1.安装与启动
安装略(二进制文件解压即可使用)
linux中启动: ./zkServer.sh start
停止 : ./zkServer.sh stop
重启: ./zkServer.sh restart
查看状态: ./zkServer.sh status
linux与windows下客户端的启动
zkCli.cmd –server ip:port连接到指定的服务器地址 //windows
zkCli.sh –server ip:port连接到指定的服务器地址 //centos
客户端的退出: quit
2. 配置文件说明
# Zookeeper独立的工作时间单元 tickTime=2000 # 这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)
初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过10个心跳的时间(也就是 tickTime)长度后 Zookeeper服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。
总的时间长度就是 10*2000=20 秒 initLimit=10 # 这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 5*2000=10 秒 ,一般Љ用修改,如果网络࣪境Љ稳定,Օ以适寳调高 syncLimit=5 # 存储数据的地址 dataDir=/usr/local/zookeeper/zookeeper-3.4.10/data
# 存储日志的地址 dataLogDir=/usr/local/zookeeper/zookeeper-3.4.10/logs # 端口 clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
#其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器。
挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,
所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号,C一般为2888,D一般为3888
#server.A=B:C:D
3. 客户端基本命令
help 查看所有命令以及注释
ls path [watch] 类似linux的ls ,产看路径下的所有节点,或者指定目录下的节点的子节点
create [-s] [-e] path data acl 创建一个节点 ,-s或者-e表示创建的是顺序或临时节点,不加默认创建的是持久节点 ,Path为节点的全路径, Data为当前节点内孓储的数据 ,Acl 用来进行权限控制,缺省情况不做任何权限控制,临时节点不能创建子节点,一般数据大小不要超过12k,保存在缓存中。
![]()
get path [watch] 获取指定节点的路径的值
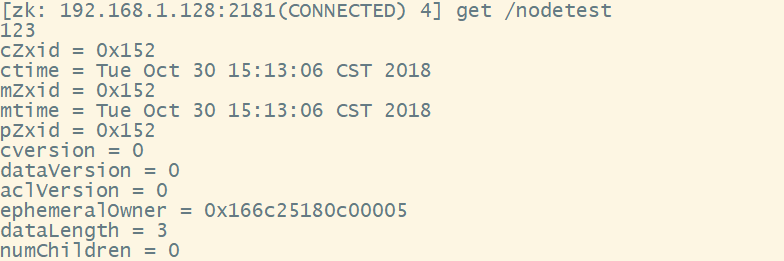
123表示值
cZxid:节点创建时的zxid
ctime:节点创建时间
mZxid:节点最近一次更新时的zxid
mtime:节点最近一次更新的时间
cversion:子节点数据更新次数
dataVersion:本节点数据更新次数
aclVersion:节点ACL(授权信息)的更新次数
ephemeralOwner:如果该节点为临时节点,ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是临时节点,ephemeralOwner值为0
dataLength:节点数据长度,本例中为hello world的长度
numChildren:子节点个数
set path data [version] 更新指定节点的数据内容 ,Path表示被更新的节点路径 , data为更新的数据 ,Version为指定被更新的数据版本,一般不指定,如果 数据版本已经更新,则指定旧版本时会报错
