背景
昨天公司业务部门报告业务崩溃,查看各个业务节点后,定位问题到storm集群。
打开storm ui查看下任务状态,发现可以加载页面元素,但是无法加载数据,分析是nimbus挂掉了,重启nimbus。本着先恢复业务的原则,我直接通过命令行停止任务后,又重新提交了任务,这个时候访问storm ui发现业务系统已经恢复正常。业务系统虽然恢复了,但是需要找到问题的根本原因,才能确保不再发生。
storm部署情况
公司的生产环境部署的storm集群,其中,zookeeper和nimbus都是单点,supervisor也只部署了一个,每个supervisor开启四个slot,这几个关键组件都部署在了一台物理服务器上。
storm任务,会启动两个worker,一共12个线程,分布在这台物理机上,查看storm ui可以看到,启动了两个worker,端口分别为6700和6701,每一个worker负责六个线程。
问题分析
业务层
查看业务系统日志,发现8月3日9点51开始就不正常了,表现为不生产正确的业务事件。
看8月3号以后的业务日志,没有异常的error,说明问题不是出在业务层,继续看storm层。
storm层
nimbus日志
因为前面已知nimbus因为某种原因挂掉了,所以先看nimbus日志,$STORM_HOME/logs/nimbus.log日志如下:
2020-07-31 10:14:57.523 o.a.s.z.Zookeeper main-EventThread [INFO] active-topology-blobs [startstorm-10-1592659649] local-topology-blobs [startstorm-10-1592659649-stormconf.ser,startstorm-10-1592659649-stormjar.jar,startstorm-10-1592659649-stormcode.ser] diff-topology-blobs []
2020-07-31 10:14:57.620 o.a.s.util timer [ERROR] Halting process: ("Error when processing an event")
java.lang.RuntimeException: ("Error when processing an event")
at org.apache.storm.util$exit_process_BANG_.doInvoke(util.clj:341) ~[storm-core-1.2.3.jar:1.2.3]
at clojure.lang.RestFn.invoke(RestFn.java:423) ~[clojure-1.7.0.jar:?]
at org.apache.storm.daemon.nimbus$nimbus_data$fn__8298.invoke(nimbus.clj:221) ~[storm-core-1.2.3.jar:1.2.3]
at org.apache.storm.timer$mk_timer$fn__6387$fn__6388.invoke(timer.clj:71) ~[storm-core-1.2.3.jar:1.2.3]
at org.apache.storm.timer$mk_timer$fn__6387.invoke(timer.clj:42) ~[storm-core-1.2.3.jar:1.2.3]
at clojure.lang.AFn.run(AFn.java:22) ~[clojure-1.7.0.jar:?]
at java.lang.Thread.run(Thread.java:745) [?:1.8.0_121]
2020-07-31 10:14:57.697 o.a.s.z.Zookeeper main-EventThread [INFO] active-topology-dependencies [] local-blobs [startstorm-10-1592659649-stormconf.ser,startstorm-10-1592659649-stormjar.jar,startstorm-10-1592659649-stormcode.ser] diff-topology-dependencies []
2020-07-31 10:14:57.697 o.a.s.z.Zookeeper main-EventThread [INFO] Accepting leadership, all active topologies and corresponding dependencies found locally.
