通过内存创建RDD的分区设置
1、示例代码
在创建RDD的时候,我们可以从内存中进行创建;输出保存为文件。为了演示效果,我们的示例代码如下:
1 import org.apache.spark.{SparkConf, SparkContext} 2 3 object Spark02RddParallelizeSet { 4 def main(args: Array[String]): Unit = { 5 System.setProperty("hadoop.home.dir", "C:\Hadoop\") 6 val spark = new SparkConf().setMaster("local[*]").setAppName("RddParallelizeSet") 7 val context = new SparkContext(spark) 8 9 val list = List(1, 2, 3, 4) 10 11 // TODO: 从内存创建RDD,并且设置并行执行的任务数量 12 // numSlices: Int = defaultParallelism 13 val memoryRDD = context.makeRDD(list, 1) 14 memoryRDD.saveAsTextFile("output") 15 16 val memoryRDD1 = context.makeRDD(list, 2) 17 memoryRDD1.saveAsTextFile("output1") 18 19 val memoryRDD2 = context.makeRDD(list, 3) 20 memoryRDD2.saveAsTextFile("output2") 21 22 val memoryRDD3 = context.makeRDD(list, 4) 23 memoryRDD3.saveAsTextFile("output3") 24 25 val memoryRDD4 = context.makeRDD(list, 5) 26 memoryRDD4.saveAsTextFile("output4") 27 28 // TODO: 结束 29 context.stop() 30 } 31 }
上面的代码里,我们从内存中创建了5个RDD,每个RDD设置了不同的分区数。
2、执行结果
(1)1个分区的RDD,效果如下图所示:
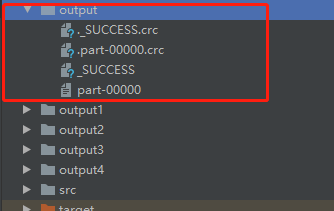
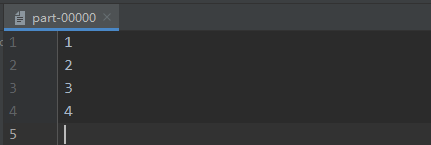
在output文件夹中,只包含了一个分区文件 part-00000 ,其文件内容如下图所示:
(2)2个分区的RDD,效果如下图所示:
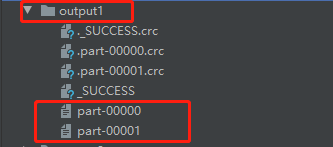
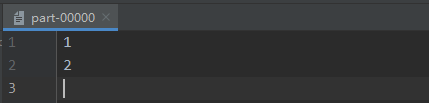
在output1文件夹中,包含了两个分区文件 part-00000 以及 part-00001,二者文件内容如下图所示:

(3)3个分区的RDD,效果如下图所示:
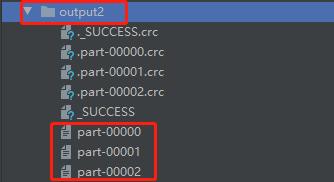
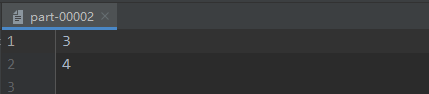
在output2文件夹中,包含了三个分区文件 part-00000 、part-00001、part-00002,三者文件内容如下图所示:


(4)4个分区的RDD,效果如下图所示:
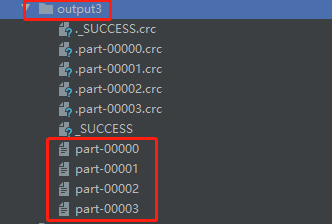
在output3文件夹中,包含了四个分区文件 part-00000、part-00001、part-00002、part-00003,四者文件内容如下图所示:




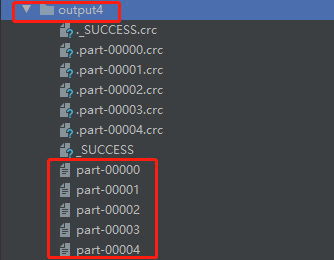
在output4文件夹中,包含了五个分区文件 part-00000、part-00001、part-00002、part-00003、part-00004,五者文件内容如下图所示:





3、分析结果
仔细看看上面图片中的结果,不难发现其中肯定深藏猫腻。不同分区数的设置,都存在不同的输出效果。要想深究其中缘由,有必要去了解Spark的在这一块的源码实现。进入到 makeRDD( ) 这个方法中,可以看到如下源码:
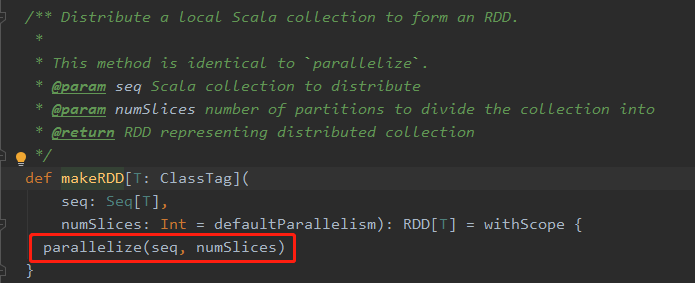
在图片中用红色方框框起来的部分,是一个方法,其中传入了两个参数,第一个 seq 就是在我们自己写的代码中,自己定义的那个 List;第二个 numSlices 就是我们自己写的代码中的那个分区数。
再点进 parallelize( seq, numSlices) 这个方法中去,可以看到如下源码:
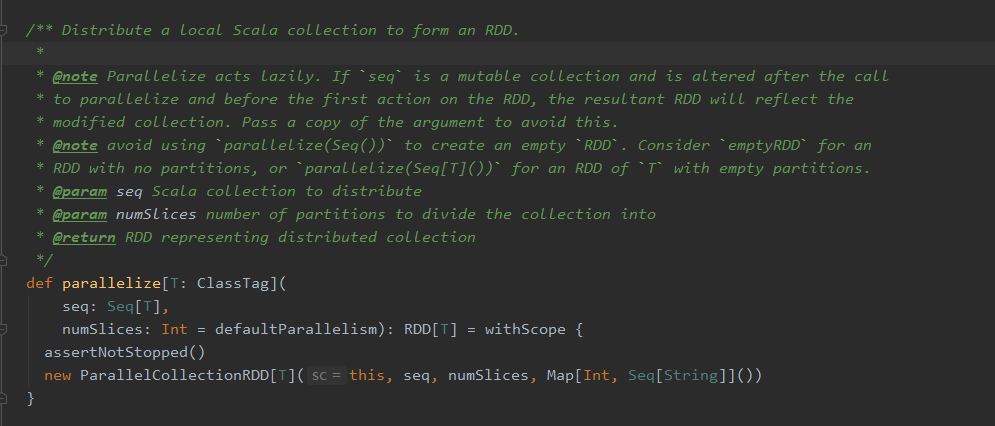
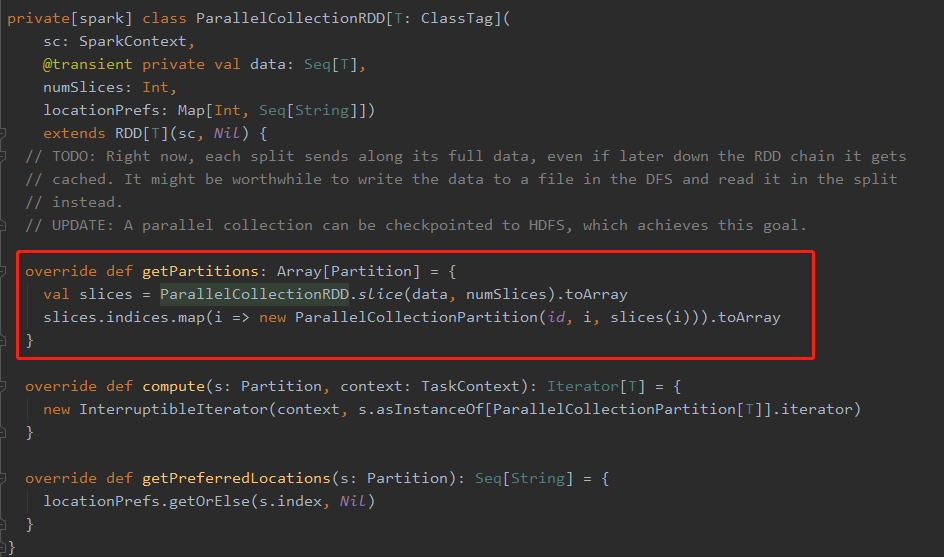
