索引的存储分类;mysql目前提供了以下4种索引
【1】B-Tree索引:最常见的索引类型,大部分引擎都支持B树索引
【2】HASH索引:只有Memory引擎支持,使用场景简单
【3】R-Tree索引(空间索引):空间索引是myIsam的一个特殊索引类型,主要用于地理空间数据类型。
【4】FULL-TEXT(全文索引):全文索引也是MyISAM的一个特殊索引类型。InnoDB从Mysql5.6版本开始也提供全文索引的支持。
注意,mysql目前不支持函数索引,但是能支持前缀索引(即取字段的前N个字符来做索引)。

0、快速了解索引系列
0.1、索引系列思维导图

0.2、数据页的组成
MySQL的基本存储结构是页(记录都存在页里边):
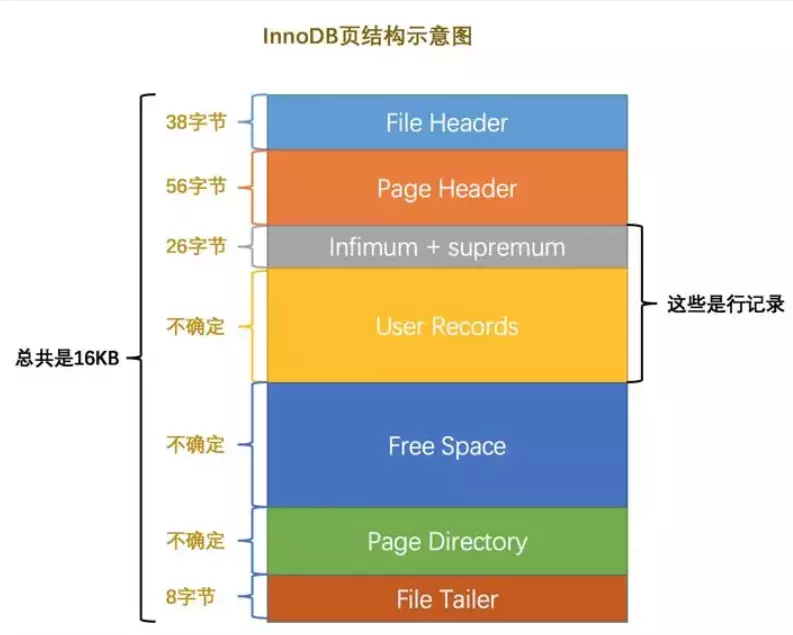
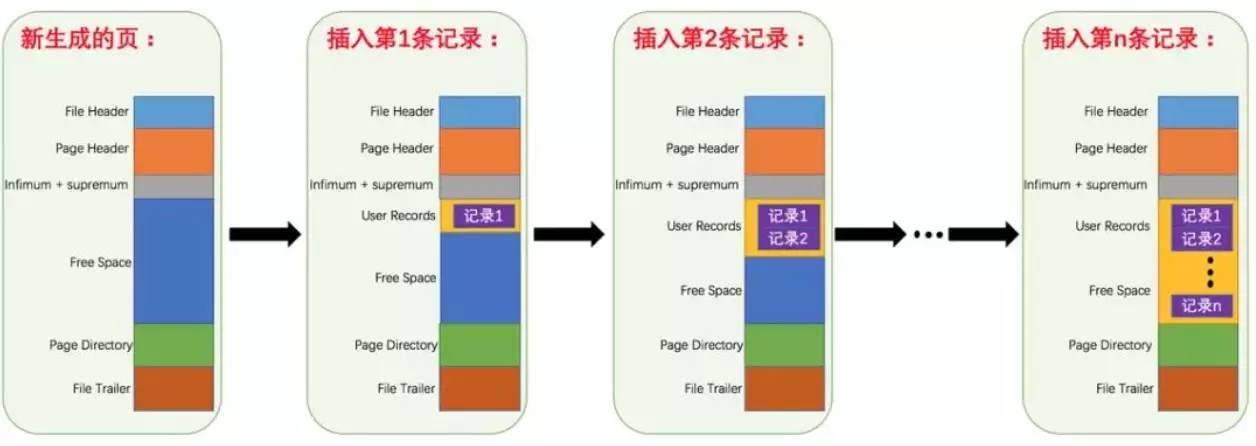
- 各个数据页可以组成一个双向链表
- 每个数据页中的记录又可以组成一个单向链表
- 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
- 定位到记录所在的页:需要遍历双向链表,找到所在的页
- 从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了
很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为O(n)。
0.3、B树索引的组织方式
索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):
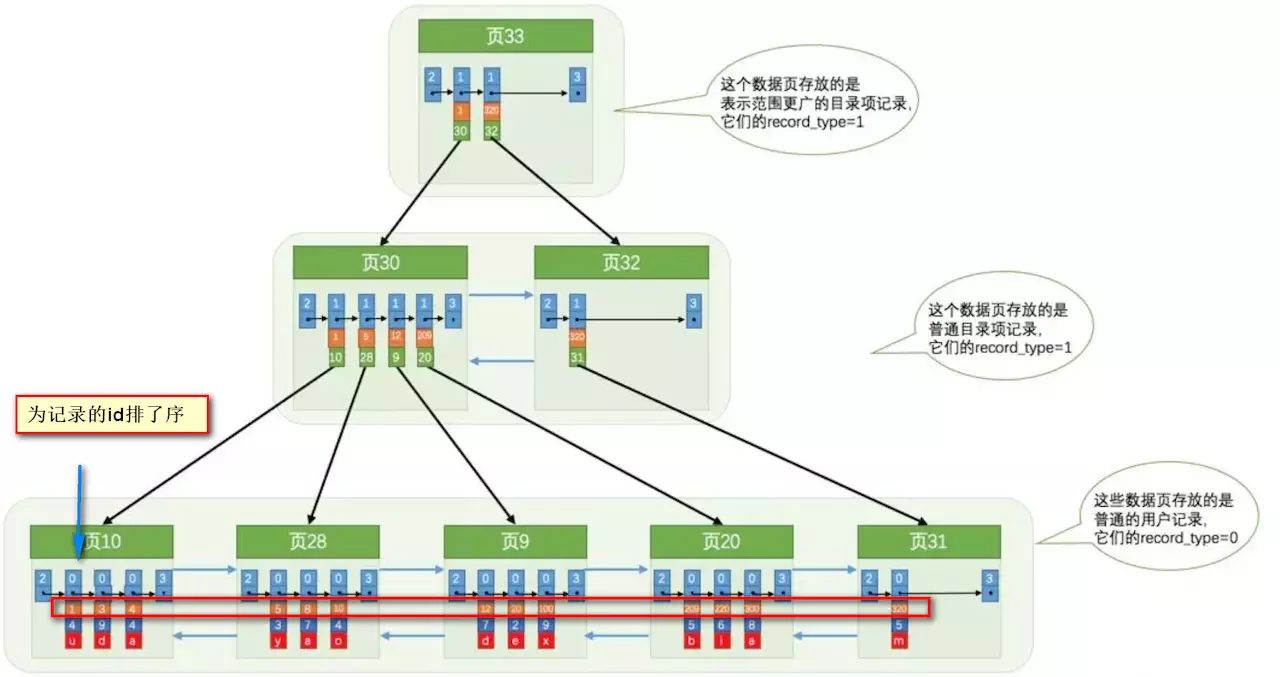
0.4、B树索引的检索方式
要找到id为8的记录简要步骤:
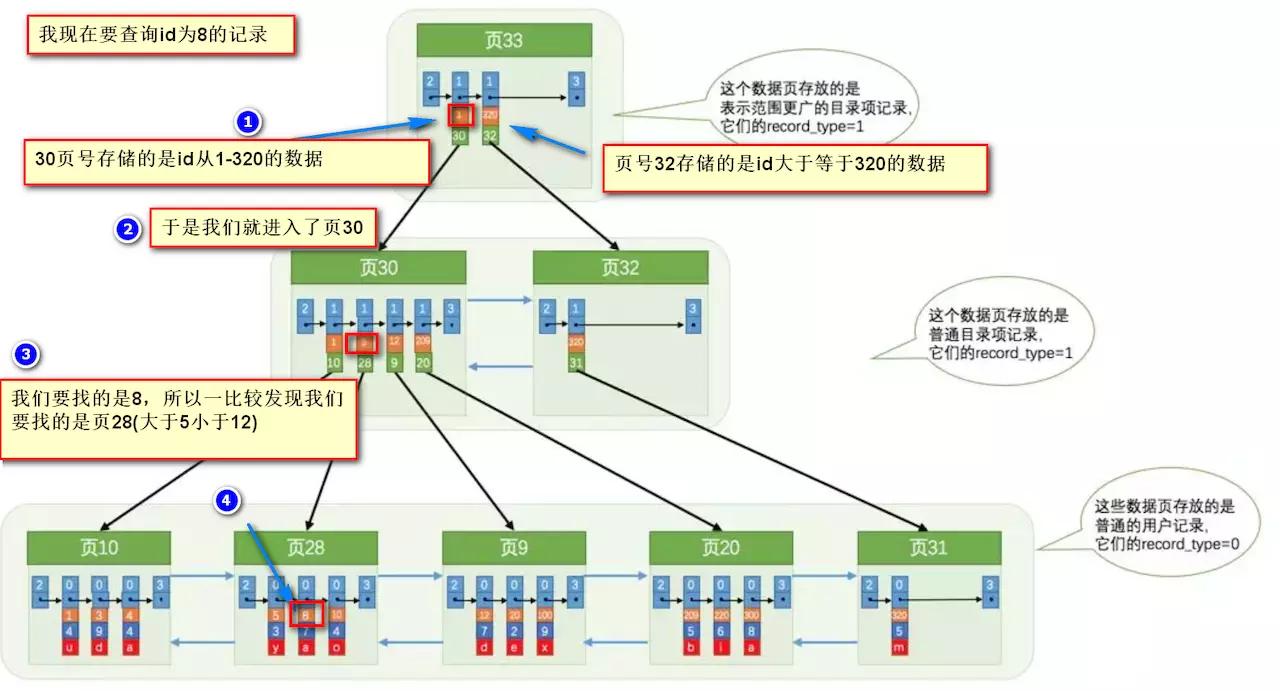
很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 “目录” 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为O(logn))