delete path [version] 删除节点
4.数据节点
Zk树形结构中的数据节点,用于存储数据
持久节点:一旦创建,除非主动调用删除操作,否则一直存储在zk中
临时节点:与客户端的会话绑定,一旦客户端会话失效,这个客户端创建的所有临时节点都会被移除
顺序节点:创建子节点时,如果设置属性SEQUENTIAL,则会自动在节点后面追加一个整型数子,上限是整形的最大值
5. Watcher
定义:
Zk中引入了watcher机制来实现了发布/订阅功能,能够让多个订阅者同时监听某一个主题对象,当某个主题对象自身状态变化时,会通知所有订阅者

Watcher组成 :客户端 ,客户端watchManager ,Zk服务器
Watcher机制 :客户端向zk服务器注册watcher 的同时,会将watcher对象存储在 客户端的watchManager ,Zk服务器触发watcher事件后,会向客户端发送通知,客户端线程从 watchManager中݊起watcher执行
Watcher接口
实现 Watcher 接口,重写 process方法
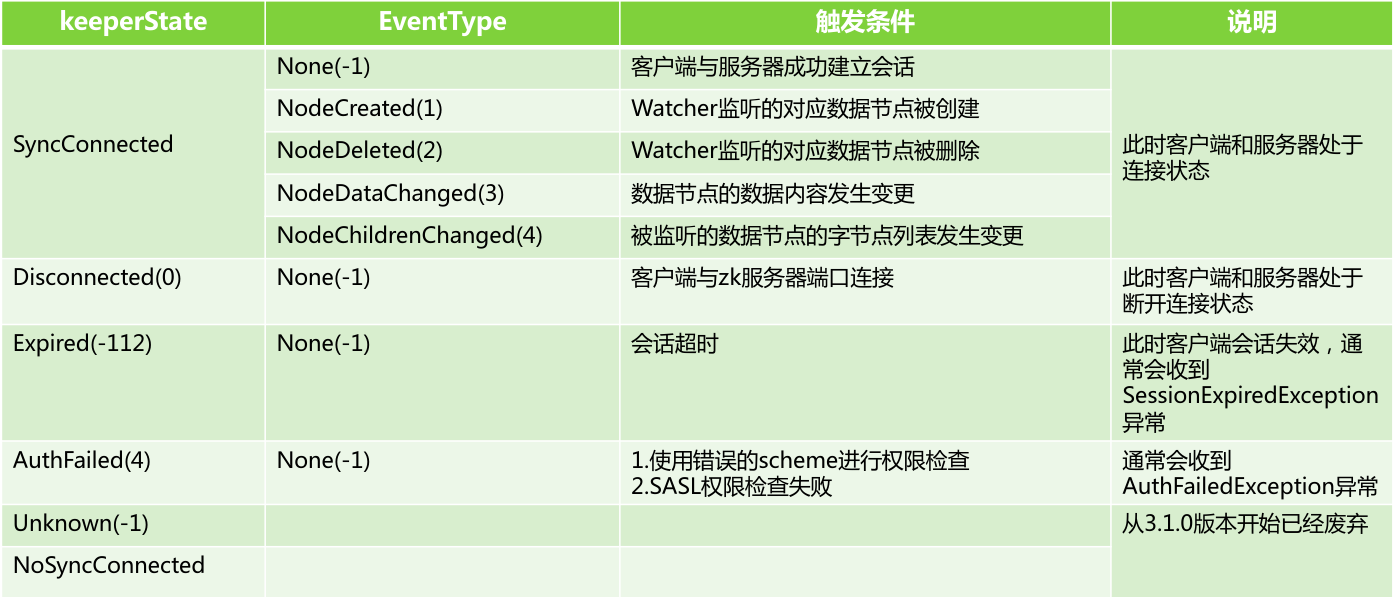
Watcher事件
通知状态:org.apache.zookeeper.Watcher.Event.KeeperState
事件类型: org.apache.zookeeper.Watcher.Event.EventType
ZookeeperWatcher watcher = new ZookeeperWatcher();
ZooKeeper zooKeeper = new ZooKeeper("192.168.1.128:2181", 10000, new Watcher() {
public void process(WatchedEvent watchedEvent) {
Event.EventType type = watchedEvent.getType();
Event.KeeperState state = watchedEvent.getState();
}
});
测试
@Test
public void test1() throws IOException, KeeperException, InterruptedException {
ZooKeeper zooKeeper = new ZooKeeper("192.168.1.128:2181", 10000, new Watcher() {
public void process(WatchedEvent watchedEvent) {
System.out.println(watchedEvent.getType());
}
});
List<String> children = zooKeeper.getChildren("/node1", true);
Thread.sleep(100000);
}
6.zookeeper的api,原生api基本不用,基本都是使用Curator

Watcher注册流程

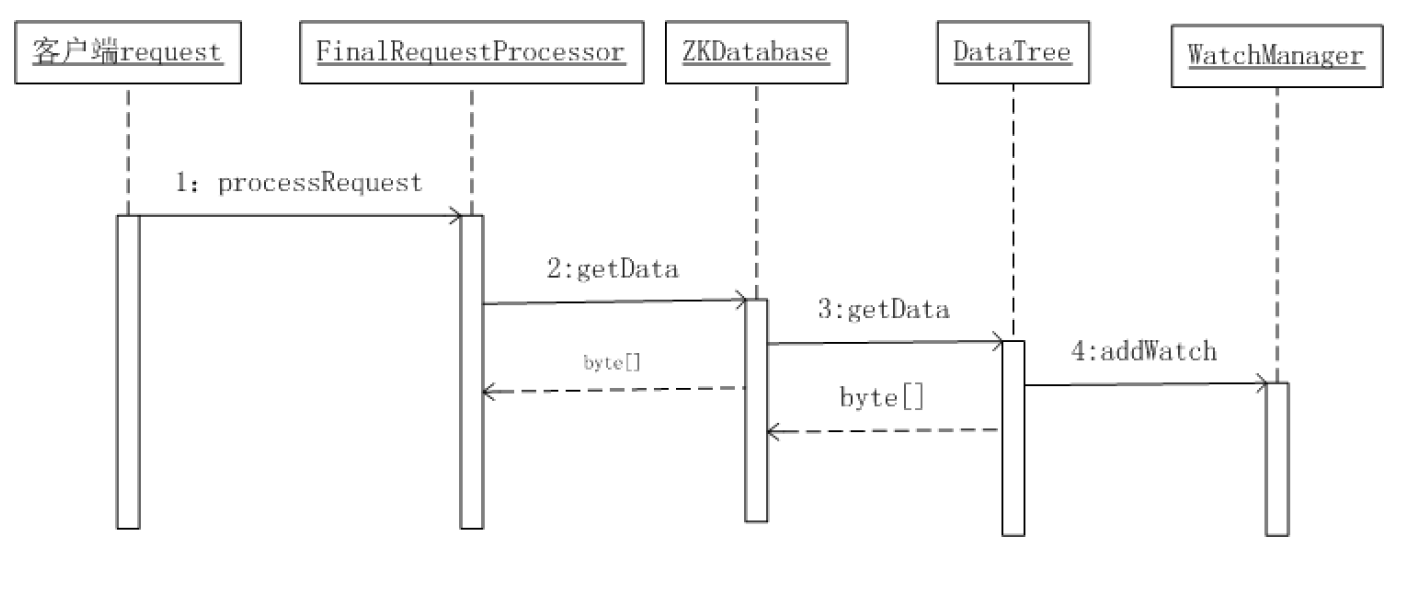
备注;
Watcher设置后,一旦触发一次即会失效,如果需要一直监控听,就需要再次注册
ZooKeeper(String connectString, int sessionTimeout, Watcher watcher) ,connectString可以写多个,找不到找下一个,原生api基本不用
7. Acl
Acl组成
Scheme:id:permission 比如:world:anyone:crdwa
Scheme:证过程中使用的检验策略
Id:权限被赋予的对象,比如ip或者某个用户
Permission:权限
命令
setAcl:设置节点的权限 ,节点的acl不具有继承关系
getAcl:查看节点的Acl信息
scheme
world: 它下面只有一个id为anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就属于world:anyone的
