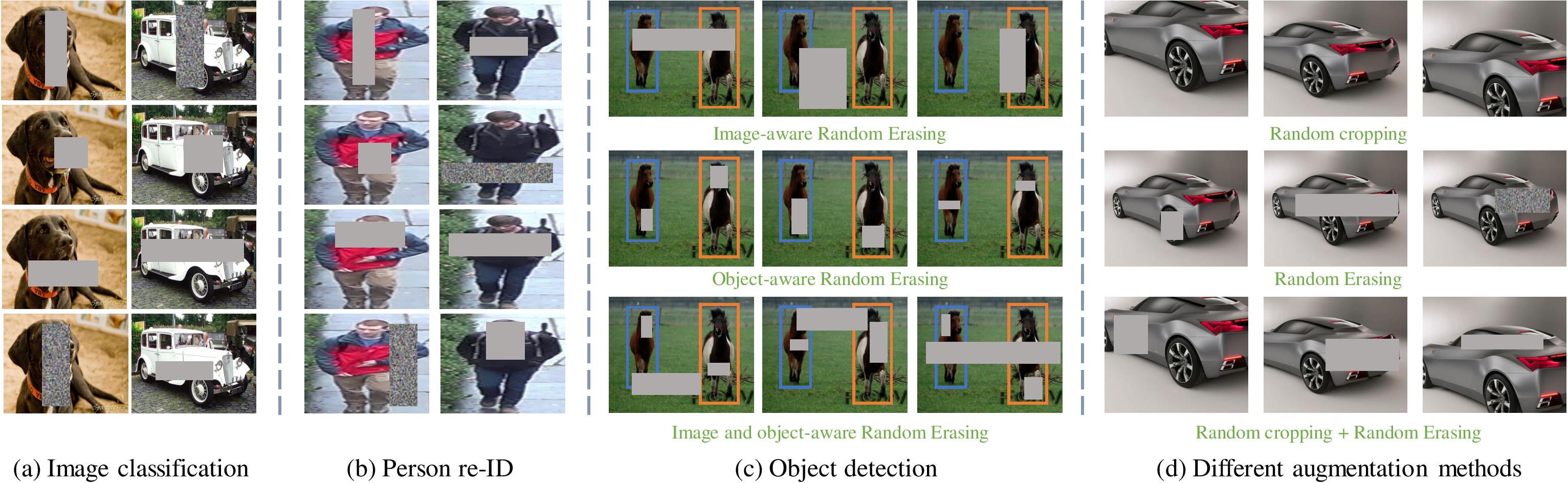
为了增强模型的泛化的性能,一般的手段有数据增强和正则化方法(如dropout,BN),而用于数据增强的一般方法有:随机裁剪、随机水平翻转、平移、旋转、增加噪音和生成网络方法等(前两个方法用的最多,也最有效),作者从CNNs输入的数据预处理出发,极端的情况下,如果训练模型的数据集很少有遮挡的样本(尽管放大再随机裁剪一定程度对应对遮挡的情形上有帮助),那么最终训练得到的模型也不能很好处理遮挡情景,为了使训练的模型更好的应对作为影响模型泛化能力的重要而关键的因素–遮挡,作者提出了很简单且实用的无参数数据增强方法—Random Erasing(也可以被视为add noise的一种)

Random Erasing Data Augmentation(REA)是一种随机擦除的数据增广方法。简单而言就是在图像中随机选择一个区域,打上噪声mask。这个mask可以是黑块、灰块也可以是随机正太噪声。。该方法被证明在多个CNN架构和不同领域中可以提升模型的性能和应对遮挡的鲁棒性,并且与随机裁剪、随机水平翻转(还有正则化方法)具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。
原理解释

(1) 图片I宽度(W),高(H),面积(S). 擦除区域面积占比(S_e in (S_l, S_h)), 擦除区域长宽比 (r_l in (r_1, r_2)) ;
(2) 随机取点((x_e), (y_e)), 随机生成擦除区域面积占比(S_e), 擦除区域长宽比 (r_l), 进而计算出mask的宽度(W_e), 高度(H_e) ;
(3) 判断mask是否超出图片边界, 如果越界返回第二步;
(4) 给像素赋随机值或者均值
(5) 返回新图片
效果
引用: