1. redis
1. 概念
2. 下载安装
3. 命令操作
1). 数据结构
4. 持久化操作
5. 使用Java客户端操作redis
# Redis
1. 概念:
redis是一款高性能的NOSQL系列的非关系型数据库
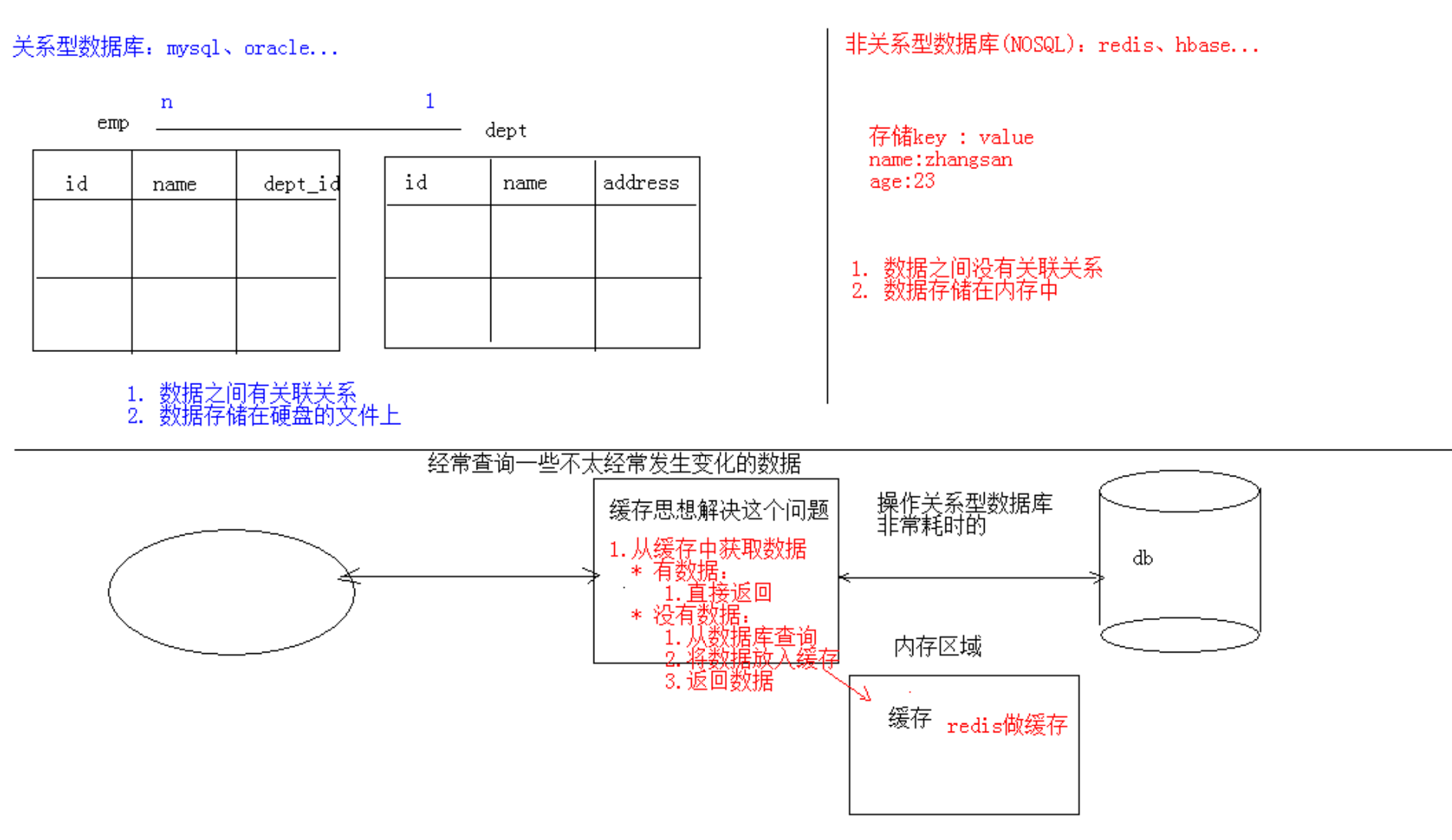
关系型数据库数据存在硬盘中(需要io操作),非关系型数据库存在内存中(速度快一些),没有表的概念,用于缓存一些不经常变化的数据。
1.1.什么是NOSQL
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
随着互联网web2.0网站的兴起(以用户创作为中心),传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
1.1.1. NOSQL和关系型数据库比较
优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难,而nosql没有表与表之间关系的限制。
缺点:
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
3)不提供关系型数据库对事务的处理。(但是redis支持事务)
1.1.2. 非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
1.1.3. 关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
1.1.4. 总结
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,让NoSQL数据库对关系型数据库的不足进行弥补。
一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据。
1.2.主流的NOSQL产品
• 键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化


• 列存储数据库
相关产品:Cassandra, HBase, Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
• 文档型数据库
相关产品:CouchDB、MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法
• 图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络
数据模型:图结构
优势:利用图结构相关算法。
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
1.3 什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
1) 字符串类型 string
2) 哈希类型 hash
3) 列表类型 list
4) 集合类型 set
5) 有序集合类型 sortedset
1.3.1 redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等解决高并发的问题)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒
• 分布式集群架构中的session分离
2. 下载安装
1. 官网:https://redis.io
2. 中文网:http://www.redis.net.cn/
3. 解压直接可以使用:(将来使用是部署在linux上的,学习时使用window版本了,存在课程资料里)

* redis.windows.conf:配置文件
* redis-cli.exe:redis的客户端
* redis-server.exe:redis服务器端(双击即可打开)
双击打开服务器端,端口和进程号:
再双击打开客户端:连接的是本机redis的端口,然后在此敲命令进行键值对的存储。

set username zhangsan存入,get username就可以拿出了。

安装很容易,接下来是如何使用它,有两种方式使用redis,一是通过命令,而是通过java代码来使用。
3. 命令操作(数据的存储和获取)
1. redis的数据结构(面试重点):
* redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
* value的数据结构:
1) 字符串类型 string
2) 哈希类型 hash : map格式
3) 列表类型 list : linkedlist格式。支持重复元素
4) 集合类型 set : 不允许重复元素
5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序

