Python函数2
1、函数的基本类型

2、全局变量和局部变量
- 局部变量 就是在函数内部定义的变量(作用域仅仅在函数内部);
- 不同的函数可以定义相同的局部变量,互不影响。
- 作用:为了临时的保存数据,需要在函数中定义来进行存储
# 这里的name就是局部变量 def printInfo(): name='hubert' print(name) pass def TestMethod(): name='刘德华' print(name) pass TestMethod() printInfo()
全局变量:与局部变量的区别就是作用域的不同;
# 全局变量 pro='计算机技术' # 这是一个全局变量 name='ALEX' # 当全局变量和局部变量相同的时候,程序会优先执行函数内部定义的局部变量(强龙不压地头蛇) def printInfo(): name='hubert' print(name,pro) pass def TestMethod(): # name='刘德华' print(name,pro) pass TestMethod() printInfo()
修改全局变量
如果在函数的内部想要修改全局变量,必须用global先进行声明。
# 修改全局变量 pro='计算机技术' # 这是一个全局变量 name='ALEX' # 当全局变量和局部变量相同的时候,程序会优先执行函数内部定义的局部变量(强龙不压地头蛇) def printInfo(): name='hubert' print(name,pro) pass def TestMethod(): # name='刘德华' print(name,pro) pass def changeGlobal(): ''' 想要修改全局变量 :return: ''' # pro='信息管理与信息系统' # 局部变量,无法修改全局变量,需要global先定义一下 global pro pro = '信息管理与信息系统' pass changeGlobal() print(pro) TestMethod() printInfo()

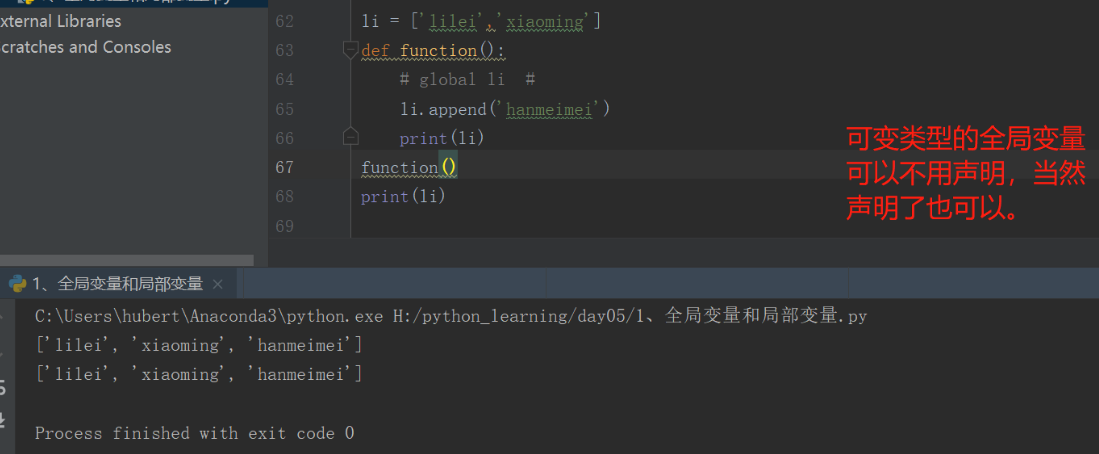
3、函数参数的引用传值
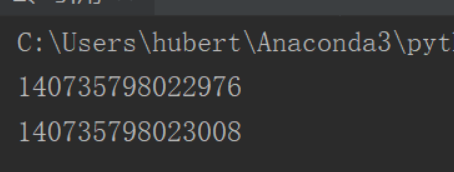
在python中,值是靠引用来传递来的,可以用id()查看一个对象的引用是否相同,id是值保存在内存中那块内存地址的标识。
a=1 print(id(a)) a=2 print(id(a)) # 撕掉1上面的变量a标签,然后贴到2上面(变量本身并不传递信息)
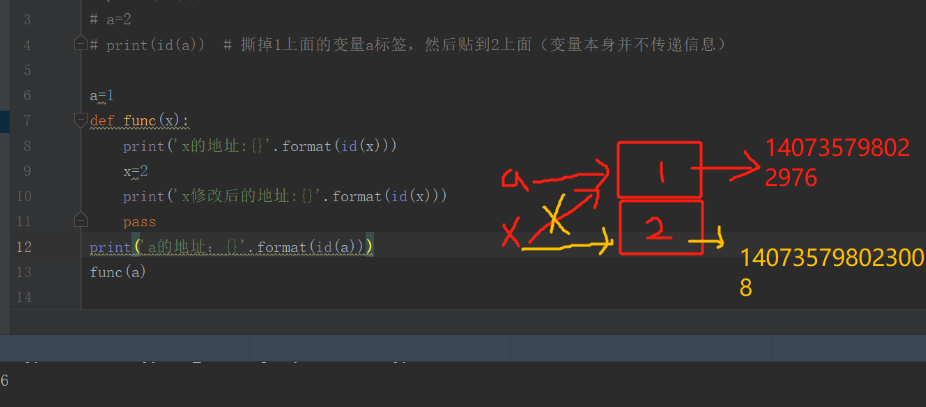
传递的是对象的引用,而不是值
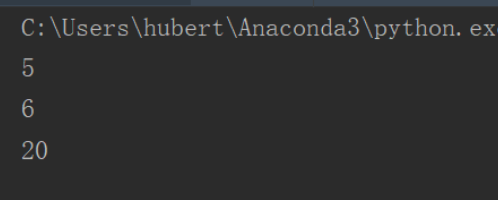
a=1 def func(x): print('x的地址:{}'.format(id(x))) pass print('a的地址:{}'.format(id(a))) func(a)

