
本篇的介绍顺序是:
- 代码在内存中的分布
- 汇编语言翻译的代码
- 用汇编语言来看函数传参
代码在内存中的分布
代码在执行时就是系统当中的一个进程,每一个系统进程拥有一个4G空间的虚拟内存。代码在执行时从硬盘上被加载到内存中,那么在这个4G空间的内存中是如何分布的呢?请看下面的分布
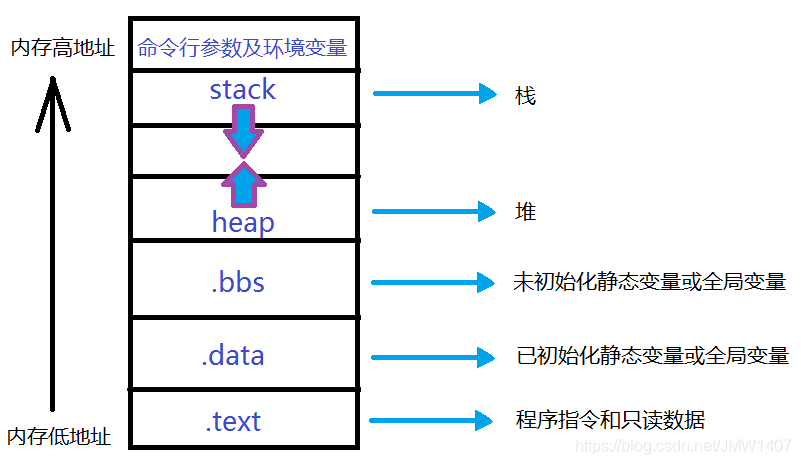
栈
进程地址空间中最顶部的段是栈,
作用:大多数编程语言将之用于存储函数参数和局部变量。
工作过程:调用一个方法或函数会将一个新的栈帧(stack frame)压入到栈中,这个栈帧会在函数返回时被清理掉。
优点:由于栈中数据严格的遵守FIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈中的内容,只需要一个简单的指针指向栈的顶端即可,因此压栈(pushing)和退栈(popping)过程非常迅速、准确。进程中的每一个线程都有属于自己的栈。
堆
与栈一样,堆用于运行时内存分配;但不同的是,堆用于存储那些生存期与函数调用无关的数据。
作用:堆用于存储那些生存期与函数调用无关的数据。
优点:大部分语言都提供了堆管理功能。在C语言中,堆分配的接口是malloc()函数。如果堆中有足够的空间来满足内存请求,它就可以被语言运行时库处理而不需要内核参与,否则,堆会被扩大,通过brk()系统调用来分配请求所需的内存块。
.bss
BSS保存的是未被初始化的静态变量内容,如果你写static intcntActiveUsers ,则cntActiveUsers的内容就会保存到BSS中去。
.data
数据段保存在源代码中已经初始化的静态变量的内容。也就是源代码中指定了初始值的静态变量。如果你写static int cntActiveUsers=10,则cntActiveUsers的内容就保存在了数据段中,而且初始值是10。
.text
代码段,主要保存程序的代码以及编译时静态链接进来的库。这段内存大小在程序运行之前就已经确定,而且是只读,可能存在一些常量,比如字符串常量。
代码在运行时,以上字段如何在内存中分布,可以参考这篇文章,让内存看得见摸得着。
