4.1 遍历整个列表
我们经常需要遍历列表中的所有元素,对每个列表执行相同的操作。在进行重复性的工作的时候这个很有用,重复性工作。例如,在游戏中,可能需要将每个界面元素平移相同的距离;对于包含数字的列表,可能需要对每个元素执行相同的统计运算;在网站中,可能需要显示3文章中的每个标题。需要对列表中的每个元素都执行相同的操作时,可使用Python中的for循环。
假如我们有一个魔术师的名单,需要将其中每个魔术师的名字都打印出来。为此,我们可以分别获取名单中的每个名字,但这种做法会导致很多个问题。例如,如果名单过长,将包含大量重复的代码。另外,每当名单中的长度发生变化时,都必须修改代码。通过使用for循环,可让Python去处理这些问题。
下面使用for循环来打印魔术师名单中的所有名字:
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician)
运行结果:
alice
david
carolina
首先,我们像第三章那样定义了一个列表。接下来,我们定义了一个for循环;这行代码让Python从列表magicians中去除一个名字,并将其存储在变量
magician中。最后,我们让Python打印前面存储到变量magician中的名字。这样,对于列表中的每个名字,Python都将重复执行。我们可以这样解读这些代码
:对于列表magician中的每位魔术师,都将其名字打印出来。输出很简单,就是列表中所有的姓名:
4.1.1 深入地研究循环
循环这种概念很重要,尤其在操作重复性的问题的时候,使用自动循环会提高很多效率,而且它是让计算机自动完成重复工作的常见方式之一。例如,在前
面的magicians.py中使用的简单循环中,Python将首先读取其中的第一行代码:
for magician in magicians:
这行代码,让Python获取列表中magicians中的第一个值("alice"),并将其存储到变量magician中。接下来,Python读取下一行代码。
print(magician)
它让Python打印magician的值---依然是"alice"。鉴于该列表还包含其他值,Python返回循环的第一行:
for magician in magicians:
python获取列表中下一个名字——"david",并将其存储到变量magician中,在执行下面的代码:
print(magician)
Python再次打印变量magician的值"david"。接下来,Python再次执行整个循环,对列表中的最后一个值——"carolina"进行处理。至此,列表中没有其
它的值了,因此Python接着执行程序的下一行代码。在这个实例中,for循环后面没有其他的代码,因此程序就此结束。
刚开始使用循环时请牢记,对列表中的每个元素,都将执行循环制定的步骤,而不管列表包含多少元素。如果列表包含一百万个元素,Python就重复执行一
百万次,且通常速度非常快。
另外,编写for循环时,对于用于存储列表中每个值的临时变量,可指定任何名称。然而,选择描述单个列表元素的有意义的名称大有帮助。例如,对于小
猫列表,小狗列表和一般性列表,像下面这样编写for循环的第一行代码是不错的选择:
for dog in dogs:
for cat in cats:
for item in list_of_items:
这些命名约定有助于我们明白for循环中将对每个元素执行的操作。使用单数和复数式名称,可帮助我们判断代码处理的是单个列表元素还是整个列表。
4.1.2 在for循环中执行更多的操作
在for循环中,可对每个元素执行任何操作。
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician.title() + ", that was a greet trick!")
下面输出结果表明,对于列表中的每位魔术师,都打印了一条个性化消息:
Alice, that was a greet trick!
David, that was a greet trick!
Carolina, that was a greet trick!
在for循环中,想包含多少行代码都可以。在代码行for magician in magicians后面,每个缩进的代码行都是循环的一部分,且将针对列表中的每个值都
执行一次。因此,可对列表中能够的每个值执行任意次数的操作。
下面再添加一行代码,告诉每位魔术师,我们期待他的下一次表演:
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician.title() + ", that was a greet trick!")
print("I can't wait to see your next trick, " + magician.title() + ". " )
由于两条print语句都缩进了,因此它们都将针对列表中的每位魔术师执行一次。第二条print语句中的换行符" "在每次迭代结束后都插入一
个空行,从而整洁地将针对各位魔术师的消息编组:
Alice, that was a greet trick!
I can't wait to see your next trick, Alice.
David, that was a greet trick!
I can't wait to see your next trick, David.
Carolina, that was a greet trick!
I can't wait to see your next trick, Carolina!
在for循环中,想包含多少行代码都可以。实际上,我们会发现使用for循环对每个元素执行众多不同的操作很有用。
4.1.3 在for循环结束后执行一些操作
for循环结束后再怎么做呢?通常,我们需要提出总结性输出或接着执行程序必须完成的其他任务。
在for循环后面,没有缩进的代码都只执行一次,而不会重复执行。下面来打印一条向全体魔术师致谢的消息,感谢它们的精彩表演。想要在打印给各位
魔术师的消息后面打印一条给全体魔术师的致谢消息,需要将相应的代码放在for循环后面,且不缩进:
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician.title() + ", that was a great trick!")
print("I can't wait to see your next trick, " + magician.title() + ".