2. 字符串类型 string
1. 存储: set key value
127.0.0.1:6379> set username zhangsan
OK
2. 获取: get key
127.0.0.1:6379> get username
"zhangsan"
没获取到会返回nil
3. 删除: del key
127.0.0.1:6379> del age
(integer) 1
更多命令可以参考redis中文网的教程
3. 哈希类型 hash
1. 存储: hset key field value
127.0.0.1:6379> hset myhash username lisi(看上图,myhash是key,filed和value是key对应的value为hashmap)
(integer) 1
127.0.0.1:6379> hset myhash password 123
(integer) 1
2. 获取:
* hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username (其实是两个key)
"lisi"
* hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash (外面那个大的key)
1) "username"
2) "lisi"
3) "password"
4) "123"
3. 删除: hdel key field (也是两个key
127.0.0.1:6379> hdel myhash username
(integer) 1
4. 列表类型 list:允许值元素重复
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
双栈共底或者是双向队列?,底层是压缩列表和双向链表
1. 添加:
1. lpush key value: 将元素加入列表左边
2. rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a
(integer) 1
127.0.0.1:6379> lpush myList b
(integer) 2
127.0.0.1:6379> rpush myList c
(integer) 3
2. 获取:
* lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1(0到-1是获取该key中所有list中值的意思)
1) "b"
2) "a"
3) "c"
3. 删除:
* lpop key: 删除列表最左边的元素,并将元素返回
* rpop key: 删除列表最右边的元素,并将元素返回
5. 集合类型 set : 不允许重复元素
1. 存储:sadd key value
127.0.0.1:6379> sadd myset a
(integer) 1
127.0.0.1:6379> sadd myset a
(integer) 0
2. 获取:smembers key:获取set集合中所有元素(是该key的所有元素,别的key的set还是不行。。且顺序不保证
127.0.0.1:6379> smembers myset
1) "a"
3. 删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a
(integer) 1
6. 有序集合类型 sortedset:
不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。
redis正是通过分数来为集合中的成员进行从小到大的排序。
1. 存储:zadd key score value (按照这个score的分数来进行排序,可以用来存排行榜,分数小的在前)
127.0.0.1:6379> zadd mysort 60 zhangsan
(integer) 1
127.0.0.1:6379> zadd mysort 50 lisi
(integer) 1
127.0.0.1:6379> zadd mysort 80 wangwu
(integer) 1
2. 获取:zrange key start end [withscores]
127.0.0.1:6379> zrange mysort 0 -1
1) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "zhangsan"
2) "60"
3) "wangwu"
4) "80"
5) "lisi"
6) "500"
3. 删除:zrem key value
127.0.0.1:6379> zrem mysort lisi
(integer) 1
7. 通用命令
1. keys * : 查询所有的键(外层的key)
