背景
前段时间,用过一些模型如vgg,lexnet,用于做监督学习训练,顺带深入的学习了一下相关模型的结构&原理,对于它的反向传播算法记忆比较深刻,
就自己的理解来描述一下BP网络.
关于BP网络的整体简述
BP神经网络,全程为前馈神经网络,它被用到监督学习中的主体思想是(我们假定我们这里各个层Layer次间采用的是全链接): 通过各个Layer层的激励和权值以及偏置的处理向前传递,最终得到一个预期的值,然后通过标签值和预期的值得到一个残差值,残差值的大小反映了预期值和残差值的偏离程度,然后使用反向传播算法(见下文),然后对上一层的推倒公式进行梯度(就是对应每一个变量x1,x2,x3,x4,x5,.....,xn求解偏导,见下文)求解,然后代入各个变量x,得到各个变量x 当前层Layer对应的权值w'(这个w'其实就是当前w偏离真实的w的残差值),然后依次的向上一层反向传播,最终到达Input层,这时候我们会就会得到各个层Layer相对应的权值w的偏离值,然后我们可以设定一个学习率(在caffe中是用l_r表示的),也就是步长,来设置我们参数更新的大小其实就是各个层layer当前的权值w加上对应的w的偏离值乘上这个步长即 w+=w‘*l_r,这样就达到了参数的更新,然后通过数次迭代调整好w,b参数,特别需要强调一下的是,b可以是固定的,也可以设置成跟w权值相关的,比如b=w/2 等等,视情况而定。
以上就是就是BP网络的大致的描述了,那么我们开始到BP网络的每一个细节,进行说明吧.~
关于梯度
对于梯度,我们这里就从这几个角度进行一下解释,什么是梯度,梯度在BP网络中的作用,或者说为什么BP网络中要采用梯度.
1.1什么是梯度?
梯度,即求偏导,比如我们有这样一个函数,f = 2a +3b ,如果我们求解a的梯度,fa = 2,如果我们求解b的梯度,f_b = 3
以上就是对梯度最简单的描述,那个也是只有一层神经网络时的参数求解,但是在实际的网络模型中,我们基本上不会用那么简单的模型,我们一般用层数较多(大于2层的模型进行)的模型来解决我们所面临的问题,对于多层神经网络
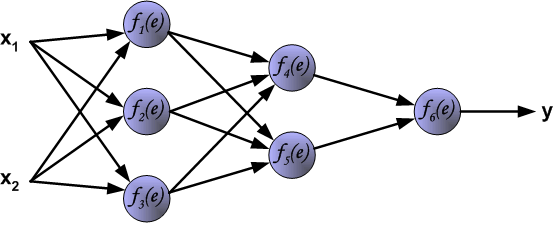
如图,这是一个三层的神经网络
我们一般将其等化成数学中的复合函数,比如上图中这个三层的(全链接的)神经网络,其实用复合函数的公式表示就是这样:
对于第一层
f1 = x1*w1_11 + x2*w1_12 +b1_1
f2 = x1*w1_21 + x2*w1_22 +b1_2
f3 = x1*w1_31 + x2*w1_32 +b1_3
然后进入到第二层
f4 = f1*w2_11 + f2*w2_12 + f3*w2_13 + b2_1
f5 = f1*w2_21 + f2*w2_22 + f3*w2_23 + b2_2
然后第三层
f6 = f4*w3_11 + f5*w3_12 + b3_1
这个其实就和 f = (1-x^2)^3 改写成 g =x^2 , t = 1-x , f = x^3 是一个道理
第一层: g = x^2
第二层: t =1-g
第三层: f = t^3
我们对于这种复合函数求解梯度的步骤,如下:
f' = 3t^2*t' 对t求偏导数
t' = -g' 对g求偏导数
g' = 2x 对x求偏导数
这就是求解梯度的过程.
以上就是对于梯度的一个描述
1.2 那么梯度在BP网路中起到何种作用?
梯度在求解的过程中,其实就是对逐个变量进行求导,比如f =a(bx),我们将其改成复合函数f=2g ,g = bx ,对x进行求导,那么我们会得到变量的系数. 而我们所做的这一切就是为了得到这个,得到每一层Layer的各个变量对应的系数,这个系数非常重要,我们来举个例子说明一下,比如这个函数,f = a(bx),假设我们刚开始的时候随机的设定一个值给a = 0.23 , b=1 ,x去一系列值[1,2,3],我们都事先知道f的值对应[0.5,1,1.5],假定我们无法直接计算得到a的值为0.5,我们来一步步的估算a的,步骤如下:
不妨假定函数的真实值用ft表示,预估值用fp表示,残差用fre.
当 x = 1 , ft = 0.5
而我们用公式得到fp =0.23 ,fre = ft - fp =0.26,然后得到: are = 0.26*a,注 are为a的偏差值
,得到bre = b*are=1*0.26*a
然后我们再求解b的更新值 b_n = b + l_r*bre*b(g求关于x的梯度)*1 (l_r为我们设定的学习率)
再更新 a_n = a + l_r*are*ab(f求关于x梯度的值)*1
这样 我们就对参数a,b进行了更新.
然后当x =2 ,ft=1 .....依次这样迭代更新 a,b
我们就是通过这种方式来进行参数更新的....
2 关于梯度的反向传播.
反向传播就是将残差反推到各个参数上,求解各个参数的误差值,最后在每一个变量的梯度的方向上对误差进行修正,修正的幅度依据学习率而定.
参考文献:
1. http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html