启动Hadoop
start-all.sh
把本地文件上传到hdfs文件系统,然后查看(之前已经把下载的英文小说上传到hdfs了)
usr/local/hadoop/bin/hdfs dfs -put ~/wc/w.txt /user/hadoop/input
usr/local/hadoop/bin/hdfs dfs -ls input
启动hive
hive
建个表text
create table text(line string);
把hdfs文件系统中input文件夹里的文本文件load进去,写hiveQL命令统计
load data inpath 'input' overwrite into table text; create table word_count as select word,count(1) as count from (select explode(split(line,' '))as word from text) w group by word order by word;
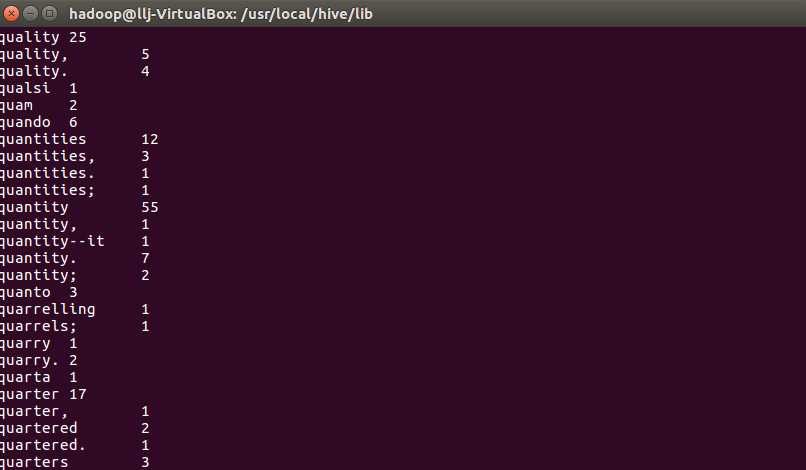
使用select命令查看结果

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
我爬取的是ImportNew网站里的文章然后进行词频统计后放到jieba.csv文件中:
先把爬取的文件上传到邮箱,然后在虚拟机上下载并放到本地的wc文件中:
启动hadoop:
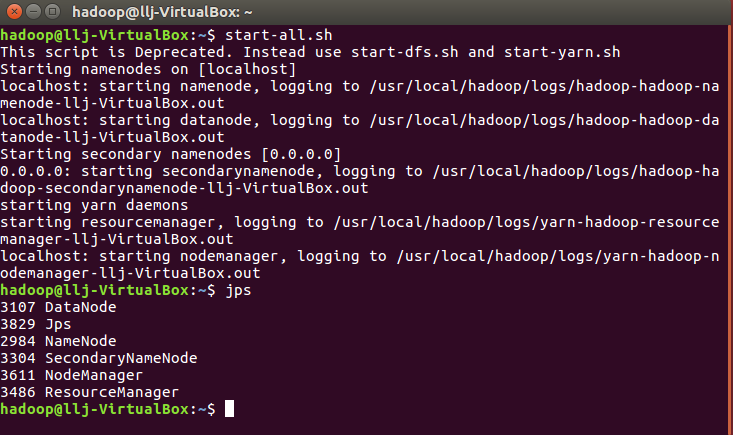
将本地系统wc文件夹里的books.csv上传至hdfs文件系统中:

启动hive:

对csv文件转换为txt文件

建个表text2

把hdfs文件系统中input文件夹里的文本文件load进去,写hiveQL命令统计

使用select命令查看结果