深度学习用于自然语言处理是将模式识别应用于单词、句子和段落,这与计算机视觉是将模式识别应用于像素大致相同。深度学习模型不会接收原始文本作为输入,它只能处理数值张量,因此我们必须将文本向量化(vectorize)。下图是主要流程。

one-hot编码是将每个单词与一个唯一的整数索引相关联,然后将这个整数索引 i 转换为长度为N的二进制向量(N是此表大小),这个向量只有第 i 个元素是1,其余都为0。
词嵌入是低维的浮点数向量,是从数据中学习得到的。
one-hot:高维度、稀疏
词嵌入:低维度、密集
这里我们重点介绍词嵌入!编译环境keras、jupyter Notebook
利用Embedding层学习词嵌入
应用场景:IMDB电影评论情感预测任务
1、准备数据(keras内置)
2、将电影评论限制为前10 000个最常见的单词
3、评论长度限制20个单词
4、将输入的整数序列(二维整数张量)转换为嵌入序列(三维浮点数张量),将这个张量展平为二维,最后在上面训练一个Dense层用于分类
# 将一个Embedding层实例化 from keras.layers import Embedding # (最大单词索引+1, 嵌入的维度) enmbedding_layer = Embedding(1000, 64)
加载数据、准备用于Embedding层
from keras.datasets import imdb from keras import preprocessing max_features = 10000 maxlen = 20 # 将数据加载为整数列表 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
在IMDB数据上使用Embedding层和分类器
from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) # 将三维的嵌入张量展平成(samples, maxlen * 8) model.add(Flatten()) # 在上面添加分类器 model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size = 32, validation_split=0.2)
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_2 (Embedding) (None, 20, 8) 80000 _________________________________________________________________ flatten_1 (Flatten) (None, 160) 0 _________________________________________________________________ dense_1 (Dense) (None, 1) 161 ================================================================= Total params: 80,161 Trainable params: 80,161 Non-trainable params: 0 _________________________________________________________________ Train on 20000 samples, validate on 5000 samples Epoch 1/10 20000/20000 [==============================] - 10s 517us/step - loss: 0.6759 - acc: 0.6050 - val_loss: 0.6398 - val_acc: 0.6814
......
Epoch 10/10 20000/20000 [==============================] - 3s 127us/step - loss: 0.2839 - acc: 0.8860 - val_loss: 0.5303 - val_acc: 0.7466
得到验证精度约为75%,我们仅仅将嵌入序列展开并在上面训练一个Dense层,会导致模型对输入序列中的每个单词处理,而没有考虑单词之间的关系和句子结构。更好的做法是在嵌入序列上添加循环层或一维卷积层,将整个序列作为整体来学习特征。
如果可用的训练数据很少,无法用数据学习到合适的词嵌入,那怎么办? ===> 使用预训练的词嵌入
使用预训练的词嵌入
这次,我们不使用keras内置的已经预先分词的IMDB数据,而是从头开始下载。
1. 下载IMDB数据的原始文本
地址:https://mng.bz/0tIo 下载原始IMDB数据集并解压
import os imdb_dir = 'F:/keras-dataset/aclImdb' train_dir = os.path.join(imdb_dir, 'train') labels = [] texts = [] for label_type in ['neg', 'pos']: dir_name = os.path.join(train_dir, label_type) for fname in os.listdir(dir_name): if fname[-4:] == '.txt': f = open(os.path.join(dir_name, fname), errors='ignore') texts.append(f.read()) f.close() if label_type == 'neg': labels.append(0) else: labels.append(1)
2. 对IMDB原始数据的文本进行分词
预训练的词嵌入对训练数据很少的问题特别有用,因此我们只采取200个样本进行训练
# 对数据进行分词 from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences import numpy as np # 在100个单词后截断评论 maxlen = 100 # 在200个样本上进行训练 training_samples = 200 # 在10000个样本上进行验证 validation_samples = 10000 # 只考虑数据集中前10000个最常见的单词 max_words = 10000 tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts) word_index = tokenizer.word_index print('Found %s unique tokens.' % len(word_index)) data = pad_sequences(sequences, maxlen=maxlen) labels = np.asarray(labels) print('Shape of data tensor:', data.shape) print('Shape of label tensor:', labels.shape) # 将数据划分为训练集和验证集,但首先要打乱数据 # 因为一开始数据中的样本是排好序的(所有负面评论在前,正面评论在后) indices = np.arange(data.shape[0]) np.random.shuffle(indices) data = data[indices] labels = labels[indices] x_train = data[:training_samples] y_train = labels[:training_samples] x_val = data[training_samples: training_samples + validation_samples] y_val = labels[training_samples: training_samples + validation_samples]
Found 88583 unique tokens. Shape of data tensor: (25000, 100) Shape of label tensor: (25000,)
3. 下载GloVe词嵌入
地址:https://nlp.stanford.edu/projects/glove/ 文件名是glove.6B.zip,里面包含400 000个单词的100维向量。解压文件
对解压文件进行解析,构建一个单词映射为向量表示的索引
# 解析GloVe词嵌入文件 glove_dir = 'F:/keras-dataset' embeddings_index = {} f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), errors='ignore') for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype='float32') embeddings_index[word] = coefs f.close() print('Found %s word vectors.' % len(embeddings_index)) # 创建一个可以加载到Embedding层中的嵌入矩阵 # 对于单词索引中索引为i的单词,这个矩阵的元素i就是这个单词对应的 embedding_dim 为向量 embedding_dim = 100 embedding_matrics = np.zeros((max_words, embedding_dim)) for word, i in word_index.items(): embedding_vector = embeddings_index.get(word) if i < max_words: if embedding_vector is not None: embedding_matrics[i] = embedding_vector
Found 399913 word vectors.