https://blog.csdn.net/ljianhui/article/details/21666327
认识汇编
编程语言从面向对象的不同可以分为低级语言和高级语言。低级语言面向机器编程,如机器语言,汇编语言;高级语言面向过程和对象编程,如C、Java、Python、Go等。
低级语言更加接近计算机硬件,所以也能更加清晰的看出一个程序在执行时指令让硬件做什么了。并且高级语言往往都是编译成低级语言,再交给硬件执行。如典型的C语言执行的过程就有:预处理--->编译--->汇编--->链接。
汇编语言
硬件真正执行的是机器语言,类似于010101001的二进制,特点是最接近机器硬件,执行速度快,但是编写程序比较复杂。而汇编语言是为了解决编写机器语言复杂度。
汇编语言用一些容易理解和记忆的字母,单词来代替一个特定的指令,比如:用ADD代表数字逻辑上的加减,MOV代表数据传递等等,通过这种方法,人们很容易去阅读已经完成的程序或者理解程序正在执行的功能,对现有程序的bug修复以及运营维护都变得更加简单方便。
汇编demo
以C语言为例子,写一个最简单的C语言程序,编译出汇编语言。
#include<stdio.h>
int main()
{
int a = 10;
return 0;
}
gcc -S hello.c -o hello.s

汇编文件中,以.开头是伪指令。伪指令是是辅助性的,汇编器在生成目标文件时会用到这些信息,但伪指令不是真正的 CPU 指令,而是写给汇编器的。每种汇编器的伪指令也不同,要查阅相应的手册。
.file指明文件名字
.text指明内存中的代码段
.globl指明全局变量
其他内容无关紧要,下面把伪指令去掉再分析汇编文件。
main:
.LFB0:
pushq %rbp #rbp保存是main函数的地址,将其入栈,为函数的栈底
movq %rsp, %rbp #rsp代表main函数的栈顶,此时开辟栈顶和栈底
movl $10, -4(%rbp) #rbp寄存器保存的是一个地址,将地址数值-4,然后将10放在该地址指向的内存空间中
movl $0, %eax #return 0,设置返回值0
popq %rbp #将栈底变量从栈里弹出去,表示执行函数结束
