一个partition只能被同一个消费组内一个消费者消费,所以在同一时间点上,订阅到同一个partition的consumer必然属于不同的Consumer Group.
因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于同时运行的consumer的数量
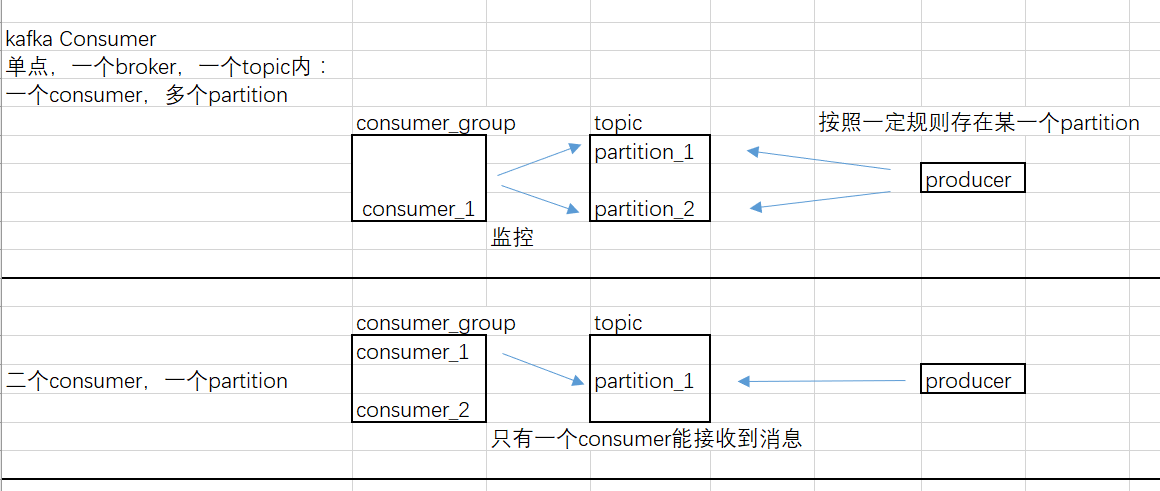
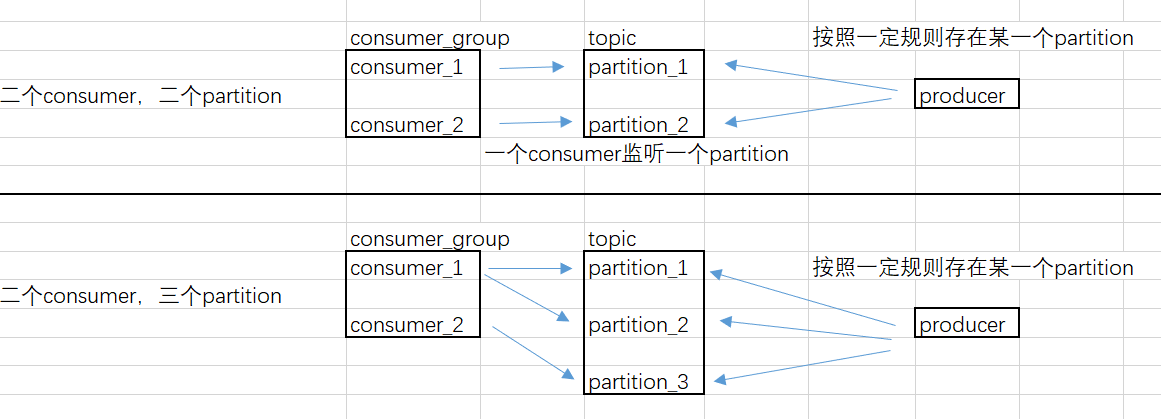
Consumer Group与Consumer的关系是动态维护的:
当一个Consumer 进程挂掉 或者是卡住时,该consumer所订阅的partition会被重新分配到该group内的其它的consumer上。当一个consumer加入到一个consumer group中时,同样会从其它的consumer中分配出一个或者多个partition 到这个新加入的consumer。当启动一个Consumer时,会指定它要加入的group,使用的是配置项:group.id。
为了维持Consumer 与 Consumer Group的关系,需要Consumer周期性的发送heartbeat到coordinator(协调者,在早期版本,以zookeeper作为协调者。后期版本则以某个broker作为协调者)。当Consumer由于某种原因不能发Heartbeat到coordinator时,并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。而这个过程,被称为rebalance。
poll 方法
Consumer读取partition中的数据是通过调用发起一个fetch请求来执行的。而从KafkaConsumer来看,它有一个poll方法。但是这个poll方法只是可能会发起fetch请求。原因是:Consumer每次发起fetch请求时,读取到的数据是有限制的,通过配置项max.partition.fetch.bytes来限制的。而在执行poll方法时,会根据配置项个max.poll.records来限制一次最多pool多少个record.
那么就可能出现这样的情况: 在满足max.partition.fetch.bytes限制的情况下,假如fetch到了100个record,放到本地缓存后,由于max.poll.records限制每次只能poll出15个record。那么KafkaConsumer就需要执行7次才能将这一次通过网络发起的fetch请求所fetch到的这100个record消费完毕。其中前6次是每次pool中15个record,最后一次是poll出10个record。
在consumer中,还有另外一个配置项:max.poll.interval.ms ,它表示最大的poll数据间隔,如果超过这个间隔没有发起pool请求,但heartbeat仍旧在发,就认为该consumer处于 livelock状态。就会将该consumer退出consumer group。所以为了不使Consumer 自己被退出,Consumer 应该不停的发起poll(timeout)操作。而这个动作 KafkaConsumer Client是不会帮我们做的,这就需要自己在程序中不停的调用poll方法了。
offset存储
在kafka 0.9版本之后,kafka为了降低zookeeper的io读写,减少network data transfer,也自己实现了在kafka server上存储consumer,topic,partitions,offset信息将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中。
kafka高可用
为了保证kafka的高可用(当leader节点挂了之后,kafka依然能提供服务)kafka提供了备份的功能。这个备份是针对partition的。
每个partition会选举一个Leader,其它Replicas作为Follower,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路)
通过kafka manager可以很直观看到,如下:
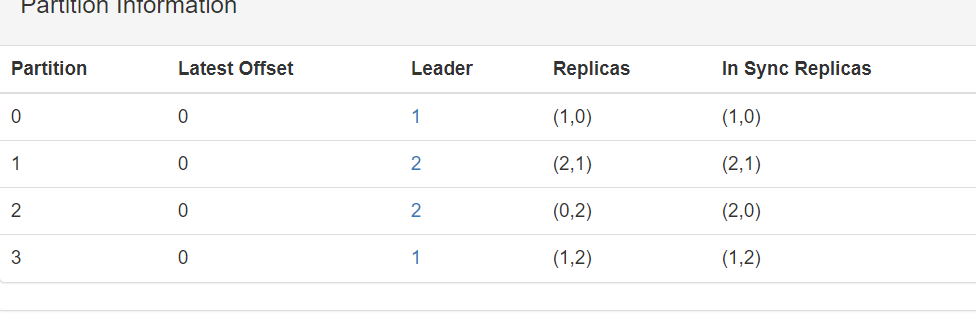
Partition 1,Leader是broker 1,其它Replicas是Follower。