2. type key : 获取键对应的value的类型
3. del key:删除指定的key value
4. 持久化
1. redis是一个内存数据库,当redis服务器重启,或电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
2. redis持久化机制:
1. RDB:默认方式,不需要进行配置,默认就使用这种机制
* 在一定的间隔时间中,检测key的变化情况,然后持久化数据
1. 编辑redis.windwos.conf文件(解压后的配置文件)
# after 900 sec (15 min) if at least 1 key changed 900秒内如果有1个key发生改变,就持久化一次
save 900 1
# after 300 sec (5 min) if at least 10 keys changed
save 300 10
# after 60 sec if at least 10000 keys changed
save 60 10000
这里可以根据服务器的性能和需要改成自己想要的
2. 重新启动redis服务器,并指定配置文件名称
若改动了配置文件,就不能直接打开服务器和客户端使用redis。
我们需要在cmd中输入:redis-server.exe redis.windows.conf来手动启动服务器,然后再打开客户端,输入命令。持久化后,目录下会生成一个后缀为rdb的文件,用来存储持久化的数据。
D:JavaWeb2018day23_redis资料
ediswindows-64
edis-2.8.9>redis-server.exe redis.windows.conf
2. AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据(类似mysql也是写一条存一条,对性能影响较大)
1. 编辑redis.windwos.conf文件
appendonly no(找不到用搜索,关闭aof) --> 改成 appendonly yes (开启aof)
# appendfsync always : 每一次操作都进行持久化
appendfsync everysec : 每隔一秒进行一次持久化
# appendfsync no : 不进行持久化
持久化机制的原理:https://segmentfault.com/a/1190000015983518#item-2
RDB的原理
在Redis中RDB持久化的触发分为两种:自己手动触发与Redis定时触发。
针对RDB方式的持久化,手动触发可以使用:
- save:会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。
- bgsave:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。
而自动触发的场景主要是有以下几点:
- 根据我们的
save m n配置规则自动触发; - 从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发
bgsave; - 执行
debug reload时; - 执行
shutdown时,如果没有开启aof,也会触发。
由于 save 基本不会被使用到,我们重点看看 bgsave 这个命令是如何完成RDB的持久化的。(该图就是原理?就是bgsave这个命令?我有点没看懂)
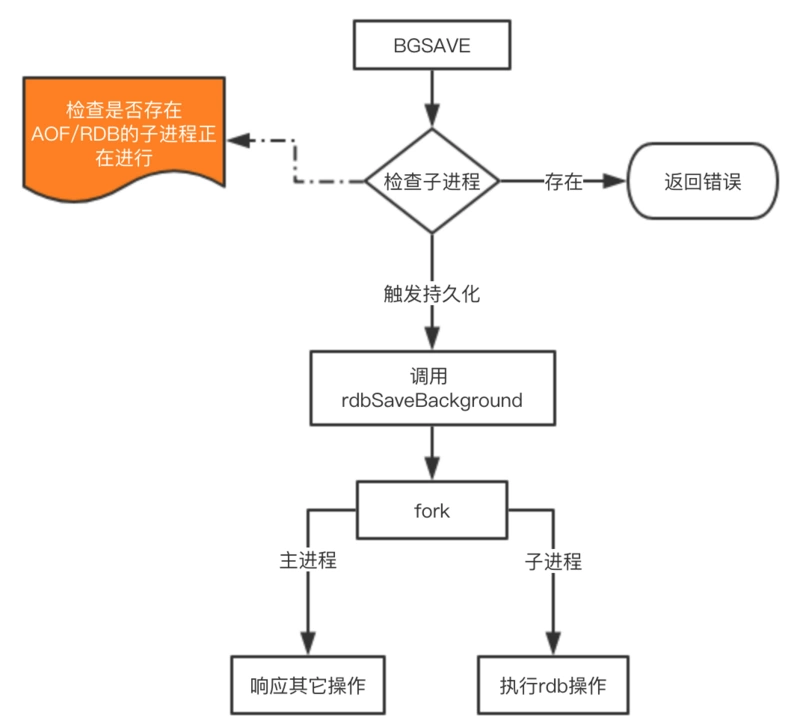
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储。
开启RDB方式redis会在指定的时间段内将内存中的数据快照到磁盘中,redis启动时再恢复到内存中。
Redis会单独创建(fork)一个线程,将数据写入到临时文件中,持久化的过程都结束了,在用这个临时文件替换上次的临时文件。
如果需要进行大规模的数据恢复,并且对于数据恢复不是很敏感,RDB的方式比AOF方式更加高效,RDB的缺点就在于最后一次持久化后的数据有可能会丢失。
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
AOF的原理
AOF的整个流程大体来看可以分为两步,一步是命令的实时写入(如果是 appendfsync everysec 配置,会有1s损耗),第二步是对aof文件的重写。
对于增量追加到文件这一步主要的流程是:命令写入--->追加到aof_buf --->同步到aof磁盘。那么这里为什么要先写入buf在同步到磁盘呢?如果实时写入磁盘会带来非常高的磁盘IO操作,影响整体性能。
aof重写是为了减少aof文件的大小,可以手动或者自动触发,关于自动触发的规则请看上面配置部分。fork的操作也是发生在重写这一步,也是这里会对主进程产生阻塞。