ret #返回
.LFE0:
.size main, .-main
.ident "GCC: (Uos 8.3.0.3-3+rebuild) 8.3.0"
.section .note.GNU-stack,"",@progbits
汇编指令
%:表示一个寄存器。
寄存器名前有%前缀。例如,如果要使用eax,得写作: %eax。
$:立即数表示法,表示一个数值。
$10就是表示数字10。所谓立即数:还没放入内存之前的数就叫立即数,放入之后就不是了。立即数就是突然蹦出来的数,不是存到某些 容器(内存,寄存器)中的数
(%ebp):寻址
表示以%ebp里存储的值为地址,找到该地址指向的内存里的保存的值。这个叫寄存器寻址。-4(%ebp)表示 ebp-4,然后以这个值为地址,找到内存中该地址保存的值
movl:移动指令
movl $1234 %eax,表示将数值1234移动到eax寄存器中。
sunq:减指令
subq $16 %rsp,sub将两个操作数相减,用第二个操作数减去第一个操作数,将结果保存的到第二个操作数。该指令是将栈顶指针rsp向下移动16个地址。
addq:加指令
addq %rbx, %rax表示rbx的值加上rax的值,写到rax内。
lea:load effective address 加载有效地址
取地址传送到指定的的寄存器。leaq %123 %rax 将数值123的地址移动到寄存器rax。类似于C语言中的”&”。
call:函数调用
call fun:调用函数fun,执行到这一个指令之后,就进入fun函数。在栈中新开辟一个函数的栈帧,进入fun的栈帧执行。
函数调用
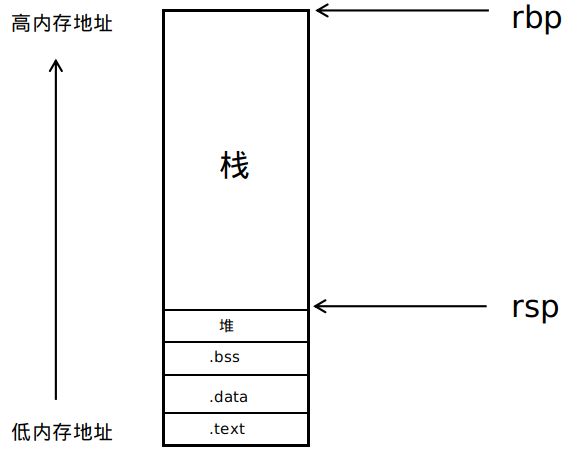
栈帧
函数调用包括将数据和控制从代码的一部分传递到另一部分。另外被调用函数有自己的局部变量空间,在被调用函数退出时释放这些空间。而大多数编程语言的数据传递、局部变量的分配和释放通过操纵程序栈来实现。为函数调用分配的那部分栈称为栈帧。