2020-07-31 10:14:58.106 o.a.s.d.nimbus Thread-7 [INFO] Shutting down master
最后一行,Shutting down master,代表nimbus挂了。
supervisor日志
看supervisor的日志,$STORM_HOME/logs/supervisor.log
查看对应时段的日志信息,可以看到,首先是因为clientsession有87007ms没有接收到server的信息,所以触发了timeout处理机制。
2020-07-31 10:14:20.885 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [WARN] Client session timed out, have not heard from server in 87077ms for sessionid 0x105876332810086
第二步kill了worker
2020-07-31 10:14:53.914 o.a.s.d.s.Container SLOT_6702 [INFO] Killing 923112bb-4901-4d63-a93e-900e8fb7110e:0c453b60-2eaf-48ab-8c2a-0f7c267dbad5
第三步修改业务thread的状态
2020-07-31 10:14:54.363 o.a.s.s.o.a.c.f.s.ConnectionStateManager main-EventThread [INFO] State change: SUSPENDED
第四步,重连,发现失败,线程状态修改为LOST
2020-07-31 10:14:56.820 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [INFO] Opening socket connection to server 10.43.4.153/10.43.4.153:2181. Will not attempt to authenticate using SASL (unknown error)
2020-07-31 10:14:56.980 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [INFO] Socket connection established to 10.43.4.153/10.43.4.153:2181, initiating session
2020-07-31 10:14:57.015 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [WARN] Unable to reconnect to ZooKeeper service, session 0x105876332810086 has expired
2020-07-31 10:14:57.021 o.a.s.s.o.a.c.ConnectionState main-EventThread [WARN] Session expired event received
2020-07-31 10:14:57.187 o.a.s.s.o.a.c.f.s.ConnectionStateManager main-EventThread [INFO] State change: LOST
2020-07-31 10:14:57.194 o.a.s.s.o.a.z.ClientCnxn main-EventThread [INFO] EventThread shut down for session: 0x105876332810086
第五步,重连成功后,修改线程状态为RECONNECTED,清理原来worker的信息,并建立新的worker
2020-07-31 10:14:57.241 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [INFO] Opening socket connection to server 10.43.4.153/10.43.4.153:2181. Will not attempt to authenticate using SASL (unknown error)
2020-07-31 10:14:57.242 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [INFO] Socket connection established to 10.43.4.153/10.43.4.153:2181, initiating session
2020-07-31 10:14:57.245 o.a.s.s.o.a.z.ClientCnxn main-SendThread(10.43.4.153:2181) [INFO] Session establishment complete on server 10.43.4.153/10.43.4.153:2181, sessionid = 0x105876332810095, negotiated timeout = 20000
2020-07-31 10:14:57.277 o.a.s.s.o.a.c.f.s.ConnectionStateManager main-EventThread [INFO] State change: RECONNECTED