" )
print("Thank you,everyone. That was a great magic show!")
我们在前面看到了,开头两条print语句针对列表中每位魔术师重复执行。然而,由于第三条print语句没有缩进,因此只执行一次:
Alice, that was a great trick!
I can't wait to see your next trick, Alice.
David, that was a great trick!
I can't wait to see your next trick, David.
Carolina, that was a great trick!
I can't wait to see your next trick, Carolina.
Thank you,everyone. That was a great magic show!
使用for循环处理数据是一种对数据集执行整体操作的不错的方式。例如,你可能使用for循环来初始化游戏——遍历角色列表,将每个角色都显示到屏幕
上;再在循环后面添加一个不缩进的代码块,在屏幕上绘制所有角色后显示一个play Now按钮。
4.2 避免缩进错误
Python根据缩进来判断代码行与前一个代码行的关系。在前面的实例中,向各位魔术师显示消息的代码行是for循环的一部分,因为它们缩进了。Python通
过缩进让代码更易读;简单地说,它要求我们使用缩进让代码整洁而结构清晰。在较长的Python程序中,我们将看到缩进程度各不相同的代码块,这让我们队程
序的组织结构有大致的认识。
当我们开始编写必须正确缩进的代码时,需要注意一些常见的缩进错误。例如,有时候,程序员会将不需要缩进的代码块缩进,而对于必须缩进的代码块却
忘了缩进。通过查看这样的错误示例,有助于我们以后避开它们,以及在它们出现在程序中时进行修复。
4.2.1 忘记缩进
对于位于for语句后面且属于循环组成部分的代码行,一定要缩进。如果我们忘记缩进,Python会提醒:
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician.title() + ", that was a great trick!")
print语句应缩进却没有缩进。Python没有找到期望缩进的代码块时,会让我们知道代码行有问题。
File "/home/zhuzhu/title4/magicians.py", line 3
print(magician.title() + ", that was a great trick!")
^
IndentationError: expected an indented block
提示我们代码没有缩进,预期应该出现缩进的,通常,将紧跟在for语句后面的代码行缩进,可消除这种缩进错误。
4.2.2 忘记缩进额外的代码行
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician.title() + ", that was a great trick!")
print("I can't wait to see your next trick, " + magician.title() + ".
" )
magicians = ["alice","david","carolina"]
for magician in magicians:
print(magician.title() + ", that was a great trick!")
print("I can't wait to see your next trick, " + magician.title() + ".
" )
print("Thank you,everyone. That was a great magic show!")
由于第三条print代码行被缩进,它将针对列表中的每位魔术师执行一次
Alice, that was a great trick!
I can't wait to see your next trick, Alice.
Thank you,everyone. That was a great magic show!
David, that was a great trick!
I can't wait to see your next trick, David.
Thank you,everyone. That was a great magic show!
Carolina, that was a great trick!
I can't wait to see your next trick, Carolina.
Thank you,everyone. That was a great magic show!
这也是一个逻辑错误,与4.2.2节的错误类似。Python不知道你的本意,只要代码符合语法,它就会运行。如果原本只应执行一次的操作执行了多次,请确
定我们是否不应该缩进执行该操作的代码。
4.2.5 遗漏了冒号:
for语句在末尾冒号告诉Python,下一行是循环的第一行。
magicians = ["alice","david","carolina"]
for magician in magicians
print(magician.title() + ", that was a great trick!")
运行:
File "/home/zhuzhu/title4/magicians.py", line 2
for magician in magicians
^
SyntaxError: invalid syntax (语法无效)
如果我们不小心遗漏了冒号,将导致语法错误,运行会提示无效语法,因为Python不知道我们意欲何为。这种错误虽然易于消除,但并不那么容
易发现。程序员为找出这样的单字符错误,花费的时间多的令人惊讶。这样的错误之所以难以发现,是因为通常在我们的意料之外。
动手练一练
pizzas = ["New York Style","Chicago Style","California Style"]
for pizza in pizzas:
print("I like to eat " + pizza.title() + " .")
print("I can't wait to eat " + pizza.title() + " next time! ")
print("I like kinds of all style pizza !")
运行结果如下:
I like to eat New York Style .
I can't wait to eat New York Style next time!
I like to eat Chicago Style .
I can't wait to eat Chicago Style next time!
I like to eat California Style .
I can't wait to eat California Style next time!