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
1、索引概述
【1.1】mysql每个表至少可以支持16个索引
【1.2】myISAM和InnoDB存储引擎的表默认创建的都是BTREE索引。
【1.3】mysql不支持函数索引,但支持前缀索引(myISAM支持1000字节长,InnoDB支持767字节长)
【1.4】mysql支持全文索引(fullText),但是只有myISAM存储引擎支持,5.7及之后InnoDB也支持
【1.5】mysql的memory存储引擎支持hash和btree
2、基本形式
-- 2.1 直接创建模式 CREATE [unique | fulltext | spatial] INDEX index_name [USING index_type] ON table_name(index_col_name) (1)index_col_name:col_name[ (length) ] [ASC|DESC] (2)index_type: USING{BTREE | HASH} 举例:create index ix_cityName on city(city_name(10)); -- 2.2 使用alter table 增加索引 ALTER [ONLINE | OFFLINE] [IGNORE] TABLE table_name [ADD|DROP] [INDEX | KEY] index_name [index_type](index_col_name...) [index_option] (1)index_col_name:col_name[ (length) ] [ASC|DESC] (2)index_type: USING{BTREE | HASH} 举例:alter table city add index ix_cityName using btree(city_name(10) ASC)
3、索引的设计原则
【3.1】搜索的索引列,即where中常用的
【3.2】使用唯一索引,索引重复值越少,索引效果越好
【3.3】使用短索引,索引越短占用空间越少,扫描速度越快
【3.4】利用左前缀(复合索引),只有最左边那个列最高效
【3.5】不要过度索引,一般不超过5个
【3.6】InnoDB存储引擎的表,默认会按一定顺序保存,如果有主键就按主键顺序保存,如果没有主键有唯一索引就按唯一索引顺序保存,如果都没有则表中会自动生成一个内部列,按照这个列的顺序保存。
4、mysql中能够使用索引的经典场景
【4.1】匹配全值:对索引中的所有列都指定具体值
【4.2】匹配值的范围查询:对索引的值能够进行范围查找
【4.3】复合索引(多列组成的索引):仅仅使用索引中最左边的列进行查找
【4.4】仅对索引字段进行查询(index only query):当查询的列(即select column...from tab)都在索引字段时,查询效率更改(如MSSQL中的覆盖索引)
【4.5】匹配列前缀(Match a column prefix):当有前缀索引时,仅仅使用索引的第一列,并且只包含索引第一列的开头一部分进行查找。
【4.6】column is null:如果列是索引列,则使用column is null也会走索引(这和Oracle和MSSQL均不同)
5、mysql中不能使用B-tree索引的经典场景
【5.1】以%开头的like查询:原因是B-TREE索引结构原理,这种一般可以用全文索引
【5.2】数据类型出现隐式转换:因为转换后类型与索引不一置,索引无法使用
【5.3】复合索引除最左列:符合索引多列时,只有最左列能用到索引
【5.4】CBO基于代价:如果mysql估计使用索引比全表扫描更慢,就会使用全表扫(一般是因为返回的结果集记录太多)
【5.5】用or 分隔开的条件:如果or前的列有索引,而后面的列没有索引,那么设计的索引都不会被用到。因为or后面的条件列中没有索引,那么后面的查询肯定要全表扫了,存在全表扫的情况下,就没有必要多一次索引扫描增加I/O访问了。如果前后均有索引(那就和in一样了),那么就可以走索引。