一.分析system_call中断处理过程
实验
下载最新menu,并在test.c中增加mkdir与mkdir-asm函数原型
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
vim test.c
增加下面的代码:
int Mkdir(int argc,char *argv[]){
if(mkdir(argv[1],S_IRWXU | S_IRWXG | S_IROTH | S_IXOTH) == 0)
printf("New dir successfully!
");
else
printf("New dir failed!
");
return 0;
}
int MkdirAsm(int argc,char *argv[]){
int intr;
mode_t mode = S_IRWXU | S_IRWXG | S_IROTH | S_IXOTH;
__asm__ __volatile__(
"int $0x80;
"
: "=a" (intr)
: "a"(39),"b"(argv[1]),"c"(mode)
:"memory"
);
if(intr == 0)
printf("New dirasm successfully!
");
else
printf("New dirasm failed!
");
return 0;
}
有两点需要强调,这也是我实验过程中出现过问题,才改进之后的代码!
- 注意加头文件
#include <sys/stat.h> #include <sys/types.h> - mkdir系统调用的结果是创建一个目录,而MenuOS并没有ls这个命令,所以为了验证我们添加mkdir和mkdir-asm命令成功,必须在函数中添加相应的判断与输出的语句,所以与上次实验代码相比,这里多了if与else语句和printf语句。否则我们无法验证在MenuOS中命令是否执行成功。
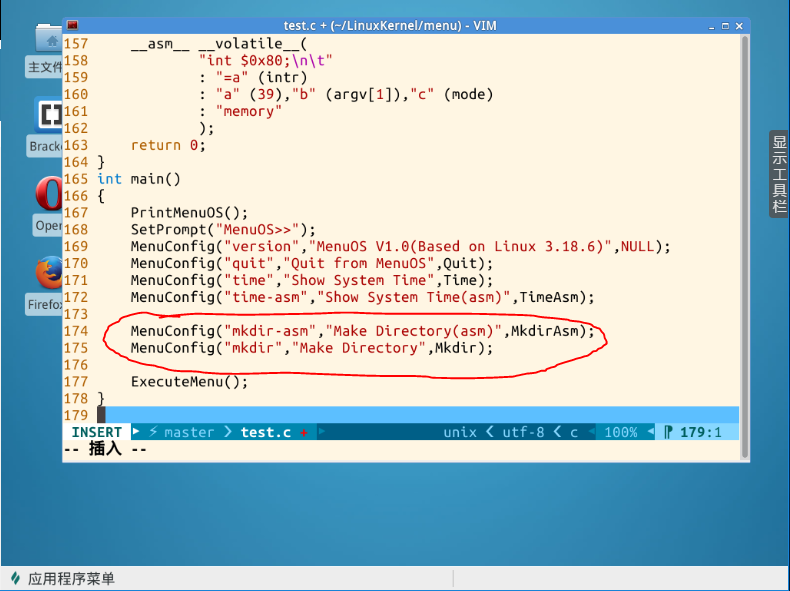
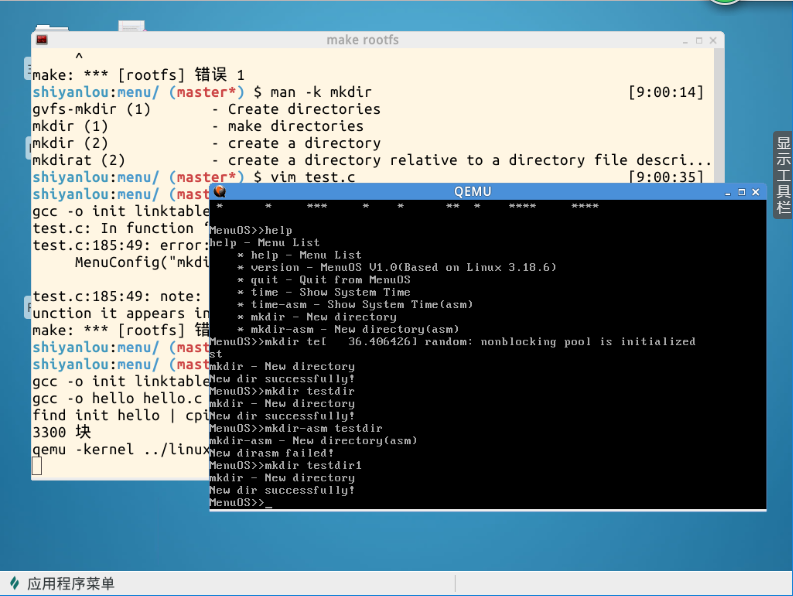
上面这个图我是先用mkdir创建了一个testdir目录,显示创建成功;随后我又用mkdir-asm又创建testdir这个目录,因为这个目录刚才已经用mkdir创建过,所以必然失败,这也变相说明上一步mkdir创建成功;随后我又用mkdir-asm创建了testdir1,显示创建成功。
下一步进行gdb调试:
cd ..
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S //启动并“冰冻”
gdb linux-3.18.6/vmlinux
target remote:1234 //连接到刚启动的虚拟机
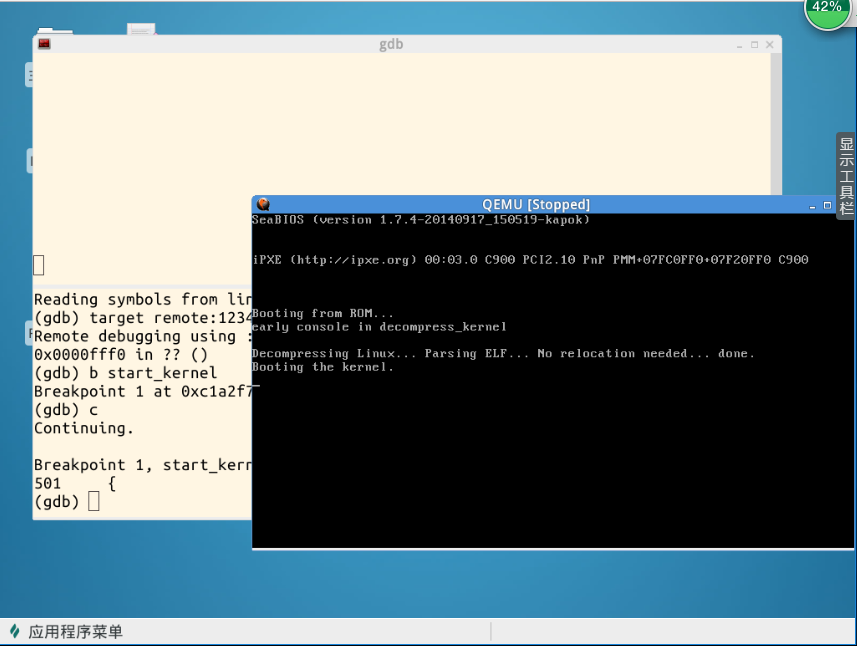
上图为b start_kernel之后的结果。
根据39号系统调用的内核函数sys_mkdir,执行b sys_mkdir:
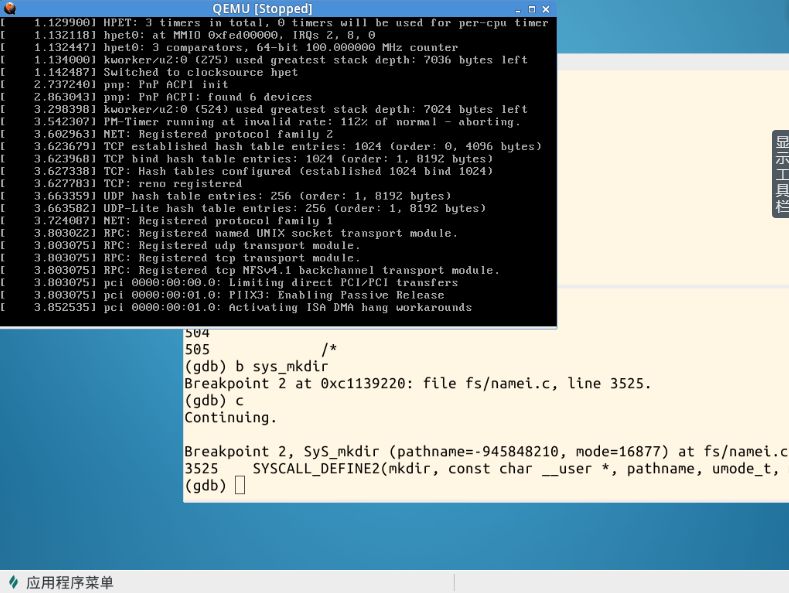
结果系统停在了启动的“半路上”。并不是像断sys_time那样。很显然,这说明在内核启动过程中,必然要调用sys_mkdir该系统调用(虽然我现在还不知道有哪些过程要调用它,但可以肯定的是一定有过程调用它!)。
还得出一条心得就是实验楼环境是真的不好用,每当我把当前界面换到启动的虚拟机,则必然造成死机。只有重新开始实验,这样造成的结果就是我还得重新下载menu,重新编写test.c。不仅如此,还无法实施对mkdi与mkdir-asm的跟踪,因为一切换到MenuOS就卡掉了,根本没法输入命令。
总结
system_call到iret之间的简化后伪代码:
ENTRY(system_call)
SAVE_ALL
syscall_call:
call *sys_call_table(,%eax,4)
movl %eax,PT_EAX(%eax) //保存返回值
syscall_exit:
testl $_TIF_ALLWORK_MASK,%ecx //current—>work
jne syscall_exit_work
restore_all:
RESTORE_INT_REGS
irq_return:
INTERRUPT_PETURN
ENDPROC(system_call)
syscall_exit_work:
testl $_TIF_WORK_SYSCALLEXIT,%ecx
jz work_pending
END(syscall_exit_work)
work_pending:
testb $_TIF_NEED_RESCHED,%c1
jz work_notifysig
work_resched:
call schedule
jz restore_all
work_notifysig:
...
END(work_pending)
流程图:
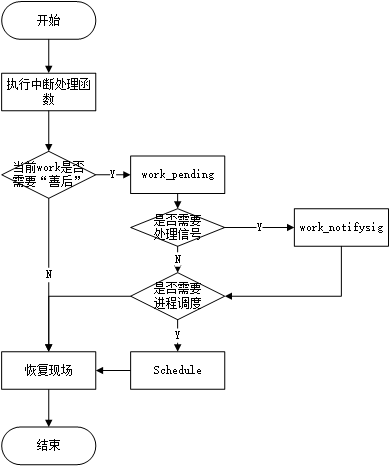
简化后的伪代码中只留下了一部分重要代码。比如对系统调用结束时要做的工作,这里只留下了两个判断,一个是是否有需要处理的信号,如果有,那就跳到相应的处理入口地址;第二个是是否需要进程调用,如果有那就转去处理进程调用,如果没有就结束。其实我们浏览没有简化的代码会发现,在这个过程中还有判断是否发生异常及异常处理等代码。
二.课本第九、十章内核同步
临界区的引出
共享资源之所以要防止并发访问,是因为如果多个执行线程同时访问和操作数据,就有可能发生各个线程之间相互覆盖共享数据的情况,造成被访问数据处于不一致状态。而访问和操作共享数据的代码段就被称为临界区。所以两个执行中的线程不可能处于同一个临界区中共同执行,一个临界区在执行完之前不可被打断。
同步和互斥
互斥指散布在不同进程之间的若干程序片断,当某个进程运行其中一个程序片段时,其它进程就不能运行它们之中的任一程序片段,只能等到该进程运行完这个程序片段后才可以运行。
同步是散布在不同进程之间的若干程序片断,它们的运行必须严格按照规定的某种先后次序来运行,这种先后次序依赖于要完成的特定的任务。
加锁
如果有一个线程对共享的数据加锁,则其他的线程就不能再访问该共享数据,必须等解锁之后才能去访问。简而言之,对同一共享数据,特定时间内只有一个线程可以进入与该共享数据对应的临界区。
死锁
- 若系统中存在一组进程(两个或多个进程),它们中的每一个进程都占用了某种资源而又都在等待其中另一个进程所占用的资源,这种等待永远不能结束,则说系统出现了“死锁”。或说这组进程处于“死锁”状态。
- 死锁产生的必要条件
- 互斥使用资源
- 占有并等待资源
- 不可抢夺资源
- 循环等待资源
- 解决死锁的办法就是打破上述一个或多个必要条件。
自旋锁
自旋锁最多只能被一个可执行线程持有,如果一个执行线程试图获得一个被已经持有的自旋锁,那么该线程就会一直进行忙循环——旋转——等待锁重新可用。要是锁未被争用,请求锁的执行线程便能立刻得到它们继续执行。在任意时间,自旋锁都可以防止多于一个的执行线程同时进入临界区。同一个锁可以用在多个位置。
信号量
- 计数信号量,比如读者-写者问题中的读者的数量。
- 二值信号量,比如读者-写者问题中对读者数量count的访问。
BLK:大内核锁
BLK是一个全局自旋锁,使用它主要是为了方便Linux最初的SMP过度到细粒度加锁机制。
- 持有BLK的任务仍然可以睡眠。
- BLK是一种递归锁。
- BLK只可用在进程上下文中。
- 新的用户不允许使用BLK。