例如: setAcl /node1 world:anyone:crdwa( 表示任何用户都具有crdwa权限 ,/node1表示节点)
auth: 它不需要id, 只要是通过authentication的user都有权限(zookeeper支持通过kerberos来进行authencation, 也支持username/password形式的authentication)
例如: setAcl /node1 auth:username:password:crdwa (表示给认证通过的所有用户设置acl权限 ,同时可以添加多个用户,通过addauth命ј进行认证用户的添加addauth digest <username>:<password> ,Auth策略的本质就是digest , 如果通过addauth创建多组用户和密码,当使用setAcl修改权限时,所有的用户和密码的权限都会跟着修改,通过addauth新创建的用户和密码组需要重新调用setAcl才会加入到权限组中去 )
digest: 它对应的id为username:BASE64(SHA1(password)),它需要先通过username:password形式的authentication
例如:digest:username:password:crdwa ( 指定某个用户及它的密码可以访问,此处的username:password是经过SHA-1和BASE64编码,通过addauth命ј进行认证用户的添加,addauth digest <username>:<password> )
ip: 它对应的id为客户机的IP地址,设置的时候可以设置一个ip段,比如ip:192.168.1.0/16, 表示匹配前16个bit的IP段
例如 ip:127.0.0.1:crdwa (指定某个ip地址可以访问)
super: 在这种scheme情况下,对应的id拥有超级权限,可以做任何事情(cdrwa)
permission
zookeeper目前支持下面一些权限:
create(c): 创建权限,可以在在当前node下创建child node
delete(d): 删除权限,可以删除当前的node
read(r): 读权限,可以获取当前node的数据,可以list当前node所有的child nodes
write(w): 写权限,可以向当前node写数据
admin(a): 管理权限,可以设置当前node的permission
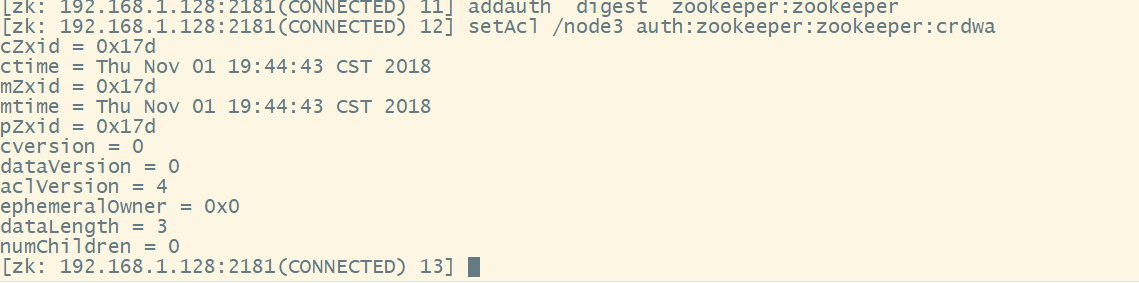
需要添加addauth digest zookeeper:zookeeper后才能使用setAcl
添加权限以后,使用另外一个客户端访问,在没有添加用户时,不允许访问,如下

添加以后才能正常的访问

8.zk集群
集群的定义:多台计算机构组成, 计算机之间通过网络进行通信,彼此进行交互,共同目标。
分布式系统的定义:同一个模块由多台服务器执行。
Zookeeper集群
Zookeeper所有节点机器数据都一致,集群节点之间依靠心跳来感觉彼此之间的存在,所有写操作都在主节点,其它节点只能读(类似redis),其它虽然可以接收写请求,但是内部会把写操作转给主节点 ,leader的产生是通过选举机制选出主节点(类似redies),一般至少3个节点,最好是基数个节点机器(这是因为Zookeeper采用的Zab算法的问题,奇数便于选举),当采用最终一致性的策略时,当一半以上的节点数据写入成功后,则返回写入成功
9.分布式系统的CAP
一致性c:分布式࣪境下,一致性主要是指数据在多个副本间是否保持一致
可用性a:是指系统提供的服务必须一直处于高可用的状态,对于用户的请求总是能够在有限的时间内返回结果ͺ有限时间强调的是用户能接收的时间 ,可用性与常说的高可用性的可用性不是一个概念,如果服务访问不到,不属于没有可用性
分区容忍性p:集群出࣫网络割裂ͧ即脑裂时,集群还能继续提供一定的可用性和一致性,除非整个网络不可用
