CGAN - 条件GAN
原始GAN的缺点





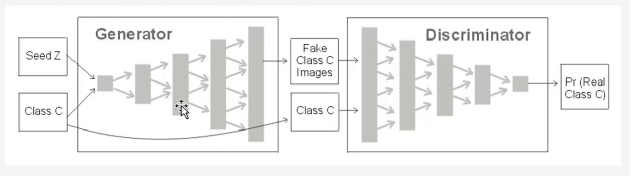
代码实现
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
gpu = tf.config.experimental.list_physical_devices(device_type='GPU')
tf.config.experimental.set_memory_growth(gpu[0], True)
import tensorflow.keras.datasets.mnist as mnist
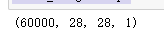
(train_image, train_label), (_, _) = mnist.load_data()


train_image = train_image / 127.5 - 1
train_image = np.expand_dims(train_image, -1)
train_image.shape
dataset = tf.data.Dataset.from_tensor_slices((train_image, train_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE

BATCH_SIZE = 256
image_count = train_image.shape[0]
noise_dim = 50
dataset = dataset.shuffle(image_count).batch(BATCH_SIZE)
def generator_model():
seed = layers.Input(shape=((noise_dim,))) # 输入 形状长度为50的向量
label = layers.Input(shape=(()))# 形状为空
# 输入维度: 因0-9一共10个字符所以长度为10 映射成长度为50 输入序列的长度为1
x = layers.Embedding(10, 50, input_length=1)(label)#嵌入层将正整数(下标)转换为具有固定大小的向量
x = layers.Flatten()(x)
x = layers.concatenate([seed, x])# 与输入的seed合并
x = layers.Dense(3*3*128, use_bias=False)(x)# 使用dense层转换成形状3*3通道128 的向量 不使用偏值
x = layers.Reshape((3, 3, 128))(x) # reshape成3*3*128
x = layers.BatchNormalization()(x)# 批标准化
x = layers.ReLU()(x) # 使用relu激活x
x = layers.Conv2DTranspose(64, (3, 3), strides=(2, 2), use_bias=False)(x)# 反卷积64个卷积核 卷积核大小(3*3) 跨度2
x = layers.BatchNormalization()(x)# 批标准化
x = layers.ReLU()(x) #使用relu激活x # 7*7
# 反卷积64个卷积核 卷积核大小(3*3) 跨度2 填充方式same 不适用偏值
x = layers.Conv2DTranspose(32, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x) # 14*14
x = layers.Conv2DTranspose(1, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.Activation('tanh')(x)
model = tf.keras.Model(inputs=[seed,label], outputs=x)
# 创建模型
return model
def discriminator_model():
image = tf.keras.Input(shape=((28,28,1)))
label = tf.keras.Input(shape=(()))
x = layers.Embedding(10, 28*28, input_length=1)(label)
x = layers.Reshape((28, 28, 1))(x)
x = layers.concatenate([image, x])
x = layers.Conv2D(32, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.5)(x)
x = layers.Conv2D(32*2, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.5)(x)
x = layers.Conv2D(32*4, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.5)(x)
x = layers.Flatten()(x)
x1 = layers.Dense(1)(x)
model = tf.keras.Model(inputs=[image, label], outputs=x1)
return model
generator = generator_model()
discriminator = discriminator_model()
binary_cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
category_cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = binary_cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = binary_cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
fake_loss = binary_cross_entropy(tf.ones_like(fake_output), fake_output)
return fake_loss
generator_optimizer = tf.keras.optimizers.Adam(1e-5)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-5)
@tf.function
def train_step(images, labels):
batchsize = labels.shape[0]
noise = tf.random.normal([batchsize, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator((noise, labels), training=True)
real_output = discriminator((images, labels), training=True)
fake_output = discriminator((generated_images, labels), training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
noise_dim = 50
num = 10
noise_seed = tf.random.normal([num, noise_dim])
cat_seed = np.random.randint(0, 10, size=(num, 1))
print(cat_seed.T)
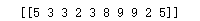
def generate_images(model, test_noise_input, test_cat_input, epoch):
print('Epoch:', epoch+1)
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model((test_noise_input, test_cat_input), training=False)
predictions = tf.squeeze(predictions)
fig = plt.figure(figsize=(10, 1))
for i in range(predictions.shape[0]):
plt.subplot(1, 10, i+1)
plt.imshow((predictions[i, :, :] + 1)/2)
plt.axis('off')
# plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch, label_batch in dataset:
train_step(image_batch, label_batch)
if epoch%10 == 0:
generate_images(generator, noise_seed, cat_seed, epoch)
generate_images(generator, noise_seed, cat_seed, epoch)
EPOCHS = 200
train(dataset, EPOCHS)



