目录:
1. 序言
2.正文
2.1 关于ROI
2.2 关于RPN
2.3 关于anchor
3. 关于数据集合制作
4. 关于参数设置
5. 参考
1.序言
叽歪一下目标检测这个模型吧,这篇笔记是依据我对源码的阅读和参考一些博客,还有rbg的论文之后,这里描述一下个人对于faster-rcnn的一些微小的了解,只是总结一些关键点的理解. 首先看一下这张faster-rcnn整体的图:

2.正文
我们在细说这些关键节点的时候,首先让我们来看一下这个框架,这个图谱是引用的http://shartoo.github.io/RCNN-series/,并且下面的图片都来自于这里,在此处进行说明:

2.1 关于ROI & ROI pooling
ROI的全称为region of interest,俗称感兴趣区域,ROI用来提取我们感兴趣的区域,ROI的应用在一下几个方面:
1. 在训练模型的时候,ROI用来抽取所选区域样本.
2. 在模型预测时,由RPN提供的top300个建议区域.
其实比较关键的内容应该是ROI pooling 也就是兴趣区域池化层,这里完全可以单独的拿出来说一说,详细代码见roi_pooling_layer.cu实现,为什么说它很重要呢?
一般来说我们使用CNN做图片分类的时候,需要将待分类的图片缩放到统一大小,之所以这样做,是因为全链接(FCN)层对我们卷积后的特征图有大小限制,但是我们在使用faster-rcnn运行模型时,
并不需要对图下有大小限制,这就是ROI pooling层的贡献了,因为他会对我们特征图上的ROI区域,进行池化,首先我们要知道ROI的结构成份(left_x,left_y,height,width),ROI pooling 层会将特征图上的ROI区域缩放到符合
FCN层要求的大小,然后在进行分类和预测.
2.2 关于RPN
对于RPN,它在faster-rcnn模型中扮演角色就是通过对特征图进行初级的目标区域选取,通过预测给予最高的前300个最高的置信度的目标区域,然后fast-rcnn中特征图去获取建议的目标区域,进行分类和预测,那么RPN网络是如何实现这一功能的呢?
论文中的RPN网络接入的是经过5次卷积之后的特征图(vgg为例),对于这些特征图,RPN会对特征图再使用一个k*k大小的卷积核(滑动窗口)(论文中提供的是k=3)进行卷积滑动,并且滑动窗口(指整个窗口的区域)中的位置都会映射到一个原图的对应的位置,并且由anchor提供了三种尺寸(128^2,256^2,512^2),提供三种比例(1:1,1:2,2:1),通过这些组合可以生成9种尺寸大小的区域,但是映射覆盖区域不能超出图像本身大小,这样就最多产生9个区域结果会分别被接入到cls预测层和reg归层,对于cls层,会通过预测的区域和目标区域(groud truth)进行一个IOU计算,如果IOU>0.7大于1则判断为目标,如果IOU<0.3则判断为背景,同时记录下他们的预测值,如果i在0.3~0.7之间,则是一个无法确定的预测,该区域就不加入到网络训练中.对于reg层会产生加入网络训练中的坐标信息边框回归过程,通过回归过程的训练,是的建议区域尽可能的接近groud truth(目标区域),最后将建议区域接入到ROI pooling层中全链接
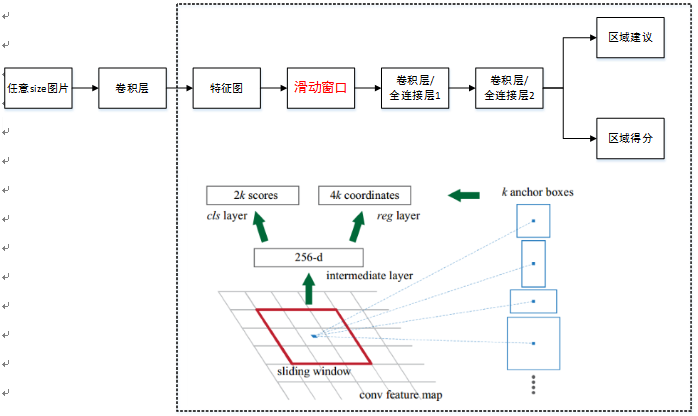
2.3 关于anchor
anchor提供了三种尺寸(128^2,256^2,512^2),提供三种比例(1:1,1:2,2:1),通过这些组合可以生成9种组合尺寸大小的区域

3. 关于数据集合制作
关于数据集合的制作,我们先来描述一下数据集合的一些的有那些内容,我们就那官方提供的数据集合来说吧~,比如VOCdevkit2007 中的Annotations,ImageSets,JPEGImages,其他的我们可以不用看。
关于Annotations文件夹,文件夹下放置*.xml, JPEGImages放置*.jpg ,注意一个xml必须要对应一个jpg,ImageSets文件夹中放置var.txt,train.txt,trainval.txt,test.txt,还有各种*var.txt,*train.txt,*trainval.txt,这里的*填写标签名,
需要说明的几点,trainval.txt放置所有的图片名,train.txt放置trainval.txt一半的标签名,val.txt放置trainval.txt一半的标签.test.txt其实不要也可以. *var.txt,*train.txt,*trainval.txt 也是一样,这里还需要注意的一点就是 *var.txt,*train.txt,*trainval.txt 中的0,-1,1意思0表示这个图片中存在模糊的样本,1表示该图片中存在该标签的样本,-1表示该图片中存在该图片不存在该标签的样本.
框架图
4. 参考资料:
http://shartoo.github.io/RCNN-series/
http://blog.csdn.net/u013832707/article/details/53641055
faster-rcnn论文