I like kinds of all style pizza !
animals = ["lion","tiger","wolf","leopard"]
for animal in animals:
print(animal.title() + "s are good at hunting.")
print("Any of these animals like eating meat!")
首先定义了一个动物列表,使用for循环遍历列表中每一个动物,第一个print打印所以动物的一个共性,属于for循环的;第二个print在for循环外
面,当运行结束for循环后进行运行,属于总结性的语言,所以只会打印一次:
Lions are good at hunting.
Tigers are good at hunting.
Wolfs are good at hunting.
Leopards are good at hunting.
Any of these animals like eating meat!
4.3 创建数值列表
需要存储一组数字的原因有很多,例如,在游戏中,需要跟踪每个角色的位置,还可能需要跟踪玩家的几个最高得分。在数据可视化中,处理的几乎都是
数字(如温度、距离、人口数量、经度和纬度等等)组成的集合。
列表非常适合用于存储数字集合,而且Python提供了很多工具,可帮助我们处理数字列表。明白如何有效地使用这些工具后,即便包含数百万个元素,我们
编写的代码也能很好的运行。
4.3.1 使用函数range()
for value in range(1,6):
print(value)
这样,输出将从1开始,到5结束:
1
2
3
4
5
使用range()函数时,如果输出不符合预期,请尝试将指定的值加1或减1.
4.3.2 使用range()函数创建数字列表
numbers = list(range(1,6))
print(numbers)
结果如下:
[1, 2, 3, 4, 5]
使用函数range()时,还可指定步长。例如,下面的代码打印1~10内的奇数:
numbers = list(range(1,10,2))
print(numbers)
在这个实例中,函数range()从2开始数,然后不断地加2,直到达到或超过终值(10),因此输出的结果如下:
[1, 3, 5, 7, 9]
使用函数range()几乎能够创建任何需要的数字集,例如,如何创建一个列表,其中包含前10个整数(既1~10)的平方呢?在Python中,两个星号(**)表示
乘方运算。下面的代码演示了如何将前10个整数的平方加入到一个列表中:
squares = []
for num in range(1,11):
square = num**2
squares.append(square)
print(squares)
首先,我们创建了一个空列表;接下来,使用函数range()让Python遍历1~10的值。在循环中,计算当前值的平方,并将结果存储到变量square中,然后
将新计算的到的平方值附加到列表squares的末尾。最后,循环结束后,打印列表squares
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
创建更复杂的列表时,可使用上述两种方法中的任何一种。有时候,使用临时变量会让代码更易读;而在其他情况下,这样只会让代码无所谓地变长。我们
应该考虑的是,编写清晰易懂且能完成所需功能的代码;等到审核代码时,在考虑采用更高效的方法。
squares = [value**2 for value in range(1,11)]
print(squares)
要使用这种语法,首先指定一个描述性的列表名,如squares;然后指定一个左方括号,并定义一个表达式,用于生成你要存储得到列表中的值。在这个示
例中,表达式为value**2,它计算平方值。接下来,编写一个for循环,用于给表达式提供值,再加上右方括号。在这个实例中,for循环为for value in
range(1,11),它将值1~10提供给表达式value**2.请注意,这里的for语句末尾没有冒号。
结果与我们在前面看到的平方数列表相同:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
要创建自己的列表解析,需要经过一定的练习,但能够熟练地创建常规列表后,你会发现这样做是完全值得的。当你觉得编写三四行代码来生成列表有点繁
复时,就应该考虑创建列表解析了。
其实,我挺喜欢列表解析的,这种方法太省事了,又不用定义列表,只需要把语句写在括号里面,好省事,很方便,要多尝试使用这种方式,创建简短的数
列表表示方式。
动手试一试
4-3 数到20:使用一个for循环打印数字1~20(含);
4-4 一百万:创建一个列表,其中包含数字1~1000000,在使用一个for循环将这些数字打印出来(如果输出的时间太长,按Ctrl + C停止输出,或关闭
输出窗口)。
4-5 计算1~1000000的总和:创建一个列表,其中包含数字1~1000000,在使用min()函数和max()函数核实该列表确实是从1开始,从1000000结束的。
另外,对这个列表调用函数sum(),看看Python将一百万个数字相加需要多长时间。
4-6 奇数: 通过给函数range()指定第三个参数来创建一个列表,其中包含1~20的奇数;在使用一个for循环将这些数字都打印出来;
4-7 3的倍数: 创建一个列表,其中包含3~30内能被3整除的数字;在使用一个for循环将这个列表中的数字都打印出来;
