使用方法
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
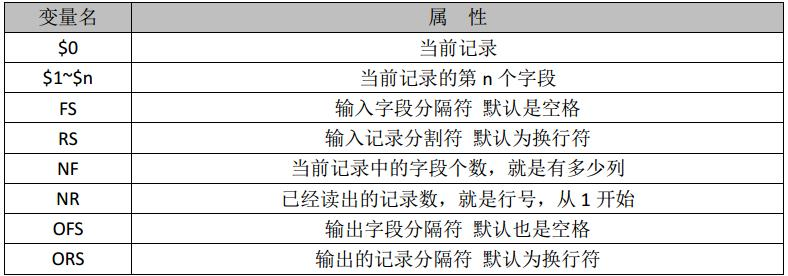

$0 代表整行,输出时输出整行内容; $1 代表第一个字段; NR 代表行数,从1开始,当输出第一行时,采用NR==1; NF 代表字段数(可以说是列数),从1开始;
输出了文件中的所有行,$0代表输出整行,不代表输出第一行,输出第一行采用NR==1 [root@Gin scripts]# awk '{print $0}' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin .....................................................
输出第一行 [root@zhang ~]# awk '{if(NR==1) print $0}' /etc/passwd root:x:0:0:root:/root:/bin/bash 输出第20-30行 [root@Gin scripts]# awk '{if(NR>=20 && NR<=30) print $1}' test.txt 20 21 22 23 24 25 26 27 28 29 30
awk按照行处理,对于下例,不再输出行本身的内容;而是,针对每一行输出hiya;可以用来对满足某种条件的行,输出自己特定制定的内容 [root@Gin scripts]# awk '{print "hiya"}' /etc/passwd hiya hiya hiya hiya ...............................................
-F参数指定分隔符,下列是以冒号:分隔处理; 当行满足指定条件时,输出True;不满足,输出Flase. [root@zhang ~]# cat qs.txt apple:5 orange:6 banana:3 strawberry:8 cherry:15 [root@zhang ~]# awk -F: '{if($2>=6){print "True"}else{print "False"}}' qs.txt False True False True True
-F":"可以简写为-F: [root@zhangchao ~]# cat zc.log root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@zhangchao ~]# awk -F":" '{ print $1 }' zc.log root operator [root@zhangchao ~]# awk -F":" '{ print $1 $3}' zc.log root0 operator11 [root@zhangchao ~]# awk -F":" '{ print $1 " " $3}' zc.log root 0 operator 11 [root@zhangchao ~]# awk -F":" '{ print "Username:"$1 " UID:" $3}' zc.log Username:root UID:0 Username:operator UID:11
-F参数:指定分隔符,可指定一个或多个 下例:-F指定了空格和逗号分隔符,+ 号代表匹配分隔符1个或者1个以上; '[ ,]+'不可以写成'[,]+';逗号前有个空格; 意思是将I am Poe,my qq is 33794712以空格或者逗号进行分隔字段,并输出第3、7字段; 从该文件中过滤出'Poe'字符串与33794712,最后输出的结果为:Poe 33794712 [root@Gin scripts]# cat test.txt I am Poe,my qq is 33794712 [root@Gin scripts]# awk -F '[ ,]+' '{print $3" "$7}' test.txt Poe 33794712
BEGIN 和 END 模块 通常,对于每个输入行, awk 都会执行每个脚本代码块一次。然而,在许多编程情况中,可能需要在 awk 开始处理输入文件中的文本之前执行初始化代码。对于这种情况, awk 允许您定义一个 BEGIN 块。 因为 awk 在开始处理输入文件之前会执行 BEGIN 块,因此它是初始化 FS(字段分隔符)变量、打印页眉或初始化其它在程序中以后会引用的全局变量的极佳位置。 awk 还提供了另一个特殊块,叫作 END 块。 awk 在处理了输入文件中的所有行之后执行这个块。通常, END 块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。 实例一:统计/etc/passwd的账户人数,count表示计算行数,每处理一行加1; 对passwd文件中每一行执行{count++;print $0;},执行完文件的所有行之后,最后在执行{print "user count is ",count}'。
[root@Gin scripts]# awk '{count++;print $0;} END{print "user count is ",count}' passwd root:x:0:0:root:/root:/bin/bash .............................................. user count is 27 count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0: 下例,在处理passwd文本内容行之前,先执行 'BEGIN {count=0;print "[start] user count is ",count}; 然后,对于passwd文件的每一行执行,{count=count+1;print $0}; 最后,处理完passwd文件中的所有行之后,在处理 END{print "[end] user count is ",count}'。
[root@Gin scripts]# awk 'BEGIN {count=0;print "[start] user count is ",count} {count=count+1;print $0} END{print "[end] user count is ",count}' passwd [start] user count is 0 root:x:0:0:root:/root:/bin/bash ................................................................... [end] user count is 27
实例二:统计某个文件夹下的文件占用的字节数 [root@Gin scripts]# ll |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ",size}' [end]size is 1489 如果以M为单位显示: [root@Gin scripts]# ll |awk 'BEGIN{size=0;} {size=size+$5;} END{print "[end]size is ",size/1024/1024,"M"}' [end]size is 0.00142002 M