2020-07-31 10:15:01.983 o.a.s.d.s.Container SLOT_6700 [INFO] Cleaning up 923112bb-4901-4d63-a93e-900e8fb7110e:f1ede737-d405-44a5-a19e-eb4979cfd338
2020-07-31 10:15:03.183 o.a.s.d.s.Container SLOT_6702 [INFO] REMOVE worker-user 0c453b60-2eaf-48ab-8c2a-0f7c267dbad5
2020-07-31 10:15:03.437 o.a.s.d.s.BasicContainer SLOT_6702 [INFO] Created Worker ID 22b3823d-c03c-4593-aaac-f9ae6f5e4e1d
分析到现在还是没有头绪。
暂时的解决方案
我们只能假设是nimbus异常宕机导致后续的问题。
解决方案是:
-
引入daemontools监控工具,来监控nimbus和supervisor,在挂掉后自动恢复。
-
引入新的机器,增加supervisor物理节点,看下是否可以解决问题。
增加物理节点
除了按照常规步骤安装部署以外,启动nimbus和supervisor的时候,需要指定一下hostname的参数,防止出现其他supervisor的机器找不到nimbus主机的问题。
以在10.43.4.153和10.43.4.151上启动两个supervisor,在10.43.4.153上启动nimbus为例
nohup /usr/local/apache-storm-1.2.3/bin/storm nimbus -c storm.local.hostname="10.43.4.153" &
nohup /usr/local/apache-storm-1.2.3/bin/storm supervisor -c storm.local.hostname="10.43.4.153" &
nohup /usr/local/apache-storm-1.2.3/bin/storm supervisor -c storm.local.hostname="10.43.4.151" &
成功部署后,如图所示
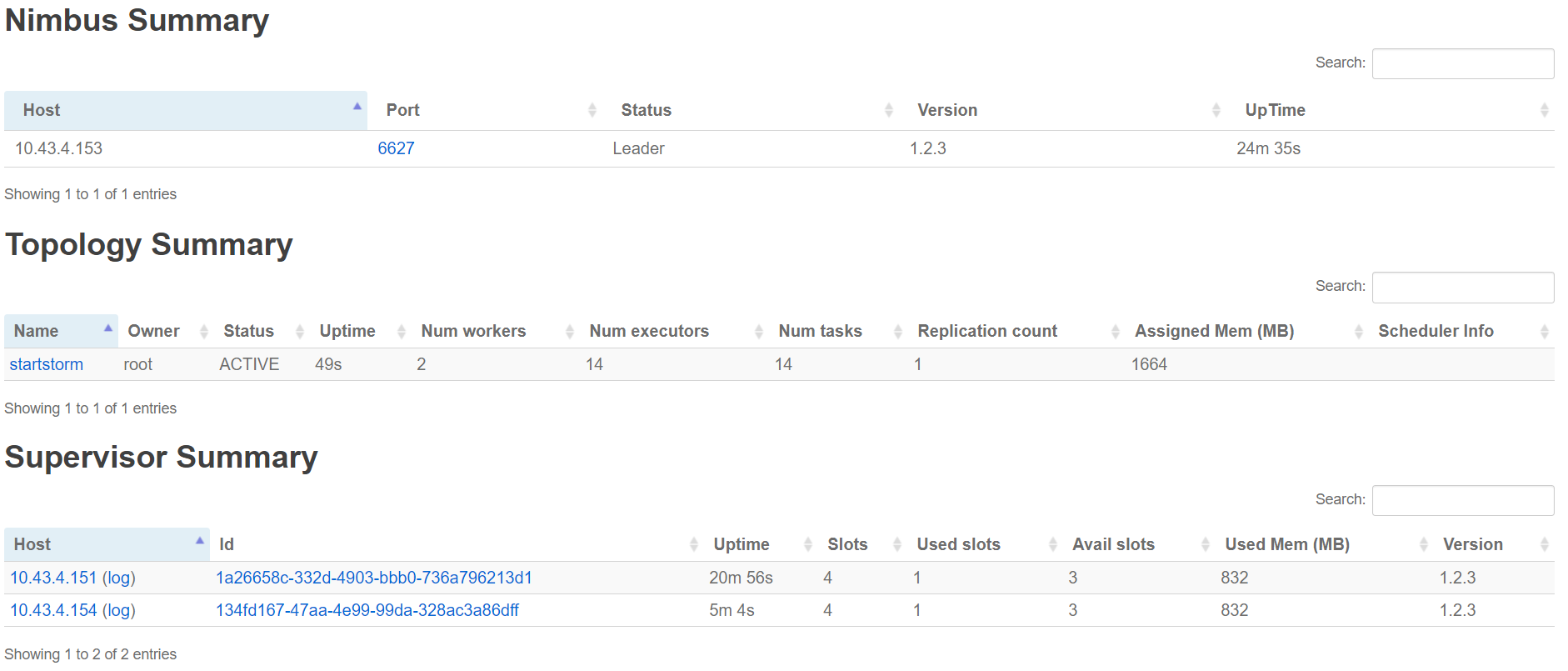
部署常见问题:https://www.iteye.com/blog/wangmengbk-2215140
damentools工具部署使用
安装部署
-
创建
/packagemkdir -p /package chmod 1755 /package cd /package -
下载 daemontools-0.76.tar.gz
/packagegunzip daemontools-0.76.tar tar -xpf daemontools-0.76.tar rm -f daemontools-0.76.tar cd admin/daemontools-0.76 -
编辑 src/conf-cc 在最后加入
-include /usr/include/errno.h -
编译
package/install -
启动
首先在"/etc/init"目录下创建一个svscan.conf文件 ,然后在文件中添加如下内容保存:
start on runlevel [345] respawn exec /command/svscanboot其次分别执行如下两个命令重新加载"/etc/init"目录下的配置文件,执行ps命令查看是否启动成功
[root@rfidweb init]# initctl reload-configuration [root@rfidweb init]# initctl start svscan svscan start/running, process 32735 [root@rfidweb init]# ps -ef | grep svs root 32735 1 0 13:56 ? 00:00:00 /bin/sh /command/svscanboot root 32737 32735 0 13:56 ? 00:00:00 svscan /service root 32758 8815 0 13:56 pts/0 00:00:00 grep svs -
编写脚本
#! /bin/bash mkdir -p /service/storm/nimbus touch /service/storm/nimbus/run chmod +x /service/storm/nimbus/run mkdir -p /service/storm/ui touch /service/storm/ui/run chmod +x /service/storm/ui/run mkdir -p /service/storm/supervisor touch /service/storm/supervisor/run chmod +x /service/storm/supervisor/run添加内容:
#! /bin/bash exec 2>&1 exec /usr/local/apache-storm-1.2.3/bin/storm ui#! /bin/bash exec 2>&1 exec /usr/local/apache-storm-1.2.3/bin/storm nimbus -c storm.local.hostname="10.43.4.153" -
验证是否生效
ps -ef | grep "nimbus"
然后kill -9
再次ps命令查看pid已经改变