4-8 立方: 将同一个数字乘三次成为立方。例如,在Python中,2的立方用2**3表示。请创建一个列表,其中包含前10个整数(即1~10)的立方,在使用
一个for循环将这些立方数都打印出来;
4-9立方解析:使用列表解析生成一个列表,其中包含前10个整数的立方。
分析:里面的试题主要考察我们for循环的使用,已经min()函数、max()函数和sum()函数等,要多尝试使用列表解析,因为我觉得这真是一个很好的方法,只需
一步就能产生我们需要的列表,要记住函数range()的差一性,list()函数是生成列表的。表达式的情况,对数字列表进行操作。
4-3:本题就是练习我们for循环的使用,还有range()函数的差一性
for num in range(1,21):
print(num)
4-4:本题还是锻炼我们for循环的使用情况,以及range()函数的差一性,但是想告诉我们,Python可以处理很大的数字,并不简单是书上很小的数
for num in range(1,1000001):
print(num)
运行的时候,遍历1~1000000还是花费了十几秒的时间,要记得差一性,比我们想要的数加一
4-5:本题是要使用list()函数创建列表,然后验证最大值,最小值,并对数字进行求和
numbers = list(range(1,1000001))
print(min(numbers))
print(max(numbers))
print(sum(numbers))
运行结果如下:
1
1000000
500000500000
python计算的速度挺快的,但是在生成列表的时候,还是会花费一点时间的,可以看出最小值确实是1,最大值确实是1000000
4-6:本题主要考察的是range()函数的步长问题,可以制定一个步长在使用的过程中
numbers = list(range(1,20,2))
print(numbers)
nums = [value for value in range(1,20,2)]
print(nums)
使用了两种方法创建列表,第一种方法是list()函数,第二种是列表解析,当然,如果没有表达式的话,函数list()方法方便一点,如果有表达是的话,列表解
析就方便很多了,这本题中主要考察的是range()函数的步长,能够自定义步长值,另外要注意,我们要使用步长的时候,一定要定义range()函数的初始值,第
一个参数是起始值,第二个参数是结束值,第三个参数是步长值。
4-7:本题主要考察我们创建变形的列表,要使用表达式的情况,可以使用循环代码,也可以使用列表解析
numbers = []
#首先创建一个空列表用于存储生成的列表数字
for num in range(1,11):
number = num * 3
numbers.append(number)
print(numbers)
digits = [value * 3 for value in range(1,11)]
print(digits)
第一种方法,由于要生成一个列表,首先我们定义了一个空的列表,然后定义一个循环,把每次生成的数值添加到这个空列表的末尾,最后生成我们所需的列表
,第二种方法是使用列表解析,可以看出,我们只需要一条语句就生成了一个数字列表,只要我们知道了列表的表达式就可。
4-8:本题跟上一题相似,只是列表表达式的方式不一样而已,解决的思路都是一样的
numbers = []
#首先创建一个空列表用于存储生成的列表数字
for num in range(1,11):
number = num ** 3
numbers.append(number)
print(numbers)
digits = [value ** 3 for value in range(1,11)]
print(digits)
可以看出我们只是修改了一下列表的表达式而已,在解决问题的时候首先是思考如何去解决问题,想好了之后在编写代码,首先我们要生成一个列表,这个列表
是包含自然是1~10的立方,那么我们要先生成1~10的自然数,这时候就用到我们的range()函数了,然后把生成的数进行变化添加到一个列表中即可,只需要每
次生成之后就添加到新的列表中即可。
4.4 使用列表的一部分
在第三章中,我们学习了如何访问单个列表元素。在本章中,我们一直在学习如何处理列表所有的元素。我们还可以处理列表的部分元素——Python称之
为切片。
4.4.1 切片
要创建切片,可指定要使用的第一个元素和最后一个元素的索引。与函数range()一样,Python在到达我们指定的第二个索引前面的元素后停止。要输出列
表中的前三个元素,需要制定索引0~3,这将输出分别为0、1和2的元素。
下面的示例处理的是一个运动队员列表:
players.py
players = ["charles","martina",'michael','florence','eli']
print(players[0:3])
代码打印列表的一个切片,其中只包含前三名队员。输出的也是一个列表,其中包含前三名队员:
['charles', 'martina', 'michael']
我们可以生成列表的任何子集,例如,如果我们要提取列表的第2~4个元素,可将起始索引制定为1,并将终止索引制定为4:
players = ["charles","martina",'michael','florence','eli']
print(players[1:4])
这一次,切片始于"martina",终于"florence":
['martina', 'michael', 'florence']
如果没有制定第一个索引,Python将自动从列表开头开始:
players = ["charles","martina",'michael','florence','eli']