以一个或者多个tab分隔符
[root@zhangchao ~]# cat tab.txt www baidu com [root@zhangchao ~]# awk -F "[ ]+" '{print $1,$2,$3}' tab.txt www baidu com [root@zhangchao ~]# awk -F " +" '{print $1,$2,$3}' tab.txt www baidu com [root@zhangchao ~]# awk 'BEGIN{FS=" +"}{print $1,$2,$3}' tab.txt www baidu com
以空格分隔 [root@zhangchao ~]# cat space.txt we are eating apples now ! [root@zhangchao ~]# awk -F" " '{print $1,$2,$3,$4,$5,$6}' space.txt we are eating apples now ! [root@zhangchao ~]# awk -F "[ ]+" '{print $1,$2,$3,$4,$5,$6}' space.txt we are eating apples now ! FS="[" ":]+" 以一个或多个空格或:分隔 [root@Gin scripts]# cat hello.txt root:x:0:0:root:/root:/bin/bash [root@Gin scripts]# awk -F [" ":]+ '{print $1,$2,$3}' hello.txt root x 0 字段数量 NF [root@Gin scripts]# cat hello.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin:888 [root@Gin scripts]# awk -F ":" 'NF==8{print $0}' hello.txt bin:x:1:1:bin:/bin:/sbin/nologin:888 记录数量 NR,取第2行 [root@Gin scripts]# ifconfig eth0|awk -F [" ":]+ 'NR==2{print $4}' ## NR==2也就是取第2行 192.168.17.129
RS 记录分隔符变量 将 FS 设置成" "告诉 awk 每个字段都占据一行。通过将 RS 设置成"",还会告诉 awk每个地址记录都由空白行分隔。
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
[root@Gin scripts]# cat recode.txt Jimmy the Weasel 100 Pleasant Drive San Francisco,CA 123456 Big Tony 200 Incognito Ave. Suburbia,WA 64890 [root@Gin scripts]# cat awk.txt #!/bin/awk BEGIN { FS=" " RS="" } { print $1","$2","$3 } [root@Gin scripts]# awk -f awk.txt recode.txt Jimmy the Weasel,100 Pleasant Drive,San Francisco,CA 123456
Big Tony,200 Incognito Ave.,Suburbia,WA 64890
OFS 输出字段分隔符 [root@Gin scripts]# cat hello.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin:888 [root@Gin scripts]# awk 'BEGIN{FS=":"}{print $1","$2","$3}' hello.txt root,x,0 bin,x,1 [root@Gin scripts]# awk 'BEGIN{FS=":";OFS="#"}{print $1,$2,$3}' hello.txt root#x#0 bin#x#1
ORS 输出记录分隔符 [root@Gin scripts]# cat recode.txt Jimmy the Weasel 100 Pleasant Drive San Francisco,CA 123456 Big Tony 200 Incognito Ave. Suburbia,WA 64890 [root@Gin scripts]# cat awk.txt #!/bin/awk BEGIN { FS=" " RS="" ORS=" " } { print $1","$2","$3 } [root@Gin scripts]# awk -f awk.txt recode.txt Jimmy the Weasel,100 Pleasant Drive,San Francisco,CA 123456 Big Tony,200 Incognito Ave.,Suburbia,WA 64890
[root@zhangchao ~]# cat recode.txt Jimmy the Weasel 100 Pleasant Drive San Francisco,CA 123456 Big Tony 200 Incognito Ave. Suburbia,WA 64890 [root@zhangchao ~]# cat awk.txt #!/bin/awk BEGIN { FS=" " 以换行符作为分隔字段 RS=" " 遇到空格,则处理上一个空格到这一个空格之间的内容 ORS="### " 输出每一行,并以### 结尾 } { print $1,$2,$3 } [root@zhangchao ~]# awk -f awk.txt recode.txt Jimmy ### the ### Weasel 100 ### Pleasant ### Drive San ### Francisco,CA ### 123456 ### Big ### Tony 200 ### Incognito ### Ave. Suburbia,WA ### 64890 ###
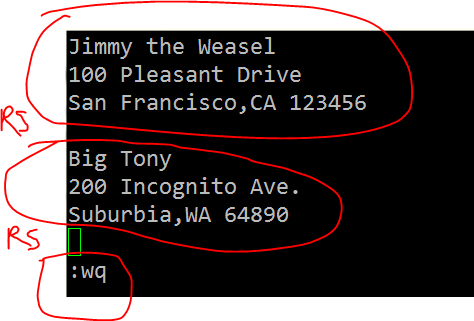
recode.txt
awk -f参数紧跟awk文件 [root@zhangchao ~]# cat recode.txt Jimmy the Weasel 100 Pleasant Drive San Francisco,CA 123456 Big Tony 200 Incognito Ave. Suburbia,WA 64890 :wq [root@zhangchao ~]# cat awk.txt #!/bin/awk BEGIN { FS=" " 以换行符分隔字段 RS="" 以空行分隔的内容作为输入 ORS="### " 每行以### 结尾 } { print $1,$2,$3 } [root@zhangchao ~]# awk -f awk.txt recode.txt Jimmy the Weasel 100 Pleasant Drive San Francisco,CA 123456### Big Tony 200 Incognito Ave. Suburbia,WA 64890### :wq ###