redis进阶
1.SpringBoot集成Redis
(1)创建SpringBoot工程,勾选Nosql
(2)配置连接参数
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai
username: root
password: ok
driver-class-name: com.mysql.jdbc.Driver
redis:
port: 6379
host: 127.0.0.1
(3)创建测试方法Demo2ApplicationTests-测试字符串
@SpringBootTest class Demo2ApplicationTests { @Autowired private RedisTemplate redisTemplate; @Test void contextLoads() { redisTemplate.opsForValue().set("name66","zs"); System.out.println(redisTemplate.opsForValue().get("name66")); } }
(4)创建实体类
Student
(5)创建测试方法Demo2ApplicationTests-测试对象
@Test public void test()throws Exception{ User user = new User("中博",777); redisTemplate.opsForValue().set("user",user); System.out.println(redisTemplate.opsForValue().get("user")); }
(6)RedisConfig
@Configuration public class RedisConfig { @Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<String, Object>(); template.setConnectionFactory(factory); Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // key采用String的序列化方式 template.setKeySerializer(stringRedisSerializer); // hash的key也采用String的序列化方式 template.setHashKeySerializer(stringRedisSerializer); // value序列化方式采用jackson template.setValueSerializer(jackson2JsonRedisSerializer); // hash的value序列化方式采用jackson template.setHashValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } }
(7)测试方法Demo2ApplicationTests-测试序列化
public class RedisConfig { @Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<String, Object>(); template.setConnectionFactory(factory); Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // key采用String的序列化方式 template.setKeySerializer(stringRedisSerializer); // hash的key也采用String的序列化方式 template.setHashKeySerializer(stringRedisSerializer); // value序列化方式采用jackson template.setValueSerializer(jackson2JsonRedisSerializer); // hash的value序列化方式采用jackson template.setHashValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } }
(8)企业级使用RedisUtil工具类
https://www.cnblogs.com/gnos/p/13609119.html
(9)创建测试方法塞值取值
@Test public void test2()throws Exception{ redisUtil.set("name","sh"); System.out.println(redisUtil.get("name")); }
(10)测试增删改查
@RestController public class UserController { @Autowired private UserMapper userMapper; @Resource private RedisUtil redisUtil; @PostMapping("/set") public void set(@RequestBody User user){ redisUtil.set("user",user); } @PostMapping("/get/{key}") public User get(@PathVariable("key")String key){ return (User) redisUtil.get(key); } @PostMapping("/delete/{key}") public void delete(@PathVariable("key")String key){ redisUtil.del("user"); } @PostMapping("/findAll") public List<User> findAll(){ List<User> list = (List<User>)redisUtil.get("users"); if(list ==null){ list = userMapper.findAll(); redisUtil.set("users",list); } return list; } }
2.Redis持久化
(1) 背景
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失,所以Redis提供了持久化功能.
(2)RDB持久化(Redis DataBase)
① 定义
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了。再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。这就确保了极高的性能。
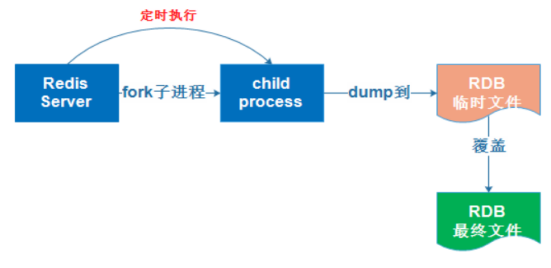
② 优点 适合大规模的数据恢复
对数据完整性要求不高
③ 缺点 需要一定时间间隔来进行进程操作!如果redis以外宕机了,最后一次修改的数据就
没有了!
fork进程的时候,会占用一定的内存空间!
(3)AOF持久化(Append only File)
① 定义
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
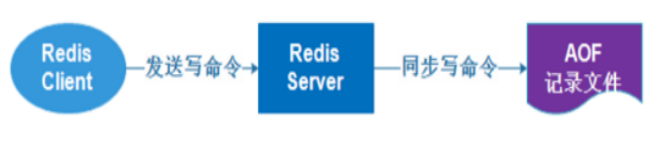
② 优点 AOF可以一次更好地保护数据不丢失,一般AOF会以每隔一秒,通过后台的一个进程进行一次fsync操作,如果redis进程丢失,最多丢失1秒的数据;
AOF以appenf-only的模式读写,所以没有任何磁盘寻址的开销,写入性能高;
AOF日志文件的命令通过非常可读的方式进行记录,这个非常适合做灾难性的误删除的紧急恢复,如果某人不小心用福禄寿命令清空了所有的数据,只要这个时候还没有执行rewrite,那么就可以将日志文件中的福禄寿删除,进行恢复。
③ 缺点 相对于数据文件来说,AOF远远大于RDB,修复的速度也比RDB慢!
