解析器
1.json解析器
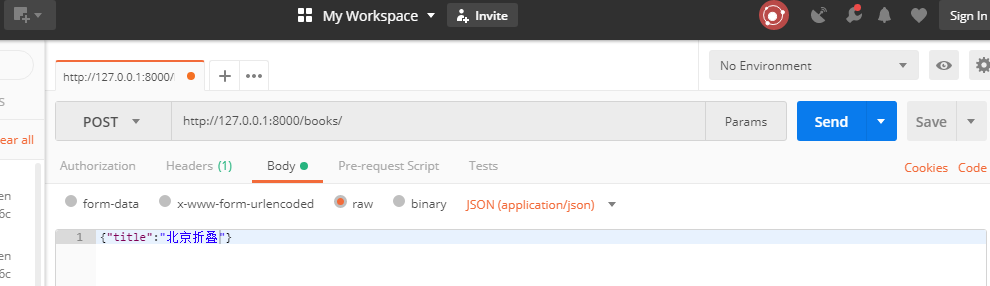
发一个json格式的post请求。
后台打印: request_data---> {'title': '北京折叠'} request.POST---> <QueryDict: {}>
2.urlencode解析器

request_data---> <QueryDict: {'title': ['北京'], 'price': ['122']}>
request.POST---> <QueryDict: {'title': ['北京'], 'price': ['122']}>
rest-framework默认支持的有3种解析器,json,form,文件上传。而Django原生只支持form的解析,不支持json的解析。
源码:
JSON解析器类:
class JSONParser(BaseParser): """ Parses JSON-serialized data. """ media_type = 'application/json' renderer_class = renderers.JSONRenderer strict = api_settings.STRICT_JSON def parse(self, stream, media_type=None, parser_context=None): """ Parses the incoming bytestream as JSON and returns the resulting data. """ parser_context = parser_context or {} encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) try: decoded_stream = codecs.getreader(encoding)(stream) parse_constant = json.strict_constant if self.strict else None return json.load(decoded_stream, parse_constant=parse_constant) except ValueError as exc: raise ParseError('JSON parse error - %s' % six.text_type(exc))
form解析器类:
class FormParser(BaseParser): """ Parser for form data. """ media_type = 'application/x-www-form-urlencoded' def parse(self, stream, media_type=None, parser_context=None): """ Parses the incoming bytestream as a URL encoded form, and returns the resulting QueryDict. """ parser_context = parser_context or {} encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) data = QueryDict(stream.read(), encoding=encoding) return data
文件上传类:
class MultiPartParser(BaseParser): """ Parser for multipart form data, which may include file data. """ media_type = 'multipart/form-data' def parse(self, stream, media_type=None, parser_context=None): """ Parses the incoming bytestream as a multipart encoded form, and returns a DataAndFiles object. `.data` will be a `QueryDict` containing all the form parameters. `.files` will be a `QueryDict` containing all the form files. """ parser_context = parser_context or {} request = parser_context['request'] encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) meta = request.META.copy() meta['CONTENT_TYPE'] = media_type upload_handlers = request.upload_handlers try: parser = DjangoMultiPartParser(meta, stream, upload_handlers, encoding) data, files = parser.parse() return DataAndFiles(data, files) except MultiPartParserError as exc: raise ParseError('Multipart form parse error - %s' % six.text_type(exc))
URL控制
1.因为每次url都需要写下面的2条线,导致代码冗余。
# url(r'authors/$', views.AuthorModelView.as_view({"get":"list","post":"create"}),name="authors"), # url(r'authors/(?P<pk>d+)/$', views.AuthorModelView.as_view({"get":"retrieve","put":"update","delete":"destroy"}),name="authordetail"),
2.使用rest-framework提供的:
from django.conf.urls import url,include from app01 import views from rest_framework import routers routers=routers.DefaultRouter() routers.register("authors",views.AuthorModelView)
url中需要加这一句即可:
url(r'',include(routers.urls)),
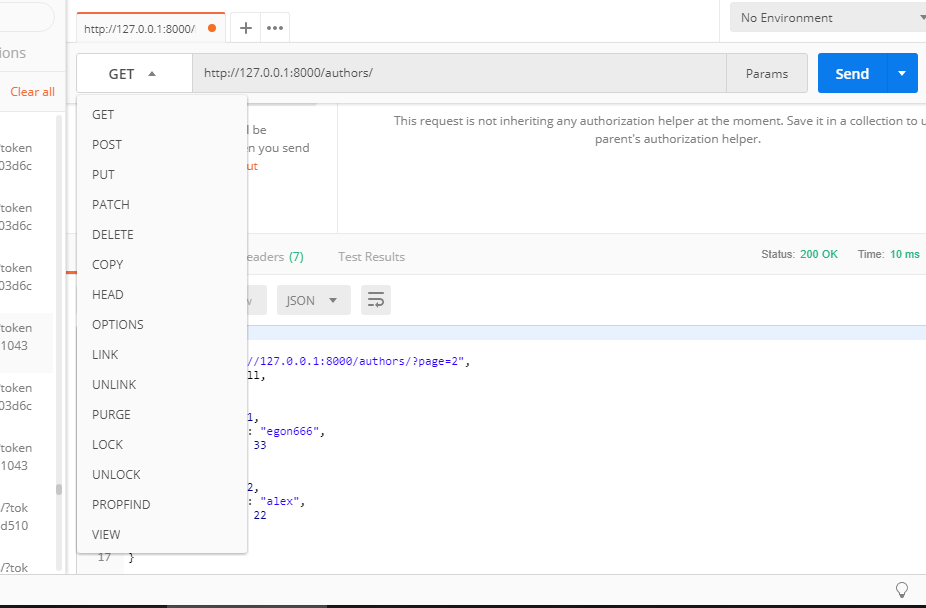
以后每一个表,注册一下即可,前面的是url的前缀,后面是对应的视图类。
测试结果以及自动生成的url路径如下图:(可以直接.json取到结果)

生成的URL:

分页
1.基本分页器:
from rest_framework.pagination import PageNumberPagination
#自己写一个继承分页器,然后自己设置 class MyPageNumberPagination(PageNumberPagination): page_size = 2 #每个页面显示多少数据 page_query_param = "page" #?page 的名字,默认"page",可以改其他 page_size_query_param = "size" #临时的一个分页数目,虽然最多2条,但是可以临时扩大每页显示的数据数量 max_page_size = 3 #虽然临时的可以调,但不能无限大,做一个最大临时限制。 class BookView(APIView): # authentication_classes = [TokenAuth] def get(self,request): print(request.user) #token_obj.user.name print(request.auth) #token_obj.token book_list=Book.objects.all() #加入分页 pnp=MyPageNumberPagination() #分页器实例对象 books_page=pnp.paginate_queryset(book_list,request,self) #传入数据 bs2=BookModelSerializers(books_page,many=True,context={'request': request}) #将分好的数据进行序列化并展示 return Response(bs2.data)