一个分布式系统不能同时满足一致性,高可用,分区容忍性,只能满足其中的两项,只能满足其中的两项并不是另外一项就完全没有,而是要求没有那么严格(最终会保持一致),分区容忍性是分布式系统必需有的特性,因为网络不可靠,所以只能在C和A中进行权衡

10. BASE
BASE是Basically Available基本可用与Soft state软状态以及Eventually Consistent最终一致性的简写,也是对一致性,高可用权衡的结果 ,BASE的核心思想是即使无法做到强一致性,但是每个应用可以根据自身的业务特点,采用适当的方式达到最终一致性,来满足系统的高可用
BASE的基本可用:响应时间上的损失:有些要求1s内返回,有些要求5s内返回,功能上的损失:对于电商来说,某些区域可能不能购买某些商品,又或者大促时,部分消费者被引流到降级的页面
BASE的弱状态:也称为软状态,是指允许系统中的数据存在中间状态,并认为该状态不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间存在一定的延时
BASE的最终一致性:系统中的数据副本在经过一段时间同步后,最终能够达到一个一致的状态
11. 客户端
ZkClient的基本使用
https://www.2cto.com/kf/201707/661220.html
Curator的基本使用
CuratorFrameworkFactory工厂的两个静态方法, Start()方法启动
static CuratorFramework newClient(String connectString, int sessionTimeoutMs, int connectionTimeoutMs, RetryPolicy retryPolicy)
static CuratorFramework newClient(String connectString, RetryPolicy retryPolicy)
备注:
connectString:逗号分开的ip:port对
retryPolicy:重试策略,默认四种:Exponential BackoffRetry ,RetryNTimes ,RetryOneTime,RetryUntilElapsed
sessionTimeoutMs:会话超时时间,单位为毫秒,默认60000ms
connectionTimeoutMs:连接创建超时时间,单位为毫秒,默认是15000ms
默认重试策略
ExponentialBackoffRetry
ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries, int maxSleepMs)
当前应该sleep的时间, baseSleepTimeMs * Math.max(1, random.nextInt(1 << (retryCount + 1)))
baseSleepTimeMs 初始sleep时间
maxRetries 最大重试次数
maxSleepMs 最大重试时间
返回值 如果还会继续重试,则返回true
RetryNTimes
RetryNTimes(int n, int sleepMsBetweenRetries)
n 最大重试次数
sleepMsBetweenRetries 每次重试的间隔时间
RetryOneTime
只重试一次
RetryOneTime(int sleepMsBetweenRetry), sleepMsBetweenRetry为重试间隔的时间
RetryUntilElapsed
RetryUntilElapsed(int maxElapsedTimeMs, int sleepMsBetweenRetries)
重试的时间超过最大时间后就不再重试
maxElapsedTimeMs 最大重试时间
sleepMsBetweenRetries 每次重试的间隔时间
实现接口RetryPolicy可以自定义重试策略
重写allowRetry方法
boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper)
retryCount 已经重试的次数,如果第一次重试,值为0
elapsedTimeMs 重试花费的时间,单位为毫秒
sleeper 类似于Thread.sleep,用于sleep指定时间
返回值 如果还会继续重试,则返回true
api
CreateBuilder
获取 create()---- CuratorFramework
creatingParentsIfNeeded() //递归创建父目录
withMode( CreateMode mode)//设置节点属性,例如:CreateMode.PERSISTENT,如果是递归创建,创建模式为临时节点,则只有叶子节点是临时节点,非叶子节点都为持久节点
withACL(List aclList) //设置acl
forPath(String path,String data) //指定路径
CreateMode
PERSISTENT:持久化
PERSISTENT_SEQUENTIAL:持久化并且带序列号
EPHEMERAL:临时
EPHEMERAL_SEQUENTIAL:临时并且带序列号
DeleteBuilder
获取 delete() -----CuratorFramework
withVersion(int version) //特定版本号
guaranteed() //确保节点被删除 (删除失败后,重试删除)
forPath(String path) //指定路径
deletingChildrenIfNeeded() //递归删除所有子节点
GetDataBuilder
获取 getData() -----CuratorFramework
storingStatIn(org.apache.zookeeper.data.Stat stat) //把服务器端获取的状态数据存储到stat对象
Byte[] forPath (String pathh)//节点路径
Stat stat = new Stat();
client.getData().storingStatIn(stat).forPath("path");
SetDataBuilder
获取 setData() -----CuratorFramework
withVersion(int version) //指定版本号
forPathh(String path,byte[] datas)//节点路路径
forPath(String path)//节点路径
GetChildrenBuilder
获取 getChildren() -----CuratorFramework
storingStatIn(org.apache.zookeeper.data.Stat stat) //把服务器端获取的状态数据存储到stat对象
Byte[] forPath(String path)//节点路径
usingWatcher(org.apache.zookeeper.Watcher watcher) //设置watcher,类似于zk本身的api,也只能使用一次
usingWatcher(CuratorWatcher watcher) //设置watcher ,类似于zk本身的api,也只能使用一次
watcher
NodeCache:监听数据节点的内容变更 ,监听节点的创建,即如果指定的节点不存在,则节点创建后,会触发这个监听,如果该节点被删除,就无法再触发监听事件。
NodeCache(CuratorFramework client, String path, boolean dataIsCompressed)
client 客户端实例
path 数据节点路径
dataIsCompressed 是否进行数据压缩
public static void main(String[] args) throws Exception {
CuratorFramework client = getClient();
String path = "/p1";
final NodeCache nodeCache = new NodeCache(client, path);
nodeCache.start();
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("监听事件触发");
System.out.println("重新获得节点内容为:" + new String(nodeCache.getCurrentData().getData()));
}
});
client.setData().forPath(path, "456".getBytes());
Thread.sleep(15000);
}
备注:NodeCache的start方法有一个带Boolean参数的方法,如果设置为true则在首次启动时就会缓存节点内容到Cache中
PathChildrenCache
监听指定节点的子节点变化情况 ,包括新增子节点 ,子节点数据变更和子节点删除,不会对二级子节点进行监听,只会对子节点进行监听。
client 客户端实例
path 数据节点路径
dataIsCompressed 是否进行数据压缩
cacheData 用于配置是否把节点内容缓存起来,如果配置为true,那么客户端在接收到节点列表变更的同时,也能够获取到节点的数据内容ͺ如果为false则无法取到数据内容
threadFactory,executorService 通过这两个参数构造专门的线程池来处理事件通知
public class CuratorPathChildrenCacheTest {
public static void main(String[] args) throws Exception {
CuratorFramework client = getClient();
String parentPath = "/p1";
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, parentPath, true);
pathChildrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("事件类型:" + event.getType() + ";操作节点:" + event.getData().getPath());
}
});
String path = "/p1/c1";
client.create().withMode(CreateMode.PERSISTENT).forPath(path);
Thread.sleep(1000); // 此处需留意,如果没有现成睡眠则无法触发监听事件
client.delete().forPath(path);
Thread.sleep(15000);
}
private static CuratorFramework getClient() {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192.168.1.128:2181")
.retryPolicy(retryPolicy).sessionTimeoutMs(6000).connectionTimeoutMs(3000).namespace("demo").build();
client.start();
return client;
}
}
pathChildrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
BUILD_INITIAL_CACHE //同步初始化客户端的cache,及创建cache后,就从服务器端拉入对应的数据
POST_INITIALIZED_EVENT //异步初始化,初始化完成触发事件PathChildrenCacheEvent.Type.INITIALIZED
NORMAL //异步初始化cache
事务
CuratorFramework的实例包含inTransaction( )接口方法,调用此方法开启一个ZooKeeper事务. 可以复合create, setData, check, and/or delete 等操作然后调用commit()作为一个原子操作提交