print(players[:4])
由于没有制定起始索引,Python从列表开头开始提取:
['charles', 'martina', 'michael', 'florence']
要让切片终止于列表末尾,也可使用类似的语法。例如,如果要提取从第3个元素到列表末尾所有元素,可将起始索引制定为2,并省略终止索引:
players = ["charles","martina",'michael','florence','eli']
print(players[2:])
Python将返回从第3个元素到末尾的所有元素:
['michael', 'florence', 'eli']
无论列表多长,这种语法都能够让我们输出从特定位置到列表末尾的所有元素。本书前面说过,负数索引返回离列表末尾相应距离的元素,因此我们可以
输出列表末尾的任何切片。例如,如果我们要输出名单上的最后三名队员,可使用切片players[-3:]
players = ["charles","martina",'michael','florence','eli']
print(players[-3:])
上述代码打印最后三名队员的名字,即便队员名单的长度发生变化,也依然如此。
4.4.2 遍历切片
如果要遍历列表的部分元素,可在for循环中使用切片。在下面的实例中,我们遍历前三名队员,并打印它们的名字:
players = ["charles","martina",'michael','florence','eli']
#thired_players = players[:3]
#print(thired_players
print("Here are the first three players on my team:")
for player in players[0:3]:
print(player)
代码没有遍历整个队员列表,而只遍历前三名队员:
Here are the first three players on my team:
charles
martina
michael
在很多情况下,切片都很有用。例如,编写游戏时,我们可以在玩家退出游戏时将其最终得分加入到一个列表中。然后,为获取该玩家的三个最高得分,我
们可以将该列表按降序排列,在创建一个只包含前三个得分的切片。处理数据时,可使用切片来进行批量处理;编写Web应用程序时,可使用切片来分页显示信
息,并在每页显示数量合适的信息。
切片的功能确实很好用,在我们要求一个列表前三个,后三个的时候很好用,在使用切片的时候可能会使用sorted()函数对切片进行处理,这些都是需要注
意的,切片,原列表的一部分,切片的用途,当我们需要使用原切片的一部分的时候我们就会用到切片的功能。
4.4.3 复制列表
我们经常需要根据既有列表创建全新列表。下面来介绍列表复制的工作原理,以及复制列表可提供极大帮助的一种情形。
要复制列表,可创建一个包含整个列表的切片,方法是同时省略起始索引和终止索引([:])。这让Python创建一个始于第一个元素,终止于最后一个元素的
切片,即复制整个列表。
假如,假设有一个列表,其中包含我们最喜欢的四种食品,而我们还想创建另一个列表,在其中包含一位朋友喜欢的所有食品。不过,我们喜欢的食品,这
位朋友都喜欢,因此我们可以通过复制来创建这个列表:
foods.py
my_foods = ["pizza",'noodle','falafel']
friend_foods = my_foods[:]
print("My favorite foods are: ")
print(my_foods)
print("
My friend's favorite foods are: ")
print(friend_foods)
我们首先创建了一个名为my_foods的列表,然后创建了一个friend_foods的新列表。我们不制定任何索引的情况下从列表my_foods中提取一个切片,从而
创建了这个列表的副本,再将该副本存储到变量friend_foods中。打印每个列表后,我们发现它们包含的食品相同:
My favorite foods are:
['pizza', 'noodle', 'falafel']
My friend's favorite foods are:
['pizza', 'noodle', 'falafel']
为核实我们确实有两个列表,下面在每个列表中都添加一种食品,并核实每个列表都记录了相应任意喜欢的食品:
my_foods = ["pizza",'noodle','falafel']
friend_foods = my_foods[:]
my_foods.append("cannoli")
friend_foods.append("ice cream")
print("My favorite foods are: ")
print(my_foods)
print("
My friend's favorite foods are: ")
print(friend_foods)
与前一个示例一样,我们首先将my_foods的元素复制到新列表friend_foods中。接下来,在每个列表中都添加一种食品:在列表my_foods中添加"cannno"
,而在friend_foods中添加"ice cream"。最后,打印这两个列表,核实这两种食品包含在正确的列表中。
My favorite foods are:
['pizza', 'noodle', 'falafel', 'cannoli']
My friend's favorite foods are:
['pizza', 'noodle', 'falafel', 'ice cream']