2.偏移分页器(很少用到):
from rest_framework.pagination import LimitOffsetPagination
和上面一模一样,只是加了一个offset的偏移参数。
3.对于高度封装的视图类怎么使用分页器:
from rest_framework import viewsets class AuthorModelView(viewsets.ModelViewSet): queryset=Author.objects.all() serializer_class=AuthorModelSerializers pagination_class = MyPageNumberPagination
因为这个作者的视图进行了高度的封装,显然重写list方法并且进行分页展示非常的麻烦,那么使用一个
pagination_class =你自己继承分页器并且定制好的分页器类即可完成分页。
4.全局配置分页数目:
settings中进行配置。
REST_FRAMEWORK={ # "DEFAULT_AUTHENTICATION_CLASSES":["app01.utils.TokenAuth",], # "DEFAULT_PERMISSION_CLASSES":["app01.utils.SVIPPermission",], "PAGE_SIZE":3, }
响应器
from rest_framework.response import Response
针对rest-frarmwork返回的数据进行各种操作,如果使用浏览器,那么响应器会渲染一个页面出来提供各种操作,如果使用postman,只返回一堆数据。
具体如下图:
postman:
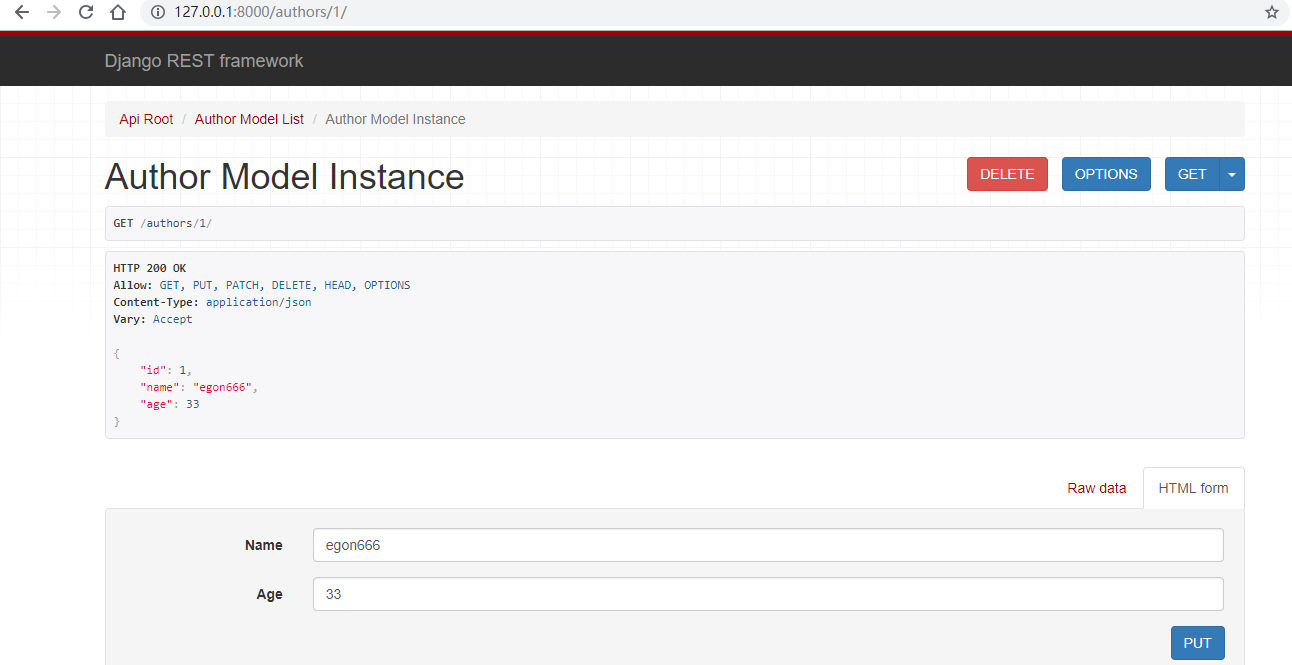
浏览器上:
这个页面可进行option,delete,put操作。
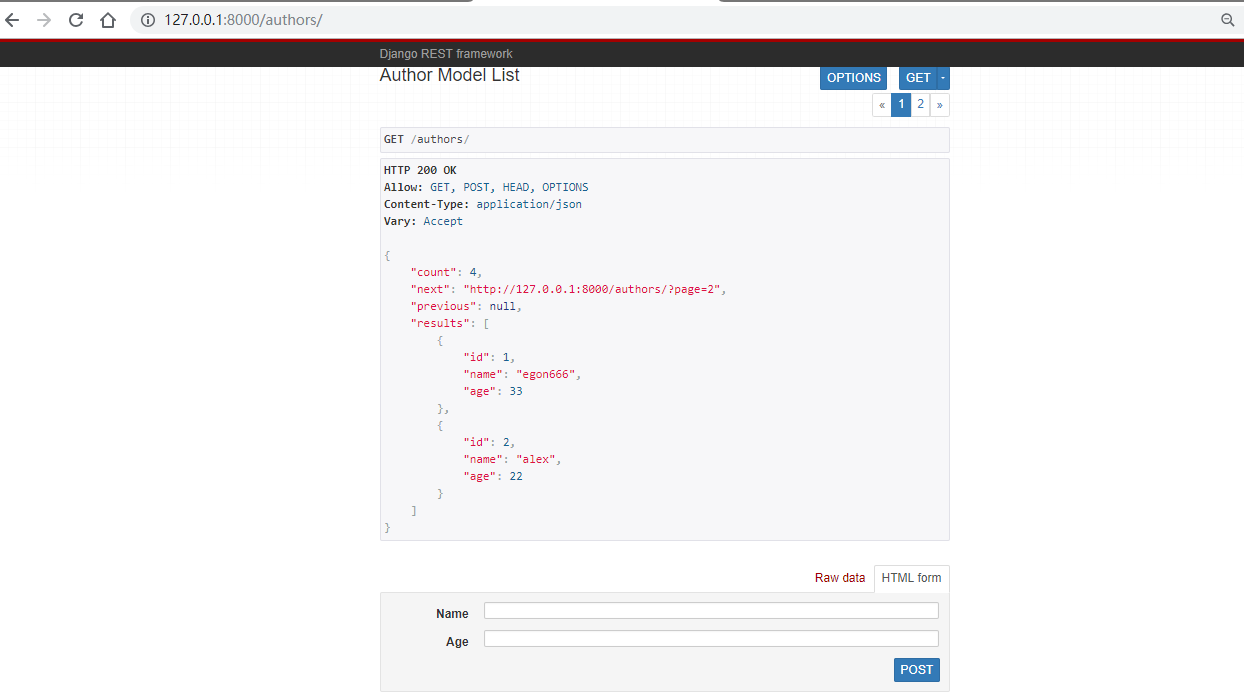
针对所有数据,下面可以进行get和post请求。
渲染器

这里可以使用Json的渲染器

也可以是这种页面形式的(用的少)
全局配置渲染器:

版本控制
1.先导入
from rest_framework.versioning import QueryParameterVersioning,URLPathVersioning
2.在APIView中
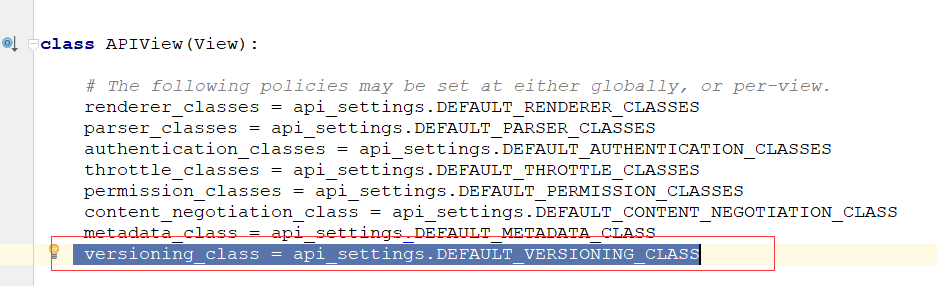
3.局部配置

4.全局配置
settings中配置:
REST_FRAMEWORK={ # "DEFAULT_AUTHENTICATION_CLASSES":["app01.utils.TokenAuth",], # "DEFAULT_PERMISSION_CLASSES":["app01.utils.SVIPPermission",], "PAGE_SIZE":1, # 配置全局渲染器(Json格式的,和那种页面形式的) # 'DEFAULT_RENDERER_CLASSES':['rest_framework.renderers.JSONRenderer',] 'DEFAULT_VERSION_CLASS':'rest_framework.versioning.QueryParameterVersioning',#使用哪种版本控制 'ALLOWED_VERSIONS':['v1','v2'], #允许的版本 'VERSION_PARAM':'version', #参数 'DEFAULT_VERSION':'v1', #默认版本 }
5.对于两种不同的配置要说的是。
(1)对于QueryParameterVersioning这种
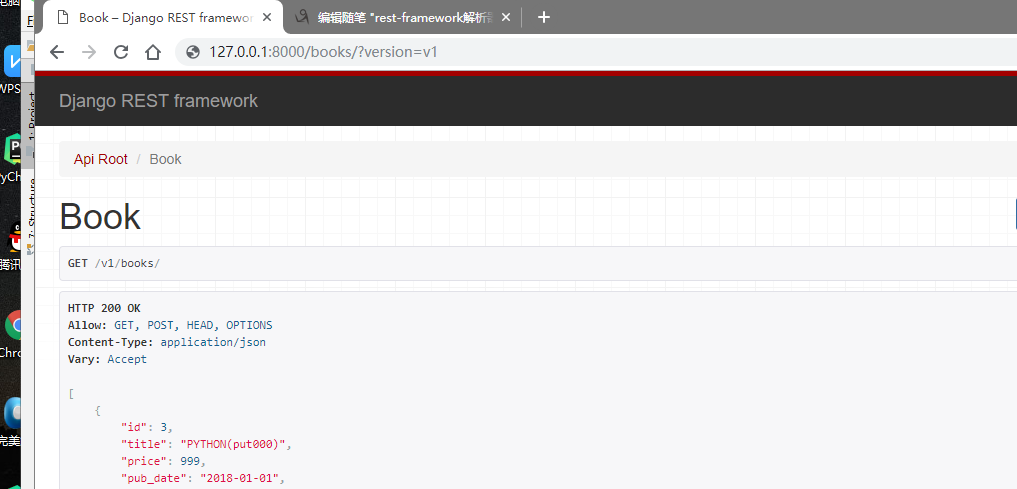
在url后缀加上版本。
后端通过request.version就可以拿到这个版本

(2)对于URLPathVersioning(推荐使用)
这个实在URL里面直接写。
首先要在url做一个配置。
url(r'^(?P<version>w+)/books/$', views.BookView.as_view(),name="books"),
get请求参数拿到这个version。
def get(self,request,*args,**kwargs): print("version",request.version) #print(request.user) #token_obj.user.name #print(request.auth) #token_obj.token book_list=Book.objects.all() #加入分页 pnp=MyPageNumberPagination() books_page=pnp.paginate_queryset(book_list,request,self) # bs=BookSerializers(book_list,many=True) bs2=BookModelSerializers(books_page,many=True,context={'request': request}) # return Response(bs.data) return Response(bs2.data)
前端页面的URL是
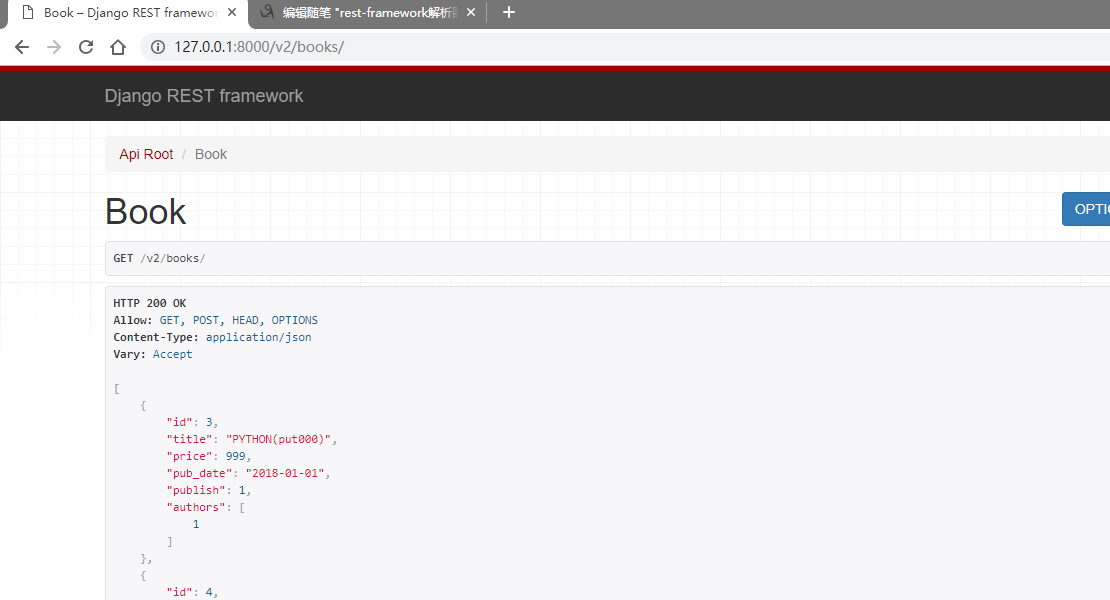
因为在全局做了允许配置,所以只能是v1,v2如果输入其他会报错。
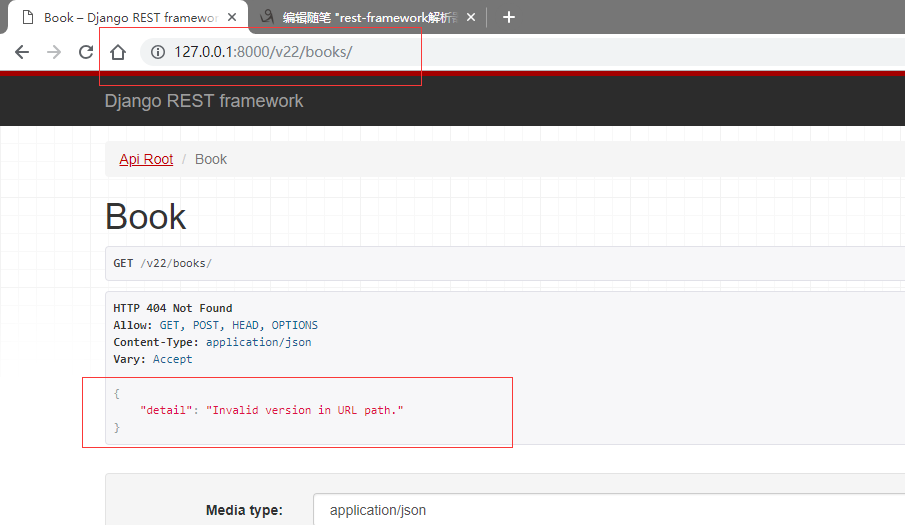
这就是版本控制。