手动触发: bgrewriteaof,自动触发 就是根据配置规则来触发,当然自动触发的整体时间还跟Redis的定时任务频率有关系。
下面来看看重写的一个流程图:

对于上图有四个关键点补充一下:
- 在重写期间,由于主进程依然在响应命令,为了保证最终备份的完整性;因此它依然会写入旧的AOF file中,如果重写失败,能够保证数据不丢失。
- 为了把重写期间响应的写入信息也写入到新的文件中,因此也会为子进程保留一个buf,防止新写的file丢失数据。
- 重写是直接把当前内存的数据生成对应命令,并不需要读取老的AOF文件进行分析、命令合并。
- AOF文件直接采用的文本协议,主要是兼容性好、追加方便、可读性高可认为修改修复。
不能是RDB还是AOF都是先写入一个临时文件,然后通过 rename 完成文件的替换工作。
5. Java客户端 Jedis
* Jedis: 一款java操作redis数据库的工具(类似之前的JDBC,导入连接mysql的jar包后就可以用java操作数据库)
* 使用步骤:
1. 下载jedis的jar包(之后应该也是maven的pom那里下载)
2. 使用
//1. 获取连接
Jedis jedis = new Jedis("localhost",6379);
//2. 操作
jedis.set("username","zhangsan");//这样就将string类型的值写入了redis
//3. 关闭连接
jedis.close();
运行后,使用key *命令,可以看到username已经被创建。Jedis中的方法名称与命令相同,因此理解上较为简单。
* Jedis操作各种redis中的数据结构
1) 字符串类型 string
set
get
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
//存储
jedis.set("username","zhangsan");
//获取
String username = jedis.get("username");
System.out.println(username);
//可以使用setex()方法存储可以指定过期时间的 key value(可以使用该方法存一些有时限的激活码或验证码)
jedis.setex("activecode",20,"hehe");//将key为activecode:值为hehe键值对存入redis,并且20秒后自动删除该键值对
//3. 关闭连接
jedis.close();
2) 哈希类型 hash : map格式
hset
hget
hgetAll
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// 存储hash
jedis.hset("user","name","lisi");//外层大key 内层key-value
jedis.hset("user","age","23");
jedis.hset("user","gender","female");
// 获取hash
String name = jedis.hget("user", "name");//外层大key 内层小key 获取对应的value
System.out.println(name);
// 获取hash的user这个大key的所有map数据
Map<String, String> user = jedis.hgetAll("user");
// keyset遍历map集合
Set<String> keySet = user.keySet();
for (String key : keySet) {
//获取value
String value = user.get(key);
System.out.println(key + ":" + value);
}
//3. 关闭连接
jedis.close();
3) 列表类型 list : linkedlist格式。支持重复元素
lpush / rpush
lpop / rpop
lrange start end : 范围获取
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// list 存储
jedis.lpush("mylist","a","b","c");//从左边存 存多个
jedis.rpush("mylist","a","b","c");//从右边存
// list 范围获取
List<String> mylist = jedis.lrange("mylist", 0, -1);//取出mylist这个key中所有值
System.out.println(mylist); //cbaabc
// list 弹出
String element1 = jedis.lpop("mylist");//c