输出结果表明,"cannoli"包含在你喜欢的食品列表中,而"ice cream"没有。"ice cream"包含在你朋友喜欢的食品列表中,而"cannoli"没有。倘若我们
只是简单地将my_foods赋给friend_foods,就不能得到两个列表。例如,下面演示了在不使用切片的情况下复制列表的情况:
my_foods = ["pizza",'noodle','falafel']
#这行不通
friend_foods = my_foods
my_foods.append("cannoli")
friend_foods.append("ice cream")
print("My favorite foods are: ")
print(my_foods)
print("
My friend's favorite foods are: ")
print(friend_foods)
这里将my_foods赋给friend_foods,而不是将my_foods的副本存储到friend_foods.这种语法实际上是让Python将新变量friend_foods关联到包含在
my_foods中的列表,因此这两个变量都指向同一个列表。鉴于此,当我们将"cannoli"添加到my_foods中时,它也将出现在friend_foodsz中;同样,虽然
"ice cream"好像只被加入到了friend_foods中,但它也将出现在这两个列表中。
输出表明,两个列表是相同的,这并非我们想要的结果:
My favorite foods are:
['pizza', 'noodle', 'falafel', 'cannoli', 'ice cream']
My friend's favorite foods are:
['pizza', 'noodle', 'falafel', 'cannoli', 'ice cream']
下面来分析这种情况,因为我也是不太懂这种情况,但是学了之后了解了这样的情况,Python中存储元素的原理,怎样开辟空间:
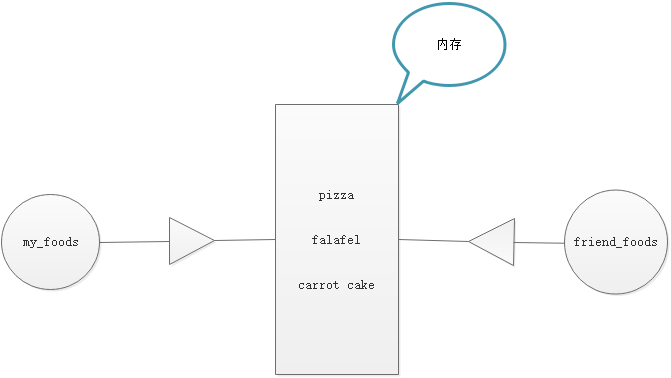
当采用赋值的方式生成friend_foods的时候,my_foods和friend_foods公用一个内存,在Python中没有开辟新的内存,上图所示,只是关联到了一起,所以当我们赋值的时候就变成下面的样子:

当我们向my_foods列表添加新的元素的时候,元素添加到原来的内存中;当我们向friend_foods中添加元素的时候,新的元素也是添加到了原来的内存列表中,所以采用赋值的时候,Python不会开辟新的内存,只是将两个变量关联到了一起,如上图所以,所以最后两者的结果还是一样的。
下面我们看使用切片的时候的情况:

由于采用的是切片,切片开辟了一个新的内存列表,用于存储friend_foods,当我们添加新的元素的时候如下图:

由于是两个不同的内存开辟的列表,当向my_foods添加新的元素时,只添加到my_foods的内存列表中;当向friend_foods添加新的元素时,只向friend_foods所属的内存列表中添加新的元素,所以输出结果是不一样的。
因而,赋值和切片在Python中的运行机制是不一样的,当我们赋值的时候,一定要注意这一点,以前没有怎么注意,以后要注意。尤其在复制操作的时候。
总结:当我们让一个参数等于另外一个参数的时候,直接a = b,这个时候是进行的赋值,当两个参数之间进行赋值的时候,是共用的一个内存,Python
里面是没有新开辟空间的。
动手试一试
4-10 切片:选择你在本章编写的一个程序,在末尾添加几行代码,以完成如下任务。
1、打印消息”The first three items in the list are:",在使用切片来打印列表的前三个元素;
2、打印消息"Three items from the middle of list are: ",在使用切片来打印列表中间的三个元素;
3、打印消息"The last three items in the list are: ",在使用切片来打印列表末尾三个元素。
4-11 你的比萨和我的比萨:在你为完成练习4-1而编写的程序中,创建比萨列表的副本,并将其存储到变量friend_pizzas中,在完成如下任务。
1、在原来的比萨列表中添加一种比萨;
2、在列表friend_pizzas中添加另一种比萨;
3、核实你有两个不同的列表。为此,打印消息"My favorite pizzas are:",再使用一个for循环来打印第二个列表。核实新增的比萨被添加到了正确的列表中。
4-10:本题主要考察列表切片的表示方法,如何进行列表切片的表示,尤其是L.[-1]表示最后一个元素,这种方法的使用很关键,考察最后几个元素的时候都会用到,列表切片的表示是从第几个元素到第几个元素,中间用冒号进行分割。
digits = [2,3,8,9,0,3,5,7]
print("The first three items in the list are: ")
print(digits[:3])
print("
Three items from the middle of the list are: ")
print(digits[2:5])
print("
The last three items in the list are: ")
print(digits[-3:])
运行结果如下:
The first three items in the list are:
[2, 3, 8]
Three items from the middle of the list are:
[8, 9, 0]
