想必大家都知道HashSet和HashMap之间的关系,HashSet是依赖于HashMap的,HashSet集合就是HashMap的key所组成的集合,我们都知道HashMap的value是可以重复的,但是key是不能重复的,同样我们也清楚Map集合是无序的,所以HashSet集合的特点就是 无序且保证元素不重复。
但是其实作为一个有经验的开发人员来说,至少我们应该是大概扫过源码的,所以面试时答上面那些是不够的,其实大家在最开始学的都是懵懵的,总是一种 “我是谁,我在哪,我要干什么的 感觉”,反正我学东西最开始都是这种感觉,好了不扯了。回到咱们研究的问题上来,HashSet创建时都做了哪些步骤,底层到底是怎么实现的,请继续往下看
首先,我们创建HashSet集合都是调用它的构造方法,HashSet提供了好几个构造方法,可以传递 初始容量和 加载因子,其实无论你创建HashSet时调用的是哪个构造方法,底层调用的都是HashMap的这个构造方法,注释写的比较详细,理解了这张图,再往下继续看

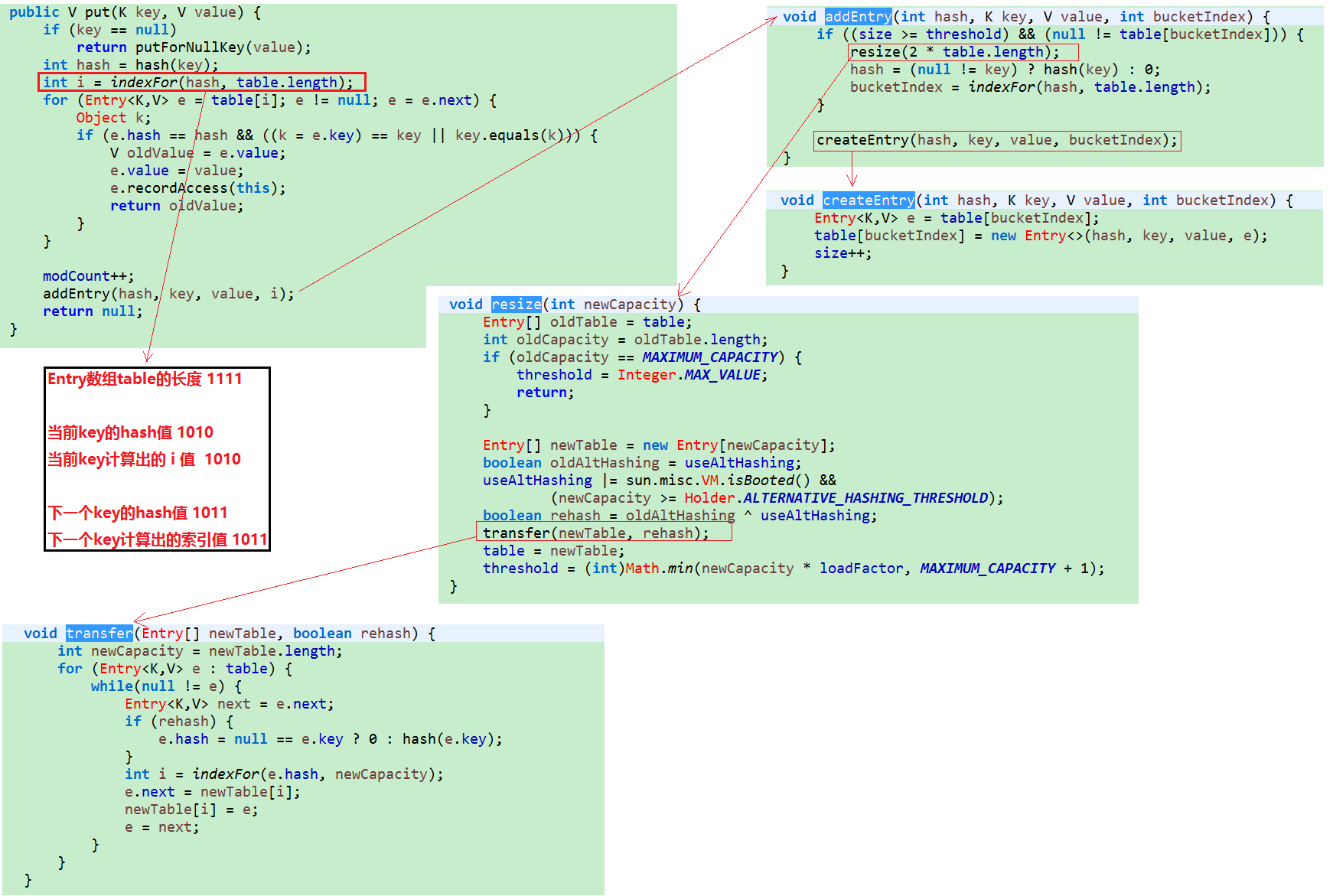
下面我们再来聊一下put方法是如何保证map的key唯一?
hashmap中key为null的元素肯定是保存在table[0],当hash冲突发生时,采用链地址法来解决冲突,使数据能够正常保存,不过map长度为偶数已经尽量在避免hash冲突,保证存入map的数据尽量均匀分布,当map中元素大于等于临界值threshold(map容量乘以加载因子)时,resize()方法会对map进行扩容,是之前容量的2倍,在扩容之后会对将原table中的数据经过重新计算索引后放入新的table中,transfer()方法就是最耗费时间的重新赋值的操作。赋值完成后,会将新添加的元素放入扩容之后的map中。