翻译自understanding HBase and BigTable
学习HBase最难的部分莫过于真正理解它到底是什么东西,尤其在它和BigTable都包含有“table”和“base”两个倾向于容易和关系型数据库混淆的概念的时候。这篇文章旨在从概念上描述这些分布式存储系统。
术语解释
Google's BigTable Paper 清楚地解释了BigTable到底是什么:
Bigtable 是稀疏的,分布式的,可持久化的,多维的排序map。
map通过行key,列key和一个时间戳来建立索引,map中的每个值都是一个无意义的字节数组。
Hadoop wiki中的 HBaseArchitecture指出:
HBase使用一种十分类似于Bigtable的数据模型来存储贴了标签的行数据。行数据由一个可排序的key和任意数量的列组成。表格中存储的数据是稀疏的,所以同一个表中的行可以有十分迥异的列结构。
接下来,通过分开理解单个概念来构建整个概念框架:
map
HBase/BigTable逻辑上是一个 map. 例子如下:
{
"1": "x",
"zzzzz": "woot",
"xyz": "hello",
"aaaab": "world",
"aaaaa": "y"
}
persistent
仅仅表示数据可以在程序创建或被访问后可以持久地存储在文件等存储介质上。
distributed
HBase和BigTable都建立在分布式文件系统之上,所以文件可以存储在不同机器上。
HBase建立在Hadoop's Distributed File System (HDFS) 或者Amazon的 Simple Storage Service (S3)上, 而BigTable使用Google File System (GFS).
数据被复制在几个节点上来保证类似 RAID 系统中的容错性.
sorted
HBase/BigTable的key会严格地按照字母顺序排序.排序后的样子如下:
{
"1": "x",
"aaaaa": "y",
"aaaab": "world",
"xyz": "hello",
"zzzzz": "woot"
}
只有key会被排序,value不会。
multidimensional
如下面json串所示,map可以是多层的:
{
"1": {
"A": "x",
"B": "z"
},
"aaaaa": {
"A": "y",
"B": "w"
},
"aaaab": {
"A": "world",
"B": "ocean"
},
"xyz": {
"A": "hello",
"B": "there"
},
"zzzzz": {
"A": "woot",
"B": "1337"
}
}
列族花费是十分高的,因此提前确定好所有需要的列是个好的实践。"1"下面还有“A”,“B”,在这里我们称顶层的键值对“1”:{}为一行,“A”,“B”为列族(Column Families)。一个表格的列族在创建后就被确定了,之后很难或者说根本不可能更改。增加一个新的列族花费是十分高的,因此提前确定好所有需要的列是个好的实践。
一个列族可以有任意数量的列包括在内,列通过"qualifier"或者"label"来指定:
{
"aaaaa": {
"A": {
"foo": "y",
"bar": "d"
},
"B": {
"": "w"
}
},
"aaaab": {
"A": {
"foo": "world",
"bar": "domination"
},
"B": {
"": "ocean"
}
}
}
查询列时使用的格式"family:qualifier". 在这个例子中我们可以用: "A:foo", "A:bar" 还有"B:".如上所示, "A" 列族中有 "foo" 和"bar"两个列而 "B" 列族中只有一个由空字符串表示的 qualifier指示的列.
HBase/BigTable最后一个度是时间,所有的数据通过一个整形的时间戳或者你选择的一个整数来确定版本号,客户端插入数据时可以指定时间戳。看下面的例子:
{
"aaaaa": {
"A": {
"foo": {
15: "y",
4: "m"
},
"bar": {
15: "d",
}
},
"B": {
"": {
6: "w"
3: "o"
1: "w"
}
}
}
}
每个列族对于特定的单元(单元是指由行key,列族,列qualifier唯一确定的一个数据项)保留多少个版本有其自己的规则,多数情况下, 应用会直接询问某个特定单元的数据而不指定时间戳,这时HBase/BigTable将返回最新的版本,如果应用程序有指定时间戳,那么HBase将返回时间戳小于等于给定时间戳的数据。例如查询"aaaaa"/"A:foo"将返回 "y" ,查询"aaaaa"/"A:foo"/10 返回 "m". 查询"aaaaa"/"A:foo"/2 返回null.
sparse
因为每行的列族里可以任意数量的列数,甚至根本没有列,以及行之间的gaps,导致了数据的存储是稀疏的。
还可参考:
表结构:
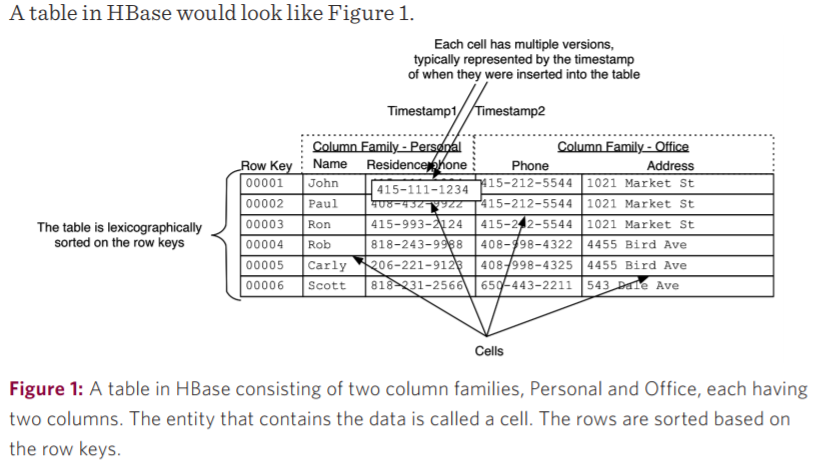
多维度:
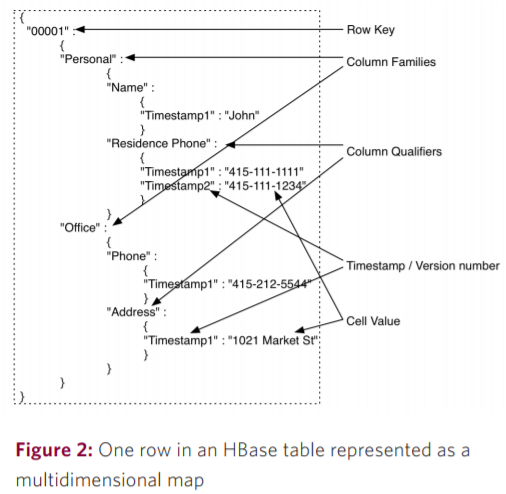
根据你感兴趣的值指定查询key:

HBase Table Design Fundamentals
设计原则可以转化为解决以下几个问题:
1. 行key的结构应该是怎样,应该包括什么?
2. 表应该有多少个列族?
3. 哪些数据应该归到哪个列族?
4. 每个列族应该有多少列?
5. 每列的名字? 尽管在列的名字在表创建时可以不指定,但是你在读写的时候需要知道要涉及哪些列。
6. 单元里应该保存哪些信息?
7. 每个单元对应多少个版本?
设计HBase表最重要的就是确定row-key结构.而为了更有效率的确定, 需要考虑的重要项有:
1.仅仅支持通过key索引.
2. 表格通过行key排序,表格中每一块区域的数据对应一段key区域.
3. 表格中所有数据都是用字节数组存储的,没有类型可言.
4. 原子性只保证到了行级别,这意味着没有跨行事务.
5. 列族必须在创建表格的时候进行定义.
6. 列的qualifiers是动态的,可以在写的时候定义。它们以字节数组存储,所以你甚至可以在里面存放数字.
7.列族和列标签的长度会影响I/O负载和网络带宽.