栈帧(stack frame):栈帧的主要作用是用来控制和保存一个函数调用的所有信息。机器用栈来传递过程参数,存储返回信息,保存寄存器用于以后恢复以及本地存储。栈帧其实是两个指针寄存器,寄存器%ebp为栈底指针,指向该栈帧的最底部,而寄存器%esp为栈顶指针,指向该栈帧的最顶部。
当程序运行时,栈指针可以移动,并且大多数的信息的访问都是通过栈底指针配合偏移量来完成。%ebp栈底指针是不移动的,访问栈里面的元素可以用-4(%ebp)或者8(%ebp)访问%ebp指针下面或者上面的元素。
函数调用过程
函数在调用过程中内存的变化:
1、在调用函数栈帧中将形参压入当前栈
2、跳转到被调函数
3、被调函数开辟新的栈帧
4、从寄存器获取形参
5、执行指令后退出
传值调用
#include<stdio.h>
void fun(int x)
{
int y;
y = x + 20;
}
int main()
{
int a = 10;
fun(a);
return 0;
}
gcc -S hello.c -o hello

传地址调用
#include <stdio.h>
void fun(int *x)
{
int y = 200;
*x = y + *x;
}
int main()
{
int a = 10;
fun(&a);
return 0;
}
gcc -S hello.c -o hello
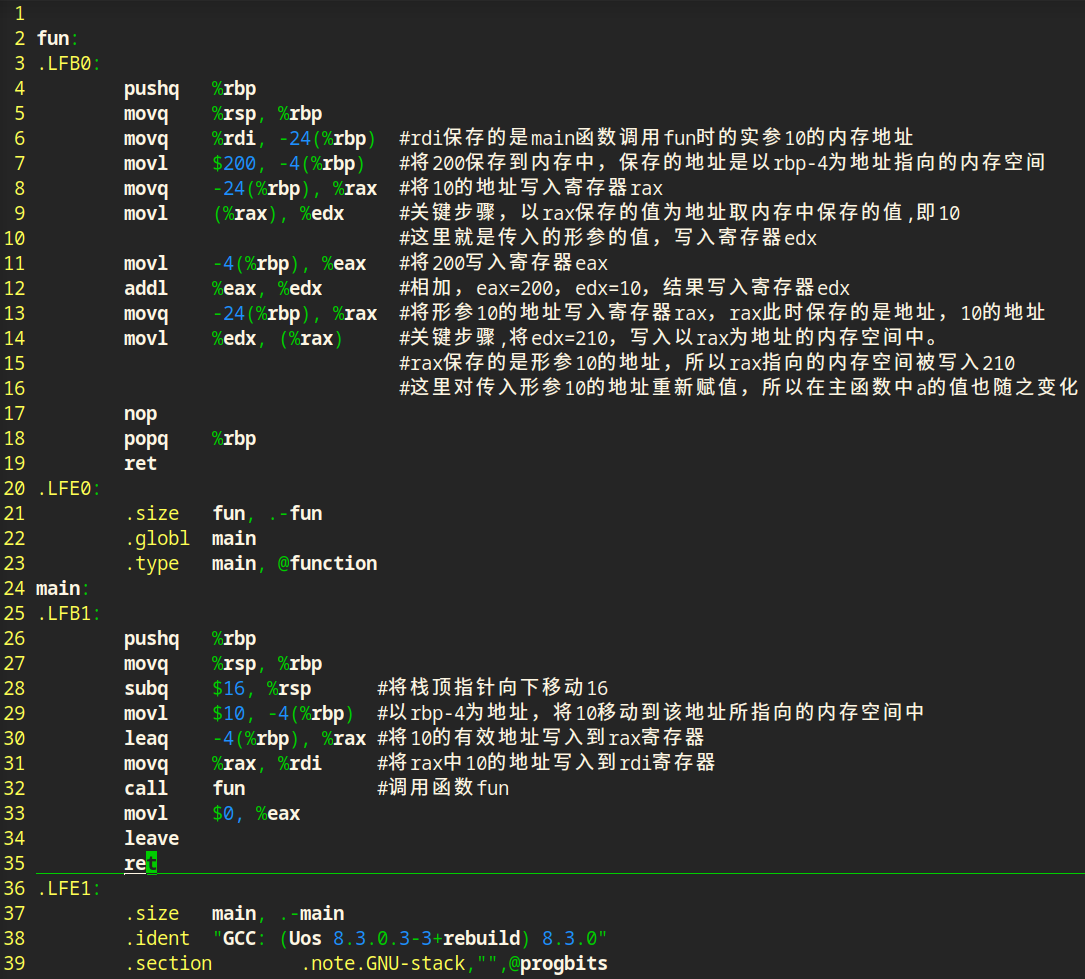
函数调用传参总结
传值调用和传地址调用最大区别就在于调用函数处理实参的方式,传值调用,就是将数值当做实参写入寄存器,被调用函数从寄存器中取出数值;传地址调用是将数值的地址当作实参写入寄存器,被调用函数中从寄存器取出地址。
传值调用
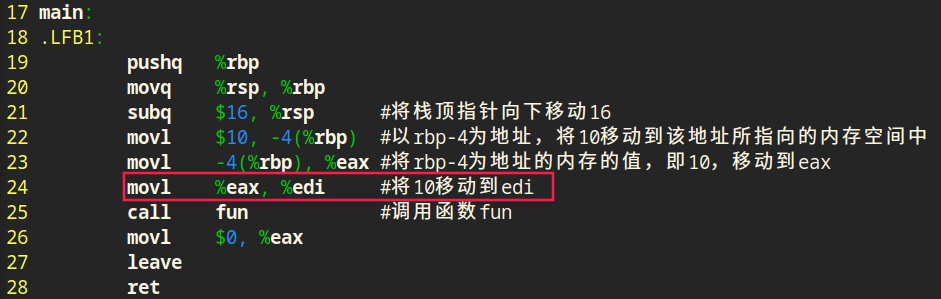
传地址调用
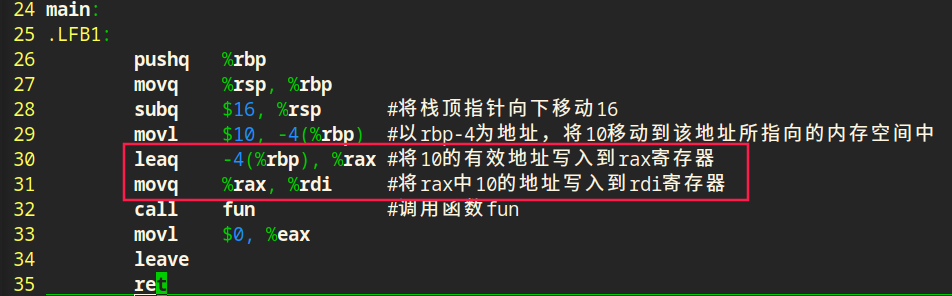
无论是传值还是传地址,都是将调用函数中的实参拷贝一份传递给被调用函数的形参。只不过区别在于:
传值调用直接拷贝一份数值到被调用函数,被调用函数中的数值和调用函数中的数值在内存中是两份相互独立的;传地址调用是将数值的地址拷贝一份到被调用函数中,数值在内存中只有一份,被调用函数通过该地址还能找到数值,可以修改这个数值。