The last three items in the list are:
[3, 5, 7]
4-11 本题主要考察的是切片的使用,已经列表的复制的方法,列表复制要通过切片来完成,Python的工作原理决定的。
pizzas = ["New York Style","Chicago Style","California Style"]
friend_pizzas = pizzas[:]
pizzas.append("noodle")
friend_pizzas.append("rice")
print("My favorite pizzas are: ")
for pizza in pizzas:
print(pizza)
print(pizzas)
print("
My friend's favorite pizzas are: ")
for friend_pizza in friend_pizzas:
print(friend_pizza)
print(friend_pizzas)
运行结果:
My favorite pizzas are:
New York Style
Chicago Style
California Style
noodle
['New York Style', 'Chicago Style', 'California Style', 'noodle']
My friend's favorite pizzas are:
New York Style
Chicago Style
California Style
rice
['New York Style', 'Chicago Style', 'California Style', 'rice']
4.5 元祖
列表非常适合用于存储在程序运行期间可能变化的数据集。列表是可以修改的,这对处理网站的用户列表或游戏中的角色列表至关重要。然而,有时候我们需要创建一系列不可修改的元素,元祖可以满足这种需求。Python将不能修改的值称为不可变的,而不可变的列表被称为元祖。
4.5.1 定义元祖
元祖看起来犹如列表,但使用圆括号而不是方括号来标识。定义元祖后,就可以使用索引来访问其元素,就像访问列表元素一样。
例如,如果有一个大小不应改变的矩形,可将其长度和宽度存储在一个元祖中,从而确保它们是不能修改的:
dimensions.py
dimensions = (200,50)
print(dimensions[0])
print(dimensions[1])
我们首先定义了元祖dimensions,为此我们使用了圆括号而不是方括号。接下来,我们分别打印该元祖的各个元素,使用的语法与访问列表元素时使用的语法相同:
200
50
由定义我们知道元祖的元素是不可以修改的,下面我们来尝试修改元素dimensions中的一个元素,看看结果如何:
dimensions = (200,50)
dimensions[0] = 250
print(dimensions)
代码试图修改第一个元素的值,导致Python返回类型错误消息。由于试图修改元祖的操作是被禁止的,因此Python指出不能给元祖的元素赋值:
Traceback (most recent call last):
File "/home/zhuzhu/title4/dimensions.py", line 2, in <module>
dimensions[0] = 250
TypeError: 'tuple' object does not support item assignment
代码试图修改矩形的尺寸时,Python报告错误,这很好,因为这正是我们希望的。
4.5.2 遍历元祖中的所有值
像列表一样,也可以使用for循环来遍历元组中的所有值:
dimensions = (200,50)
for dimension in dimensions:
print(dimension)
就像遍历列表时一样,Python返回元组中所有的元素:
200
50
4.5.3 修改元组变量
虽然不能修改元组的元素,但可以给存储元组的变量赋值。因此,如果要修改前述矩形的尺寸,可重新定义整个元组:
dimensions = (200,50)
print("Original dimensions: ")
for dimension in dimensions:
print(dimension)
dimensions = (400,100)
print("
Modified dimensions: ")
for dimension in dimensions:
print(dimension)
我们首先定义了一个元组,并将其存储的尺寸打印了出来;接下来,将一个新元组存储到变量dimensions中;然后,打印新的尺寸。这次,Python不会报告任何错误,因为给元组变量赋值是合法的:
Original dimensions:
200
50
Modified dimensions:
400
100
相比于列表,元组是更简单的数据结构.如果需要存储的一组值在程序的整个生命周期内都不变,可使用元组。
动手试一试
4-13 自助餐: 有一家自助式餐厅,只提供五种简单的食品。请想出五种简单的食品,并将其存储在一个元祖中。
1、使用一个for循环将该餐馆提供的五种食品都打印出来;
2、尝试修改其中的一个元素,核实Python确实会拒绝我们这样做;
3、餐馆调整了菜单,替换了它提供的某中两种实物。请编写一个这样的代码块;给元组变量赋值,并使用一个for循环将新元组中的每个元素都打印出来。
分析:本题主要考察元组的性质及用法,我们知道,元组中的元素是不可以修改的,但是元组是可以重新赋值的,我们虽然不能修改元组中的元素,但是我们可以整体修改元组,元组其他的性质跟列表的性质都是一样的,就是不能对元组本身就行修改,比如添加,删除,赋值等。