AOF运行效率也比RDF慢,所以我们用Redis默认的配置就是RDB持久化!
3.哨兵模式
(1)什么是哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,非常费时间费力气,还会造成一段时间内服务不可用,所以我们推荐优先考虑哨兵模式。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
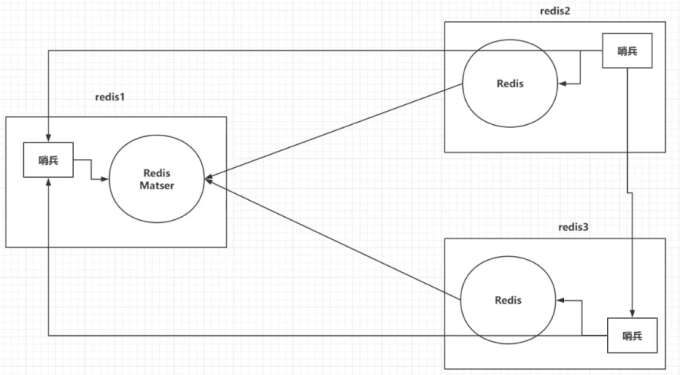
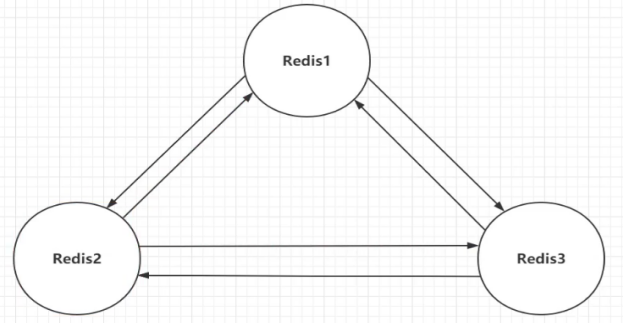
(2)优点
① 哨兵集群,基于主从赋值模式;
② 主从可以切换,故障可以转移,系统的可用性比较好;
③ 哨兵模式就是主从模式的升级,手动到自动,更加健壮。
(3)缺点
① Redis不好在线扩容,集群容量一旦达到上限,在线扩容比较麻烦;
② 实现哨兵机制的配置非常麻烦。
4.Redis缓存击穿与雪崩(服务器的高可用)
Redis缓存的使用,极大的提高了效率,但是要有一些问题,例如数据的一致性问题,这个问题没有办法解决。如果对数据的一致性要求很高,那么就不能使用缓存。
(1)缓存穿透(查不到导致)
① 定义
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库,这会给持久层数据库造成很大的压力,这时候相当于出现了缓存穿透。

② 现象
系统平稳运行的过程中: 应用服务器流量随时间增量增大;
Redis服务器命中率随时间逐步降低;
Redis内存平稳,内存无压力;
Redis服务器CPU占用激增
数据库奔溃
③ 解决方案 布隆过滤器
缓存空对象
(2)缓存击穿(某个key过期,并且该key访问量巨大!)
① 定义
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,会导致数据库瞬间压力过大。
② 现象
系统平稳运行的过程中: 数据库连接量突然激增;
Redis服务器无大量key过期;
Redis内存平稳,无波动;
Redis服务器CPU正常;
数据库奔溃!
③ 解决方案 设置热点数据永不过期:
从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后产生的问题
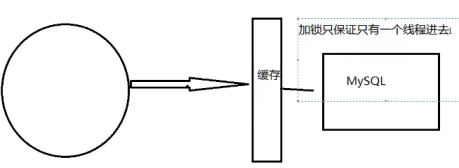
加互斥锁:
分布式锁:使用分布式锁,保证对于每一个key同时只有一个线程去查询够短服务,其他线程没有获得分布式锁的权限,
因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,一次对分布式锁的考验很大!
(3)缓存雪崩(短时间内,缓存中较多的key集中过期)
① 定义
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
② 现象
系统平稳运行的过程中: 数据库连接量激增;
应用服务器无法及时处理请求;
大量404,500错误页面出现;
用户答复刷新页面获取数据;
数据开崩溃;
应用服务器崩溃;
重启应用服务器无效;
Redis服务器崩溃;
Redis集群崩溃;
重启数据库后致辞被瞬间流量击崩!
③ 解决方案 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象的发生
如果缓存数据是分布式部署,将热点数据均匀分布在不同的缓存数据库中
设置热点数据永远不过期
(4)常见企业级解决方案
① Redis集群
如果一台挂掉之后还可以继续工作。
② 限流降级
缓存失效后,通过枷锁或队列来读取数据库写缓存的线程数量。例如,对某个key只允许一个线程查询数据和写缓存,其他线程等待。
③ 缓存预热
缓存预热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中,
在即将发生大规模并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。