红色线框框出的这个名为 getPartitions 的方法,返回的是一个分区的数组,ParallelCollectionRDD.slice( ) 调用的是 ParallelCollectionRDD 伴生对象里面的一个方法,看样子应该是这个方法里的代码规定了怎么进行分区的划分了,于是,进到这个方法里面,果不其然,可以看到如下代码块:

在 slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] 这个方法中,我们可以看到一个关于 seq 这个传入的参数的模式匹配:
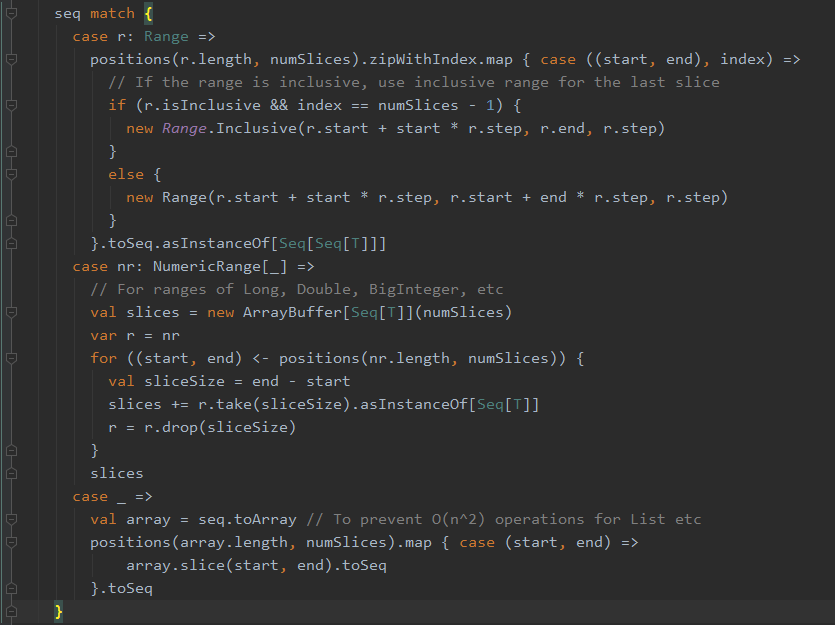
在上图的这一段代码中,模式匹配第一个匹配的是 Range 类型,很明显与我们传入的 List 类型不一致,因此 case r: Range 这一块的匹配代码可以跳过。第二个匹配的也是Range,相比于第一个匹配的Range 整形类型 而言,第二个则可以匹配更多种类型的 Range。当然第二个case也不是我们要看的。那么就剩下第三个 "case _" 这种情况了。
在第三个情况中,首先将 我们传入的 List 转换为了一个 array,为什么要有这一步,源码中也给出了注释:To prevent O(n ^ 2) operations for List etc。之后调用了positions( ) 方法,将转换后的数组的长度以及分区数量传入,该方法源码如下:
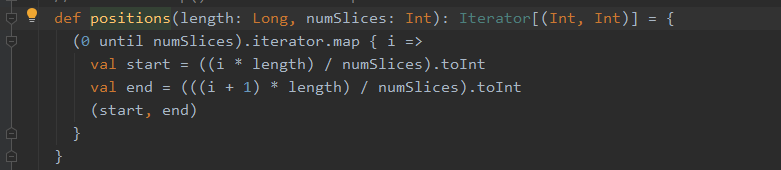
我的分析过程如下,数据是(1,2,3,4),分区数量是1的情况:
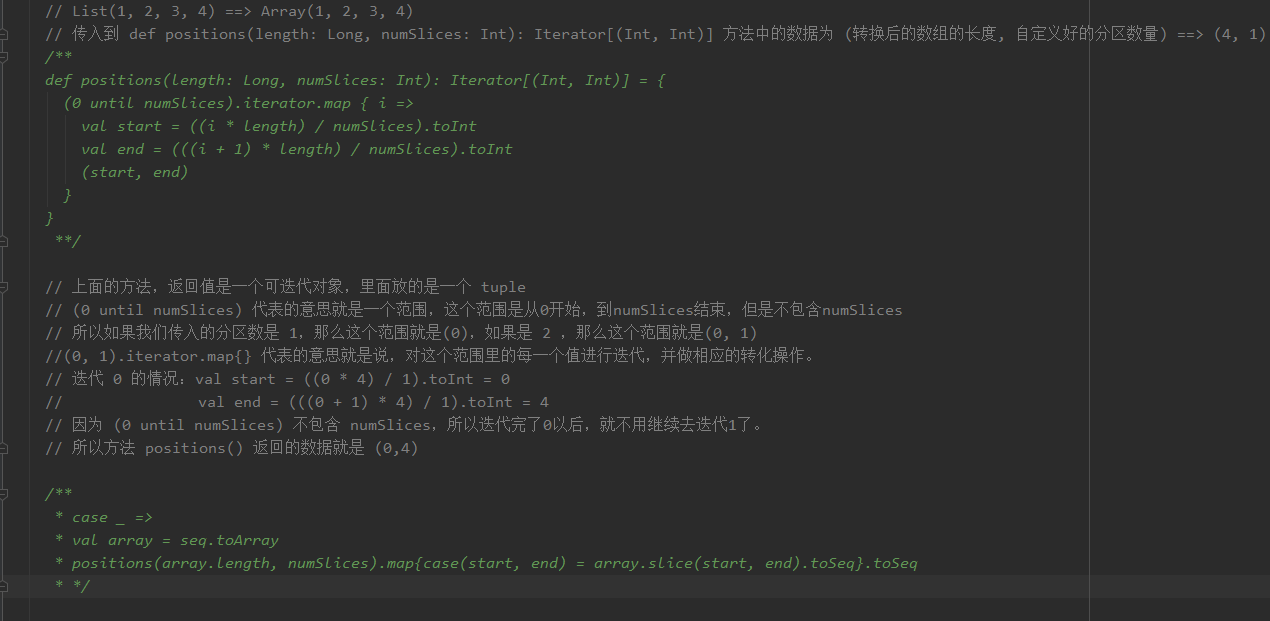
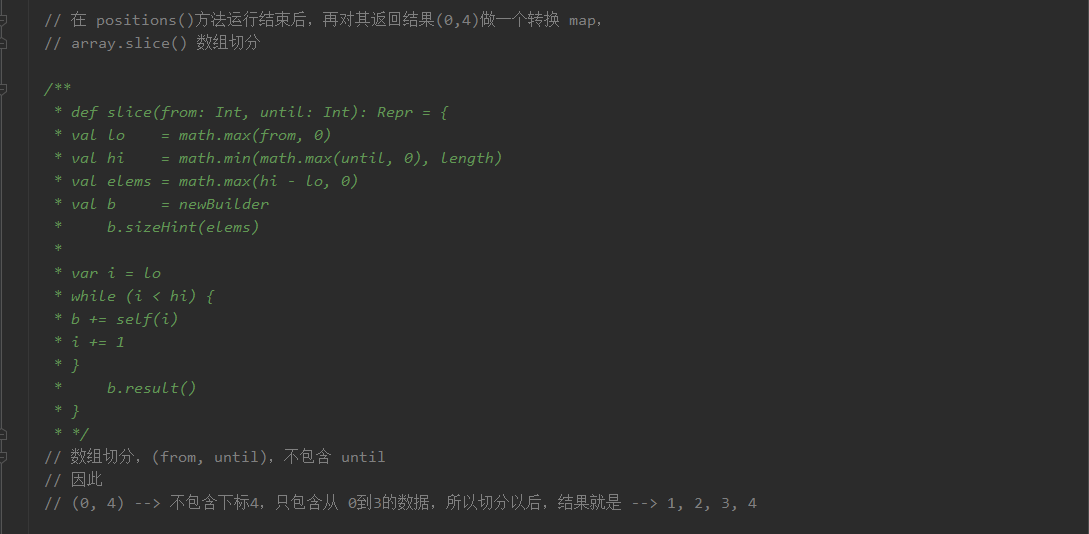
4、小结