4. 定义模型
# 模型定义 from keras.models import Sequential from keras.layers import Embedding, Flatten, Dense model = Sequential() model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_3 (Embedding) (None, 100, 100) 1000000 _________________________________________________________________ flatten_2 (Flatten) (None, 10000) 0 _________________________________________________________________ dense_2 (Dense) (None, 32) 320032 _________________________________________________________________ dense_3 (Dense) (None, 1) 33 ================================================================= Total params: 1,320,065 Trainable params: 1,320,065 Non-trainable params: 0
6. 在模型中加载GloVe嵌入
Embedding层只有一个权重矩阵,是一个二维的浮点数矩阵,其中每个元素i是索引i相关联的词向量,将准备好的GloVe矩阵加载到Embedding层中,即模型的第一层
# 将预训练的词嵌入加载到Embedding层 model.layers[0].set_weights([embedding_matrics]) # 冻结Embedding层 model.layers[0].trainable = False
7. 训练和评估模型
# 训练模型与评估模型 model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val)) model.save_weights('pre_trained_glove_model.h5')
Train on 200 samples, validate on 10000 samples Epoch 1/10 200/200 [==============================] - 1s 4ms/step - loss: 0.9840 - acc: 0.5300 - val_loss: 0.6942 - val_acc: 0.4980
........
Epoch 10/10 200/200 [==============================] - 0s 2ms/step - loss: 0.0598 - acc: 1.0000 - val_loss: 0.8704 - val_acc: 0.5339
8. 绘制结果
# 绘制图像 import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show()
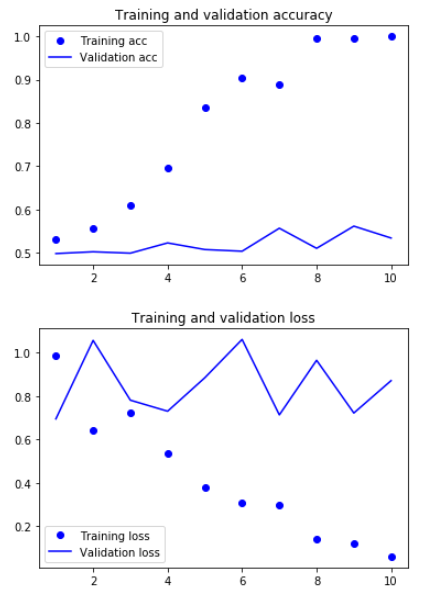
模型很快就开始过拟合,因为训练样本很少,效果不是很好。验证集的精度56%
9. 对测试集数据进行分词,并对数据进行评估模型
# 对测试集数据进行分词 test_dir = os.path.join(imdb_dir, 'test') labels = [] texts = [] for label_type in ['neg', 'pos']: dir_name = os.path.join(test_dir, label_type) for fname in sorted(os.listdir(dir_name)): if fname[-4:] == '.txt': f = open(os.path.join(dir_name, fname), errors='ignore') texts.append(f.read()) f.close() if label_type == 'neg': labels.append(0) else: labels.append(1) sequences = tokenizer.texts_to_sequences(texts) x_test = pad_sequences(sequences, maxlen=maxlen) y_test = np.asarray(labels) # 在测试集上评估模型 model.load_weights('pre_trained_glove_model.h5') model.evaluate(x_test, y_test)
测试精度达到53%,效果还可以,因为我们只使用了很少的训练样本
在不使用预训练词嵌入的情况下,训练相同的模型
# 在不使用预训练词嵌入的情况下,训练相同的模型 from keras.models import Sequential from keras.layers import Embedding, Flatten, Dense model = Sequential() model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.summary() model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
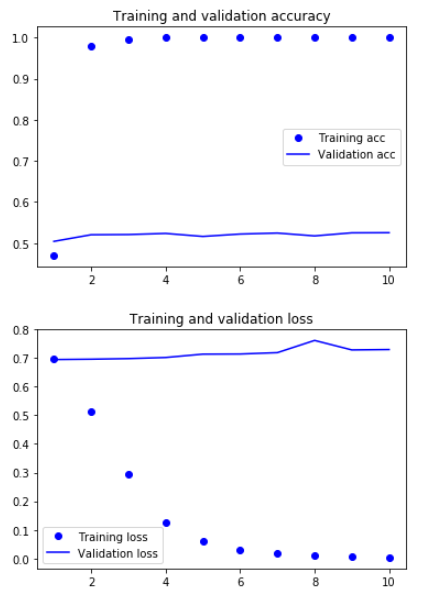
验证集的精度大概52%