一、K近邻
有两个类,红色、蓝色。我将红色点标记为0,蓝色点标记为1。还要创建25个训练数据,把它们分别标记为0或者1。Numpy中随机数产生器可以帮助我们完成这个任务
import cv2 import numpy as np import matplotlib.pyplot as plt # 包含25个已知/训练数据的(x,y)值的特征集 trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32) # 用数字0和1分别标记红色和蓝色 responses = np.random.randint(0, 2, (25, 1)).astype(np.float32) # 画出红色的点 red = trainData[responses.ravel() == 0] plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^') # 画出蓝色的点 blue = trainData[responses.ravel() == 1] plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's') plt.show()
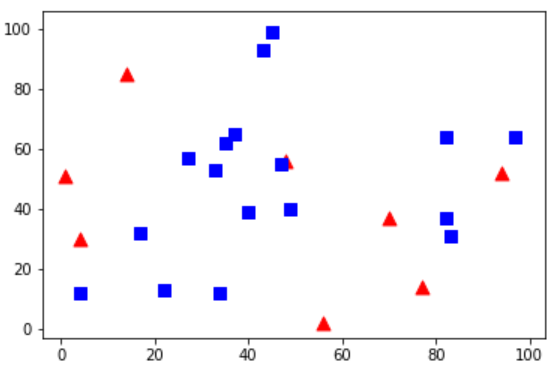
很有可能你运行的图和我的不一样,因为使用了随机数产生器,每次运行代码都会得到不同的结果。
下面就是KNN算法分类器的初始化,我们要传入一个训练数据集,以及对应的label。我们给它一个测试数据,让它来进行分类。OpenCV中使用knn.findNearest()函数
参数1:测试数据
参数2:k的值
返回值1:由kNN算法计算得到的测试数据的类别标志(0 或 1)。如果你想使用最近邻算法,只需要将k设置1,k就是最近邻的数目
返回值2:k的最近邻居的类别标志
返回值3:每个最近邻居到测试数据的距离
测试数据被标记为绿色。
# newcomer为测试数据 newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32) plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o') knn = cv2.ml.KNearest_create() knn.train(trainData, cv2.ml.ROW_SAMPLE, responses) ret, results, neighbours, dist = knn.findNearest(newcomer, 3) print("result: ", results, " ") print("neighbours: ", neighbours," ") print("distance: ", dist) plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^') plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's') plt.show()
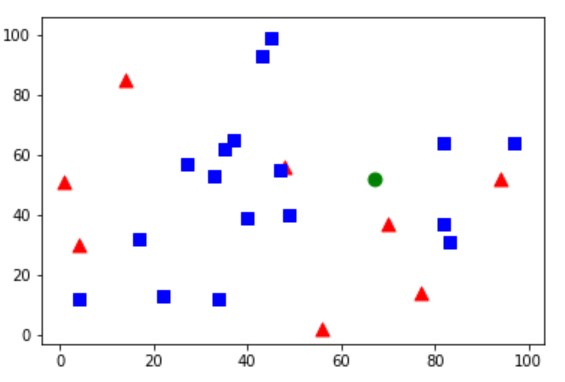
下面是我得到的结果:
result: [[0.]] neighbours: [[0. 1. 0.]] distance: [[234. 369. 377.]]
测试数据有三个邻居,有两个是红色,一个是蓝色。因此测试数据被分为红色。
二、使用kNN对手写数字OCR
OCR(Optical Character Recognition,光学字符识别)
目标
1. 要根据我们掌握的kNN知识创建一个基本的OCR程序
2. 使用OpenCV自带的手写数字和字母数据测试我们的程序
手写数字的OCR
我们的目的是创建一个可以对手写数字进行识别的程序。需要训练数据和测试数据。OpenCV 安装包中有一副图片(/samples/python2/data/digits.png),其中有一幅有5000个手写数字(每个数字重复500遍)。每个数字是一个20x20的小图。所以第一步就是将这个图像分割成5000个不同的数字,将拆分后的每一个数字图像展成400个像素点的图像(1x400的一维向量)。这个就是我们的特征集,所有像素的灰度值。我们使用每个数字的前250个样本做训练数据,剩余的250个做测试数据。
import numpy as np import cv2 import matplotlib.pyplot as plt img = cv2.imread('digits.png') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 我们把图片分成5000张,每张20 x 20 cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)] # 使cells变成一个numpy数组,它的维度为(50, 100, 20, 20) x = np.array(cells) # 训练数据和测试数据 train = x[:, :50].reshape(-1, 400).astype(np.float32) # size = (2500, 400) test = x[:, 50:100].reshape(-1, 400).astype(np.float32) # size = (2500, 400) # 为训练集和测试集创建一个label k = np.arange(10) train_labels = np.repeat(k, 250)[:, np.newaxis] test_labels = train_labels.copy() # 初始化KNN,训练数据、测试KNN,k=5 knn = cv2.ml.KNearest_create() knn.train(train, cv2.ml.ROW_SAMPLE, train_labels) ret, result, neighbours, dist = knn.findNearest(test, k=5) # 分类的准确率 # 比较结果和test_labels matches = result==test_labels correct = np.count_nonzero(matches) accuracy = correct * 100.0 / result.size print(accuracy)
结果为:
91.76
为了避免每次运行程序都要准备和训练分类器,我们最好把它保留,这样在下次运行时,只需要从文件中读取这些数据开始进行分类就可以了。
# 保留数据 np.savez('knn_data.npz', train=train, train_labels=train_labels) # 加载数据 with np.load('knn_data.npz') as data: print(data.files) train = data['train'] train_labels = data['train_labels']
结果为:
['train', 'train_labels']
英文字母的OCR
接下来我们来做英文字母的OCR。和上面做法一样,但是数据和特征集有一些不同。OpenCV自带的数据文件(/samples/cpp/letter-recognition.data)。有20000行,每一行的第一列是我们的一个字母标记,接下来的16个数字是它的不同特征。取前10000个作为训练样本,剩下的10000个作为测试样本。我们先把字母表换成ascII,因为我们不直接处理字母。
data = np.loadtxt('letter-recognition.data', dtype='float32', delimiter=',', converters={0:lambda ch:ord(ch) - ord('A')}) # 将数据分成2份,10000个训练,10000个测试 train, test = np.vsplit(data, 2) # 将训练集和测试集分解为数据、label # 实际上每一行的第一列是我们的一个字母标记。接下来的 16 个数字是它的不同特征。 responses, trainData = np.hsplit(train, [1]) # 数据从第二列开始 labels, testData = np.hsplit(test, [1]) # 初始化KNN,训练数据、测试KNN,k=5 knn = cv2.ml.KNearest_create() knn.train(trainData, cv2.ml.ROW_SAMPLE, responses) ret, result, neighbours, dist = knn.findNearest(testData, k=5) # 分类的准确率 # 比较结果和test_labels correct = np.count_nonzero(result==labels) accuracy = correct * 100.0 / result.size print(accuracy)
结果为:
93.06