System.out.println(element1);
String element2 = jedis.rpop("mylist");//c
System.out.println(element2);
// list 弹出后重新来范围获取
List<String> mylist2 = jedis.lrange("mylist", 0, -1);
System.out.println(mylist2);//baab
//3. 关闭连接
jedis.close();
4) 集合类型 set : 不允许重复元素
sadd
smembers:获取所有元素
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// set 存储
jedis.sadd("myset","java","php","c++");//存多个 不允许重复
// set 获取
Set<String> myset = jedis.smembers("myset");
System.out.println(myset);//打印出来没有顺序 [c++,java,php]
//3. 关闭连接
jedis.close();
5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序
zadd
zrange
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// sortedset 存储
jedis.zadd("mysortedset",3,"亚瑟"); //给一个double类型的分数
jedis.zadd("mysortedset",30,"后羿");
jedis.zadd("mysortedset",55,"孙悟空");
// sortedset 获取
Set<String> mysortedset = jedis.zrange("mysortedset", 0, -1); //返回全部set 有顺序按分数从小到大
System.out.println(mysortedset); //[亚瑟,后羿,孙悟空]
//3. 关闭连接
jedis.close();
* jedis连接池: JedisPool
* 使用:
1. 创建JedisPool连接池对象
2. 调用方法 getResource()方法获取Jedis连接
@Test public void test7(){ //0.创建一个配置对象 JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();//这个config对象很多set方法 jedisPoolConfig.setMaxTotal(50);//最多连接数 jedisPoolConfig.setMaxIdle(10);//最大空闲连接 //1.创建Jedis连接池对象 JedisPool jedisPool = new JedisPool(jedisPoolConfig,"localhost",6379);//空参则使用默认 //2.获取连接 Jedis jedis = jedisPool.getResource(); //3.使用 jedis.set("hehe","hahaha"); //4.关闭 归还到连接池中 jedis.close(); }
关于jedis的详细配置
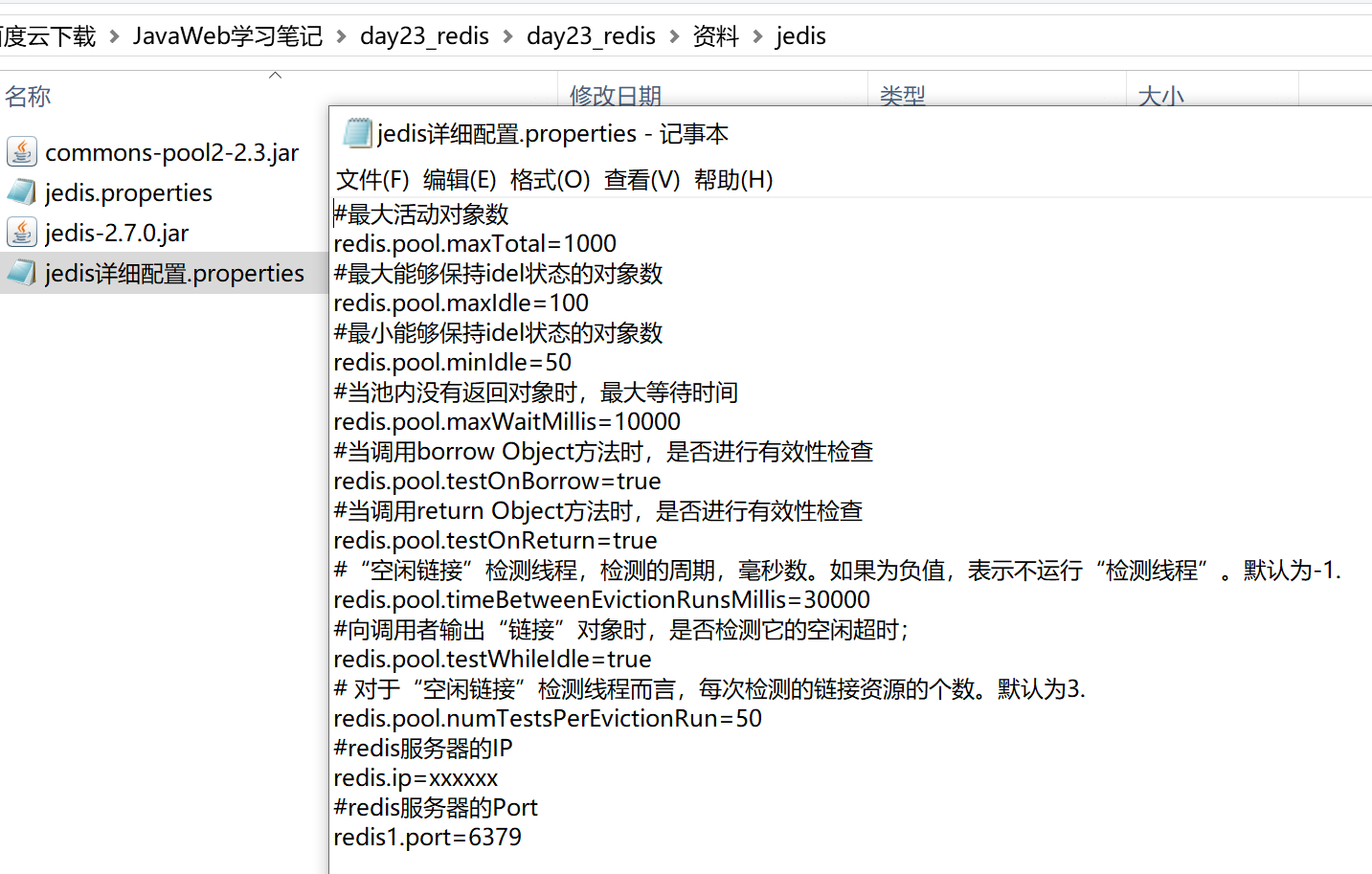
我们可以把配置信息写到文件里,就像jdbc配置信息那样,写一个.pro文件然后写一个工具类加载这个文件。
配置文件内容jedis.properties

* 连接池工具类
/** * JedisPool工具类 * 加载配置文件,配置连接池参数 * 提供获取连接的方法 */ public class JedisPoolUtils { private static JedisPool jedisPool; //定义一个静态代码块在该类加载时就读取文件 static{ //读取配置文件 InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties"); //创建Properties对象 Properties pro = new Properties(); //关联文件 try { pro.load(is);// } catch (IOException e) { e.printStackTrace(); } //获取数据,设置到JedisPoolConfig中 JedisPoolConfig config = new JedisPoolConfig(); //String转int用Integer.parseInt 这里面的参数是pro文件的key,从而获取key对应的value config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal"))); config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle"))); //初始化JedisPool jedisPool = new JedisPool(config,pro.getProperty("host"),Integer.parseInt(pro.getProperty("port"))); } /** * 获取连接方法 */ public static Jedis getJedis(){ return jedisPool.getResource(); } }
