python爬虫
1 利用pip引入相关库
from bs4 import BeautifulSoup
import requests
2 构建请求
以某网站为例,此为post请求,根据目标网站而定
headers = {'Host': 'xxxxx',
'Origin':'xxxxx',
'Content-Type':'xxxx',
'Origin': 'xxxx',
'Referer': ',
'User-Agent': 'xxxxxxx',
'X-Requested-With': 'xxxxx'
}
content = {'m': 'xflist',
'city': 'wf',
'district': ''}
url='xxxxx';
res = requests.post(url, data=content, headers=headers)
3 解析网页结果
soup = BeautifulSoup(html, "html.parser")
list = soup.select('body > div.main > section.mBox.mb8.dtbk > div > ul ')
for i in list:
lilist = i.find_all("li")
for j in lilist:
create_time = j.select("div.time")[0].getText()
print(create_time)
content = j.select("h4")[0].getText()
print(content)
json = {"createTime": create_time,"content":content}
jsonArray.append(json)
经python爬虫爬出数据,包含时间格式截取部分如下
json={
"floor_area": "57535 ㎡",
"building_area": "250000 ㎡",
"volume_rate": "3.78",
"greening_rate": "30%",
"parking_rate": "项目规划车位数量为1889个",
"record": [
{
"createTime": "2018-11-20 11:03:33",
"content": "新瑞都"
},
{
"createTime": "2020-12-31",
"content": "3号楼"
},
{
"createTime": "2018-11-03",
"content": "3号楼"
},
}
4引入elasticsearch库,确保elasticsearch为启动状态
from e import Elasticsearch
from fang import make_request1
es = Elasticsearch([{'host':'127.0.0.1','port':9200}])
json = make_request1()
es.index(index="house_test",doc_type="fang",body = json)
运行后报错信息如下

显然虽然json 爬取为字符串,但是上传到elasticsearch,被识别为日期格式
于是elasticsearch创建索引时即规定type.
5 elasticsearch创建索引,具体实现代码如下
from elasticsearch import Elasticsearch
es = Elasticsearch('192.168.1.1:9200')
mappings = {
"mappings": {
"fang": {
"properties": {
},"open_time": {
"type": "keyword",
"index": "false"
},"volume_rate": {
"type": "keyword",
"index": "false"
},"greening_rate": {
"type": "keyword",
"index": "false"
},"parking_rate": {
"type": "keyword",
"index": "false"
},"house_type": {
"type": "keyword",
"index": "false"
},
"property_company": {
"type": "keyword",
"index": "false"
},
# tags可以存json格式,访问tags.content
"projectComment": {
"type": "object",
"properties": {
"createTime": {"type": "keyword", "index": False},
"content": {"type": "keyword", "index": False},
}
},
}
}
}
}
res = es.indices.create(index = 'index_test',body =mappings)
将数据连续插入
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
es = Elasticsearch('192.168.1.1:9200')
ACTIONS = []
json1 ={
"floor_area": "57535 ㎡",
"building_area": "250000 ㎡",
"volume_rate": "3.78",
"greening_rate": "30%",
"parking_rate": "项目规划车位数量为1889个",
"record": [
{
"createTime": "2018-11-20 11:03:33",
"content": "新瑞都"
},
{
"createTime": "2020-12-31",
"content": "3号楼"
},
{
"createTime": "2018-11-03",
"content": "3号楼"
},
}
json2 ={
"floor_area": "354345 ㎡",
"building_area": "234500 ㎡",
"volume_rate": "453",
"greening_rate": "43%",
"parking_rate": "项目规划车位数量为1889个",
"record": [
{
"createTime": "2018-11-20 11:03:33",
"content": "新瑞都"
},
{
"createTime": "2020-12-31",
"content": "3号楼"
},
{
"createTime": "2018-11-03",
"content": "3号楼"
},
}
}
ACTIONS.append(json1)
ACTIONS.append(json2)
res,_ =bulk(es, ACTIONS, index="indes_test", raise_on_error=True)
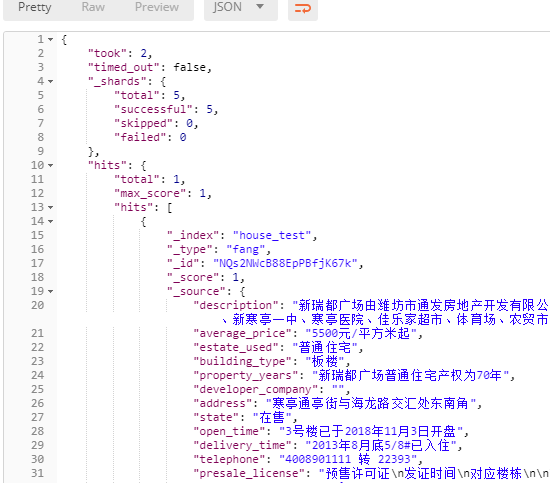
5 查询索引
通过postman发送请求

查询到结果