cafeterias = ("rice","noodle","porridge","hamburger","pizza")
for cafeteria in cafeterias:
print(cafeteria)
cafeterias[-1] = "dami"
运行结果如下:
rice
noodle
porridge
hamburger
pizza
Traceback (most recent call last):
File "/home/zhuzhu/title4/Cafeterias.py", line 5, in <module>
cafeterias[-1] = "dami"
TypeError: 'tuple' object does not support item assignment
从运行结果可以看出,当我们试图修改元组的元素是,发生了错误,提示我们不能修改元组的元组值
cafeterias = ("rice","noodle","porridge","hamburger","pizza")
print("Original menu: ")
for cafeteria in cafeterias:
print(cafeteria)
#cafeterias[-1] = "dami"
cafeterias = ("pizza",'hamburger','rice','milk','Drumsticks')
print(" Modified menu: ")
for cafeteria in cafeterias:
print(cafeteria)
运行结果如下:
Original menu:
rice
noodle
porridge
hamburger
pizza
Modified menu:
pizza
hamburger
rice
milk
Drumsticks
从运行结果可以看出,虽然我们不能修改元组中元素的值,但我们可以整体重新给元组进行赋值,这样是允许的,因而我们可以对元组重新赋值,这是允许的,
也是合法的,系统不会报错。
4.6 设置代码格式
随着我们编写的程序越来越长,有必要了解一些代码格式设置的约定。请花时间让我们的代码进可能易于阅读;让代码易于阅读有助于我们掌握程序是做什
么的,也可以帮助他人理解我们编写的代码。
为确保所有人编写的代码的结构都大致一致,Python程序员都遵循一些格式设置约定。学会编写整洁的Python后,就能明白他人编写的Python代码的整体
结构——只要他们和你遵循相同的指南。要称为专业程序员,应从现在开始就遵循这些指南,以养成良好的习惯。
4.6.1 格式设置指南
若要提出Python语言修改建议,需要编写Python改进提案(Python Enhancement Proposal,PEP).PEP8是最古老的PEP之一,它向Python程序员提供了代
码格式设置指南。PEP8的篇幅很长,但大都与复杂的编码结构相关。
Python格式设置指南的编写者深知,代码被阅读的次数比编写的次数多。代码编写出来后,调试时你需要阅读它;给程序添加新功能时,需要花很长的时间
阅读代码;与其他程序员分享代码时,这些程序员也将阅读它们。
如果一定要在代码易于编写和易于阅读之间做出选择,Python程序员几乎总是选择后者。下面的指南可帮助我们从一开始就编写除清晰的代码。
4.6.2 缩进
PEP 8建议每级缩进都使用四个空格,这即可提高可读性,又留下了足够的多级缩进空间。
在字处理文档中,大家常常使用制表符而不是空格来缩进。对于字处理文档来说,这样做的效果很好,但混合使用制表符和空格会让Python解释器感到迷惑
。每款文本编辑器都提供了一种设置,可将输入的制表符转换为指定数量的空格。我们在编写代码时应该使用制表符键,但一定要对编辑器进行设置,使其在文
档中插入空格而不是制表符。
在程序中混合制表符和空格可能导致极难解决的问题。如果我们混合使用了制表符和空格,可将文件中所有的制表符转换为空格,大多数编辑器都提供了这
样的功能。
4.6.3 行长
很多Python程序员都建议每行不超过80字符。最初制定这样的指南时,在大多数计算机中,终端窗口每行只能容纳79字符;当前,计算机屏幕每行可容纳的
字符数多得多,为何还要使用79字符的标准行长呢?这里有别的原因。专业程序员通常会在同一个屏幕上打开多个文件,使用标准行长可以让我们在屏幕上并排
打开两三个文件时能同时看到各个文件的整行。PEP 8还建议注释的行长都不超过72字符,因为有些工具为大型项目自动生成文档时,会在每行注释开头添加格式
化字符。
PEP 8中有关行长的指南并非不可逾越的红线,有些小组将最大行长设置为99字符。在学习期间,我们不用过多考虑代码的行长,但别忘了,协作编写程序,
大家几乎都遵守PEP 8指南。在大多数编辑器中,都可设置一个视觉标志——通常是一条竖线,让你知道不能越过的界限在什么地方。
4.6.4 空行
要将程序不同部分分开,可使用空行。我们应该使用空行来组织程序文件,但也不能滥用;只要按本书的示例展示的那样做,就能掌握其中的平衡。例如,
如果我们有5行创建列表的代码,还有3行处理该列表的代码,那么用一个空行将这两部分隔开是合适的。然而,我们不应该使用三四个空行将它们隔开。
空行不会影响代码的运行,但会影响代码的可读性。Python解释器根据水平缩进情况来解读代码,但不关心垂直间距。
Original menu:
rice
noodle
porridge
hamburger
pizza
Modified menu:
pizza
hamburger
rice
milk
Drumsticks