关闭数据库连接# do something
2.需要创建多个事物,每个事物属性个数相同,但是值的需求
如:张三、李四、杨五,他们都有姓名、年龄、血型,但其都是不相同。即:属性个数相同,但值不相同
1 class Person: 2 3 def __init__(self, name ,age ,blood_type): 4 5 self.name = name 6 self.age = age 7 self.blood_type = blood_type 8 9 10 def detail(self): 11 temp = "i am %s, age %s , blood type %s " % (self.name, self.age, self.blood_type) 12 print temp 13 14 zhangsan = Person('张三', 18, 'A') 15 lisi = Person('李四', 73, 'AB') 16 yangwu = Person('杨五', 84, 'A')
类和对象在内存中是如何保存?
答:类以及类中的方法在内存中只有一份,而根据类创建的每一个对象都在内存中需要存一份,
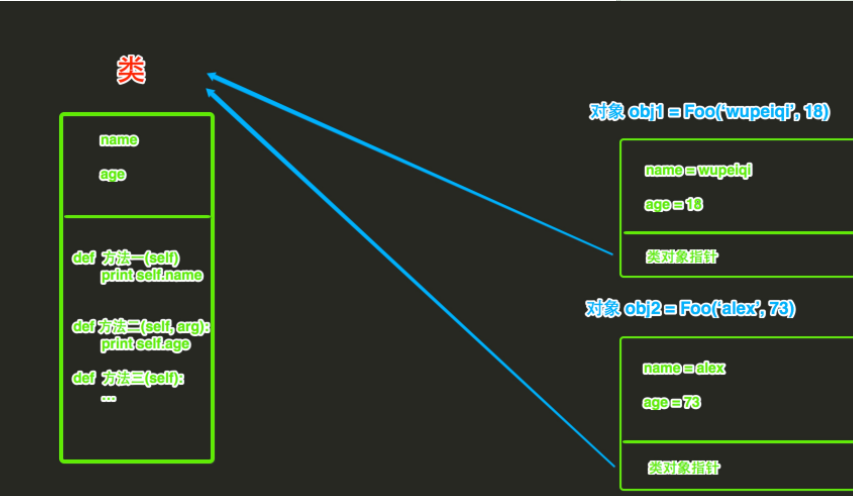
如上图所示,根据类创建对象时,对象中除了封装 name 和 age 的值之外,还会保存一个类对象指针,该值指向当前对象的类。
当通过 obj1 执行 【方法一】 时,过程如下:
- 根据当前对象中的 类对象指针 找到类中的方法
- 将对象 obj1 当作参数传给 方法的第一个参数 self