测试使用该工具类:
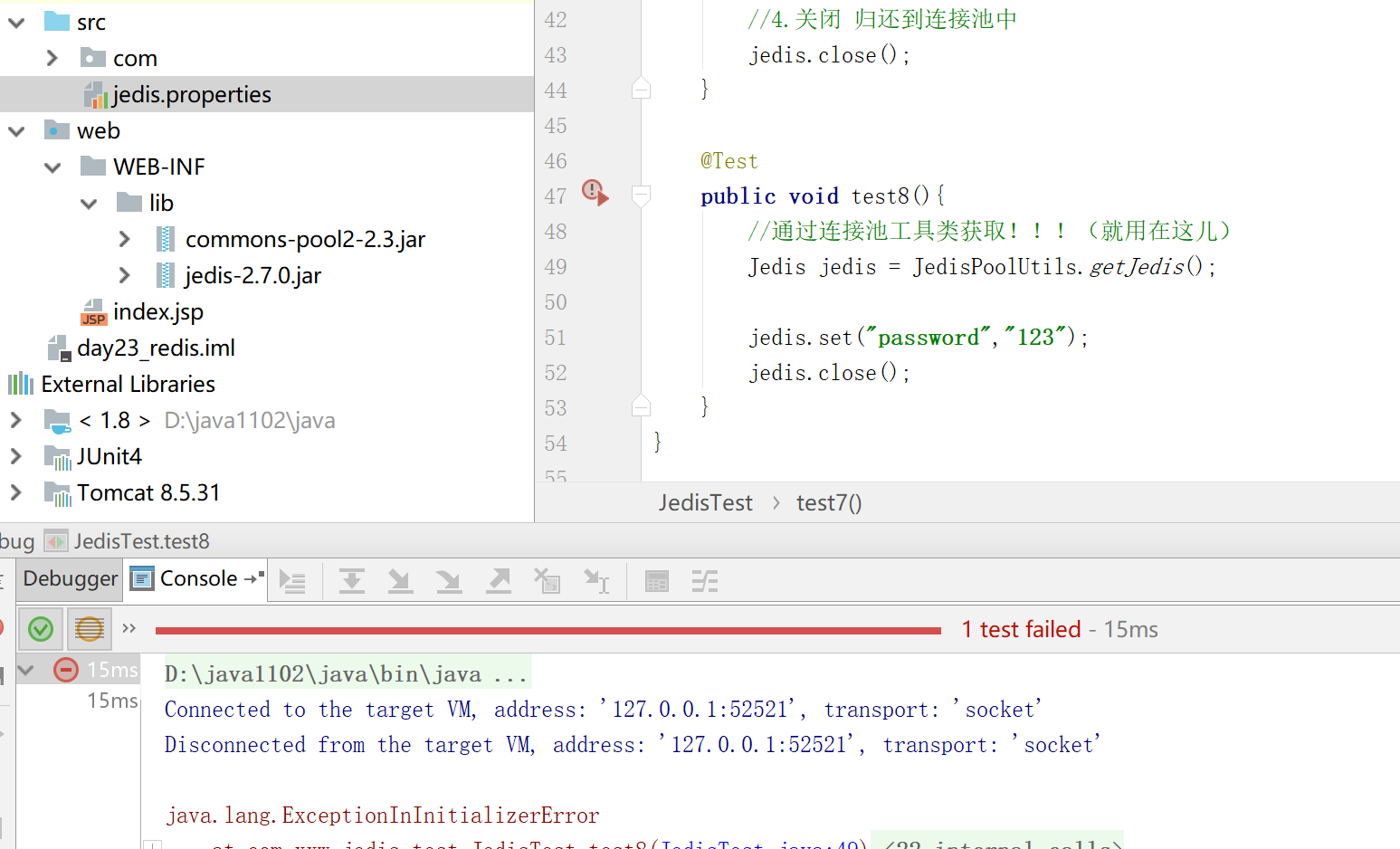
不知道为什么加载文件出错了。。。
----------------------------------------------------------------------------------------
是我文件名写错了。。。jedis.properties写成了jdeis 已经更正。
总之用法就是一行:Jedis jedis = JedisPoolUtils.getJedis();
------------------------------------------------------------------------------------------
## 案例:
案例需求:
1. 提供index.html页面,页面中有一个省份 下拉列表
2. 当 页面加载完成后 发送ajax请求,请求对应方法(url)加载数据库中所有省份用json传回来【之后@requestbody好像自动实现变成json?】到js方法的参数(data)中 【但是秒杀项目好像学了一个jquery填充回调数据?】
1.首先我们需要一个mysql的DB
CREATE DATABASE day23; -- 创建数据库 USE day23; -- 使用数据库 CREATE TABLE province( -- 创建表 id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) NOT NULL ); -- 插入数据 INSERT INTO province VALUES(NULL,'北京'); INSERT INTO province VALUES(NULL,'上海'); INSERT INTO province VALUES(NULL,'广州'); INSERT INTO province VALUES(NULL,'陕西');
2.导入相应jar包(关于mysql的那些,还有json解析用的jackson,还有jsp用的),web中创建js目录,导入druid.pro和JBDCUtil工具类
3.写无框架的三层架构web案例
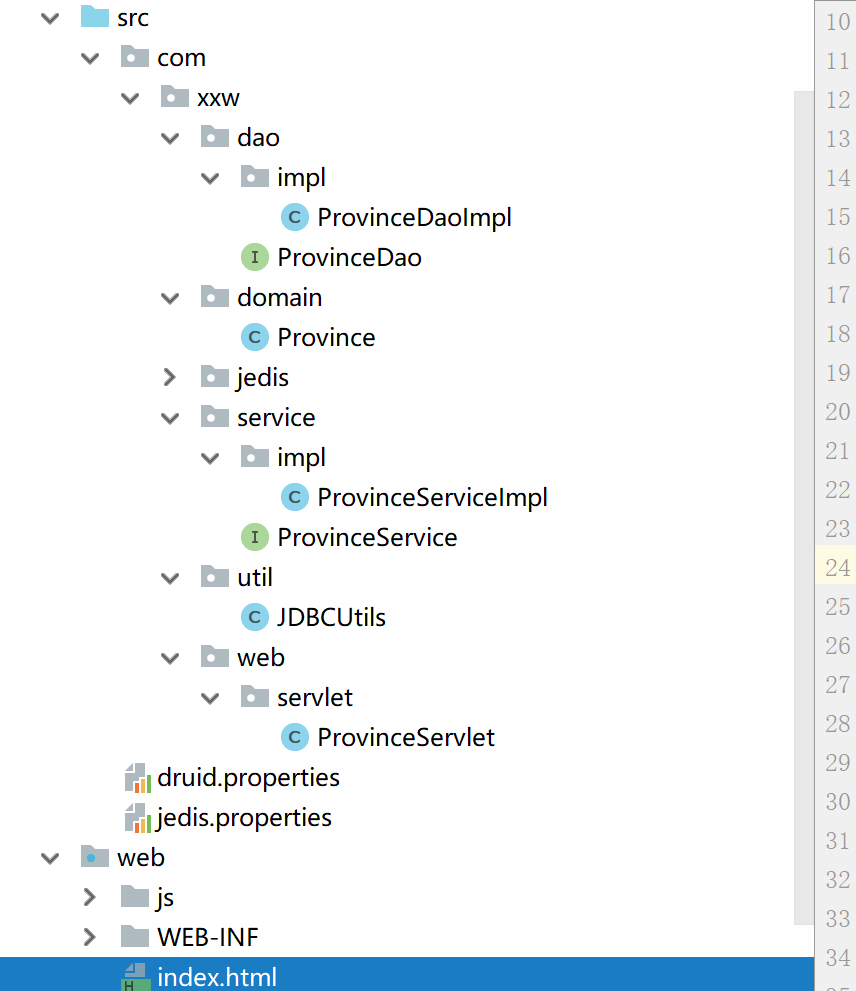
三个包:dao,service,web 再加domain包和util包
数据库操作就是findAll() 显示所有行用bean装着,list展示所有
public interface ProvinceDao { /* 查询所有方法 */ public List<Province> findAll(); }
public class ProvinceDaoImpl implements ProvinceDao { //1.声明成员变量 jdbcTemplement private JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource()); @Override public List<Province> findAll() { //1.定义sql String sql = "select * from province"; //2.执行sql 且把查询结果封装到bean里面 返回List集合 List<Province> list = template.query(sql, new BeanPropertyRowMapper<Province>(Province.class)); return list; } }
public interface ProvinceService { /* 查询所有 */ public List<Province> findAll(); }
public class ProvinceServiceImpl implements ProvinceService { //声明dao private ProvinceDao dao = new ProvinceDaoImpl(); @Override public List<Province> findAll() { return dao.findAll(); } }