client.inTransaction().check().forPath("path")
.and() .create().withMode(CreateMode.EPHEMERAL).forPath("path","data".getBytes())
.and() .setData().withVersion(1).forPath("path","data".getBytes())
.and()
.commit();
异步接口
实现BackgroundCallback接口,BackgroundCallback接口中一个重要的回调值为CuratorEvent


client.create().creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.inBackground((curatorFramework, curatorEvent) -> {
System.out.println(111);
}, executor)
.forPath("path");
备注: 如果#inBackground()方法不指定executor,那么会默认使用Curator的EventThread去进行异步处理。
CuratorListener监听,使用该监听器之后,调用inBackground方法异步时触发监听,而对于节点的创建或修改则不会触发监听事件。
Executor executor = Executors.newFixedThreadPool(2);
CuratorListener listener = new CuratorListener() {
@Override
public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("监听事件触发,event内容为:" + event);
}
};
client.getCuratorListenable().addListener(listener);
12 ZooKeeper选举(这些方面类似redis)
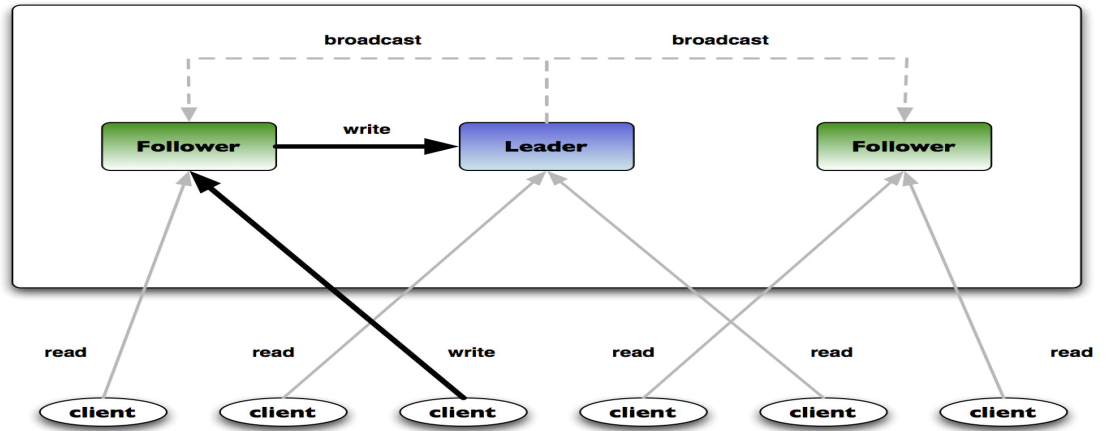
ZooKeeper Atomic Broadcast 即ZooKeeper原子消息广播协议,简称为ZAB,选举过程需要依赖该协议,数据写入过程也需该协议, 所有事务请求必需由一个全局唯一的服务器来协调处理,这样的服务
器被称为Leader服务器,而余Ј的其它服务器则成为Follower服务器。Leader服务器负责将一个客户端事务请求转换成那个一个事务Proposal(提议),并将该Proposal分发给集群中所有的Follower服务
器。之后Leader服务器需要等待所有Follower服务器的反馈,一旦超过半数的Follower服务器进行了正确的反馈后,那么Leader就会再次向所有的Follower服务器分发Commit消息,要求其将前一个
Proposal进行提交
13. ZAB协议三阶段
发现,即选举Leader过程;同步,选举出新的Leader后,Follwer或者Observer从Leader同步最新的数据;广播,同步完成后,就可以接收客户端新的事务请求,并进行消息广播,实现数据在集群节点的副本存储。
Leader 事务请求的唯一调度和处理者,保证集群事务处理的顺序性 ,集群内部各服务器的调度者
Follower 处理客户端非事务请求,转发事务请求给Leader服务器 ,参与事务请求Proposal的投票 ,参与Leader选举投票
Observer 处理客户端非事务请求,转发事务请求给Leader服务器 , 不参加任何形式的投票,包括选举和事务投票, 该角色存在通常是为了提高读性能
14. Zookeeper节点状态
looking:寻找Leader状态,处于该状态需要进入选举流程
leading:领导者状态,处于该状态的节点说明是角色已经是Leader
following:跟随者状态,表示Leader已经选举出来,当前节点角色是follower
observer:观察者状态,表明当前节点角色是observer
15.数据的一致性:同步算法