# 可变类型 li=[] def testC(parms): li.append([1,2,3,4,5]) print(id(parms)) print('内部的变量对象{}'.format(parms)) pass print(id(li)) testC(li) print('外部的变量对象{}'.format(li))

小结:
- 在python中,万物皆对象,,在函数调用的时候,实参传递的就是对象的引用;
- 了解了原理,就可以更好地把控在函数内部处理是否会影响到函数内部数据的变换;
- 参数得传递就是通过对象引用来完成的。
4、匿名函数(没有名字的函数)
- python中使用
lambda关键字创建匿名函数,所谓匿名即这个函数没有名字不用def关键字创建标准的函数。 - 格式
lambda 参数1,参数2,参数3: 执行代码语句 - 为了满足简单的逻辑,复杂逻辑还是需要def来定义
test=lambda x,y:x+y print(test(1,3)) print(test(2,4)) # print(test(2,4,6)) # 报错,多了一个参数

# 找最大值 greater = (lambda x, y: x if x > y else y) print(greater(3, 5)) print(greater(6, 2)) rs = (lambda x, y: x if x > y else y)(10,20) # 直接调用 print(rs)
5、递归函数
- 如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
- 递归函数必须有一个结束条件,否则递归无法结束会一直递归下去,只到到达最大递归深度报错。
举例:
# 求阶乘 # 1、普通方法,循环来实现 def jiecheng(n): result=1 for i in range(1,n+1): result*=i pass return result print(jiecheng(5)) # 2、递归方法 def factorial(n): if n == 1: return 1 return n * factorial(n-1) print(factorial(5))

优点:
- 递归使代码看起来更加整洁、优雅
- 可以用递归将复杂任务分解成更简单的子问题
- 使用递归比使用一些嵌套迭代更容易
缺点:
- 递归逻辑很难调试,递归条件处理不好容易造成程序无法结束,直到达到最大递归错误。
- 递归占用大量内存,耗费计算机资源。
案例:模拟实现树形结构的遍历(文件的搜索)
#递归例子 模拟实现树形结构文件的遍历 import os #引入文件操作模块 def find_file(file_path): listRs=os.listdir(file_path) #得到该路径下所有文件夹 for fileItem in listRs: full_path=os.path.join(file_path,fileItem) #获取完整的文件路径 if os.path.isdir(full_path): #判断是否是文件夹 find_file(full_path) #如果是,继续递归 pass else: print(fileItem) pass pass else: return pass find_file('F:\项目管理') #填写自己电脑的路径名