@WebServlet("/ProvinceServlet")
public class ProvinceServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//1.调用service查询
ProvinceService service = new ProvinceServiceImpl();
List<Province> list = service.findAll();
//2.序列化list为json(jackson包)
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(list);
System.out.println(json);//[{"id":1,"name":"北京"},{"id":2,"name":"上海"},{"id":3,"name":"广州"},{"id":4,"name":"陕西"}]
//3.响应结果
response.setContentType("application/json;charset=utf-8");
response.getWriter().write(json);//把数据用response写出去就可以
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doPost(request, response);
}
}
public class Province { private int id; private String name; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } }
/** * JDBC工具类 使用Durid连接池 */ public class JDBCUtils { private static DataSource ds ; static { try { //1.加载配置文件 Properties pro = new Properties(); //使用ClassLoader加载配置文件,获取字节输入流 InputStream is = JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"); pro.load(is); //2.初始化连接池对象 ds = DruidDataSourceFactory.createDataSource(pro); } catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } /** * 获取连接池对象 */ public static DataSource getDataSource(){ return ds; } /** * 获取连接Connection对象 */ public static Connection getConnection() throws SQLException { return ds.getConnection(); } }
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="js/jquery-3.3.1.min.js"></script>
<script>
$(function () {
//这里面是页面加载完成后要干的事儿
//发送ajax请求,加载所有省份数据
$.get("ProvinceServlet",{},function(data){
//发送的json由data接到后是这样子的:[{"id":1,"name":"北京"},{"id":2,"name":"上海"},{"id":3,"name":"广州"},{"id":4,"name":"陕西"}]
//需要一个一个放到option里面去 这是前端做的事情
//1.获取select 根据id是用#这个符号 取元素用$这个符号(如果我没记错的话)
var province = $("#province");
//2.遍历json数组 each方法 each里面绑定一个function使得每遍历一次就会执行一次
$(data).each(function () {
//3.创建<option>标签 这操作没有见过啊
var option ="<option name='"+this.id+"'>"+this.name+"</option>"
//4.调用select的append追加option
province.append(option);
})
});
})
</script>
</head>
<body>
<select id="province">
<option>--请选择省份--</option>
</select>
</body>
</html>
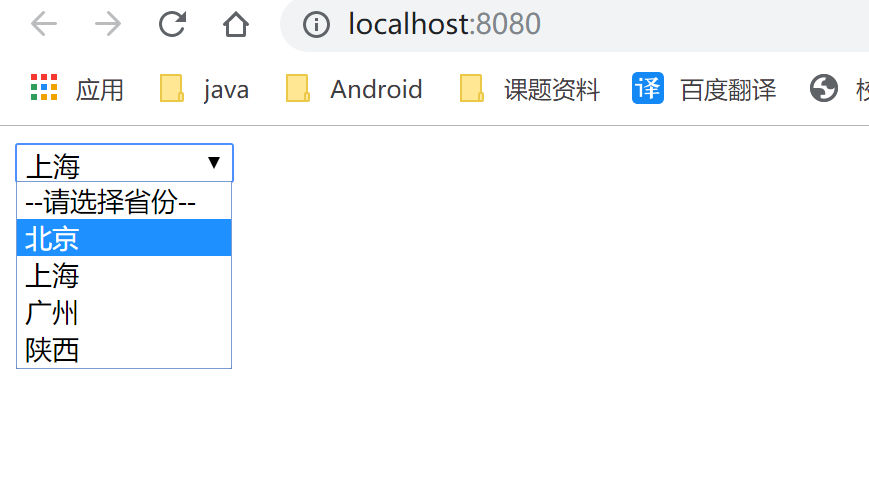
启动服务器,index.html实现效果如下:
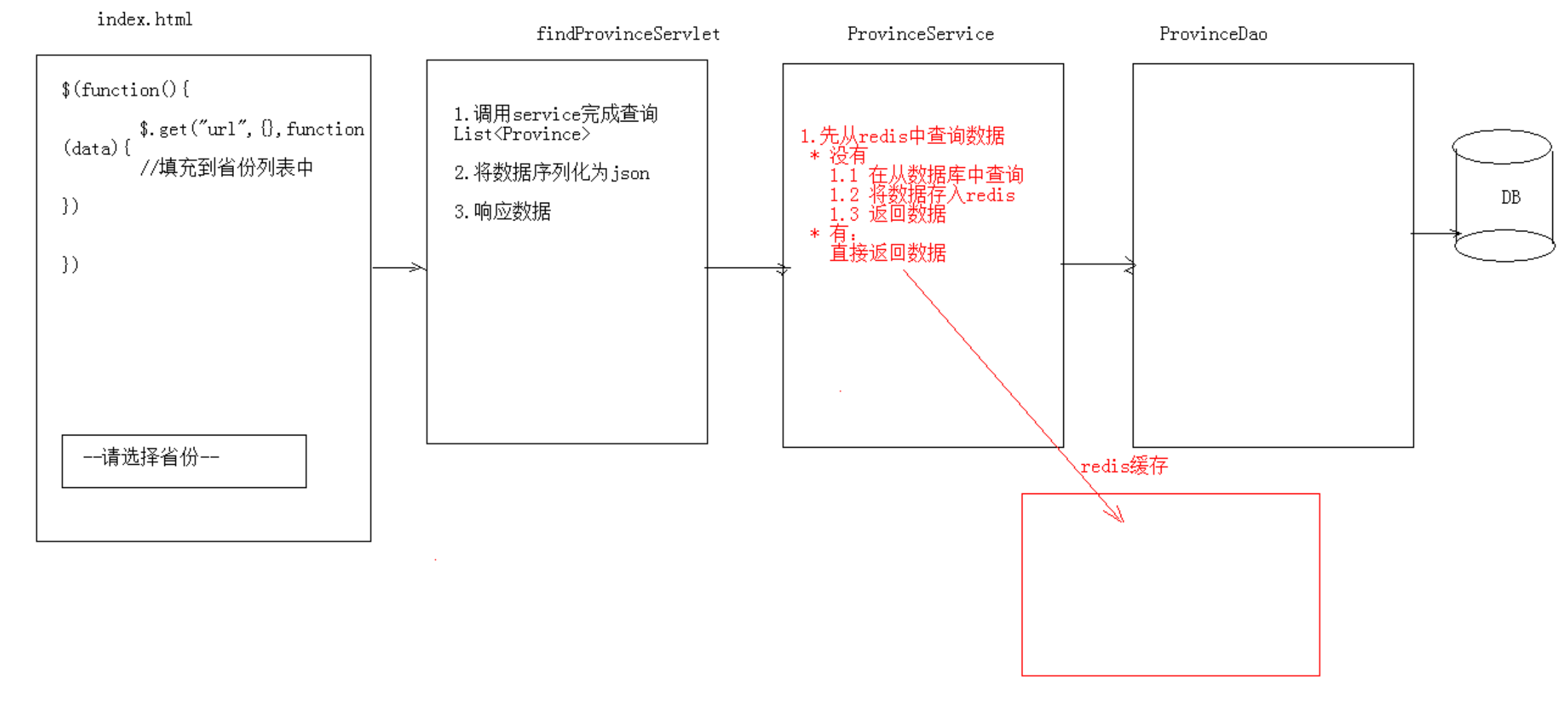
4.加入redis,实现缓存优化
添加redis缓存后,第一次读取数据需要访问mysql,然后数据就会缓存在redis中。下一次读取时,直接从缓存中读取即可。
在service接口中添加一个方法findAlljson()实现redis缓存:
public interface ProvinceService {
/*
查询所有
*/
public List<Province> findAll();
/**
* 使用redis缓存
*/
public String findAllJson();
}
serviceImpl中重写该方法:
@Override public String findAllJson() { //1.先从redis中查询数据 //1.1 获取redis客户端连接 Jedis jedis = JedisPoolUtils.getJedis(); String province_json = jedis.get("province"); //2.判断province_json是否为null if(province_json == null || province_json.length() == 0){ //redis中没有数据 System.out.println("redis中没有数据,查询数据库..."); //2.1 从数据库中查询 调用dao的方法就是 List<Province> ps = dao.findAll(); //2.2 将list序列化为json 因为redis存的也许要是json ObjectMapper mapper = new ObjectMapper(); try { province_json = mapper.writeValueAsString(ps);//key对应的value也要是json?这样value是个hashmap吧?? } catch (JsonProcessingException e) { e.printStackTrace(); } //2.3 将json数据存入redis中 jedis.set("province",province_json); //归还连接 jedis.close(); }else{ System.out.println("redis中有数据,查询缓存..."); } return province_json; }
修改Provinceservlet里的方法,不用findAll了,用这个findAllJson方法直接把json返回给前端
@WebServlet("/ProvinceServlet")
public class ProvinceServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
/* //1.调用service查询
ProvinceService service = new ProvinceServiceImpl();
List<Province> list = service.findAll();
//2.序列化list为json(jackson包)
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(list);
System.out.println(json);//[{"id":1,"name":"北京"},{"id":2,"name":"上海"},{"id":3,"name":"广州"},{"id":4,"name":"陕西"}]*/
//1.调用service查询 换这种直接查出json的方法
ProvinceService service = new ProvinceServiceImpl();
String json = service.findAllJson();
//3.响应结果
response.setContentType("application/json;charset=utf-8");
response.getWriter().write(json);//把数据用response写出去就可以
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doPost(request, response);
}
}
打开服务器,刷新页面,控制台显示

之后再刷新就都是走缓存redis去拿数据。
* 注意:使用redis缓存一些不经常发生变化的数据。
* 因为数据库的数据一旦发生改变,则需要更新缓存。
* 数据库的表执行 增删改的相关操作,需要将redis缓存数据情况,再次更新存入
* 在service对应的增删改方法中,将redis数据删除。