增量式
概念:监测网站数据更新的情况,以便于爬取到最新更新出来的数据
- 实现核心:去重
- 实战中去重的方式:记录表
- 记录表需要记录的是爬取过的相关数据
- 爬取过的相关信息:url,标题,等唯一标识(我们使用每一部电影详情页的url作为标识)
- 只需要使用某一组数据,改组数据如果可以作为网站唯一标识信息即可,只要可以表示网站内容中唯一标识的数据我们统称为 数据指纹。
- 记录表需要记录的是爬取过的相关数据
- 去重的方式对应的记录表:
- python中的set集合(不可行)
- set集合无法持久化存储
- redis中的set集合就可以
- 因为可以持久化存储
- python中的set集合(不可行)
实现流程
创建工程
创建一个爬虫工程:scrapy startproject proName
进入工程创建一个基于CrawlSpider的爬虫文件
scrapy genspider -t crawl spiderName www.xxx.com
执行工程:scrapy crawl spiderName
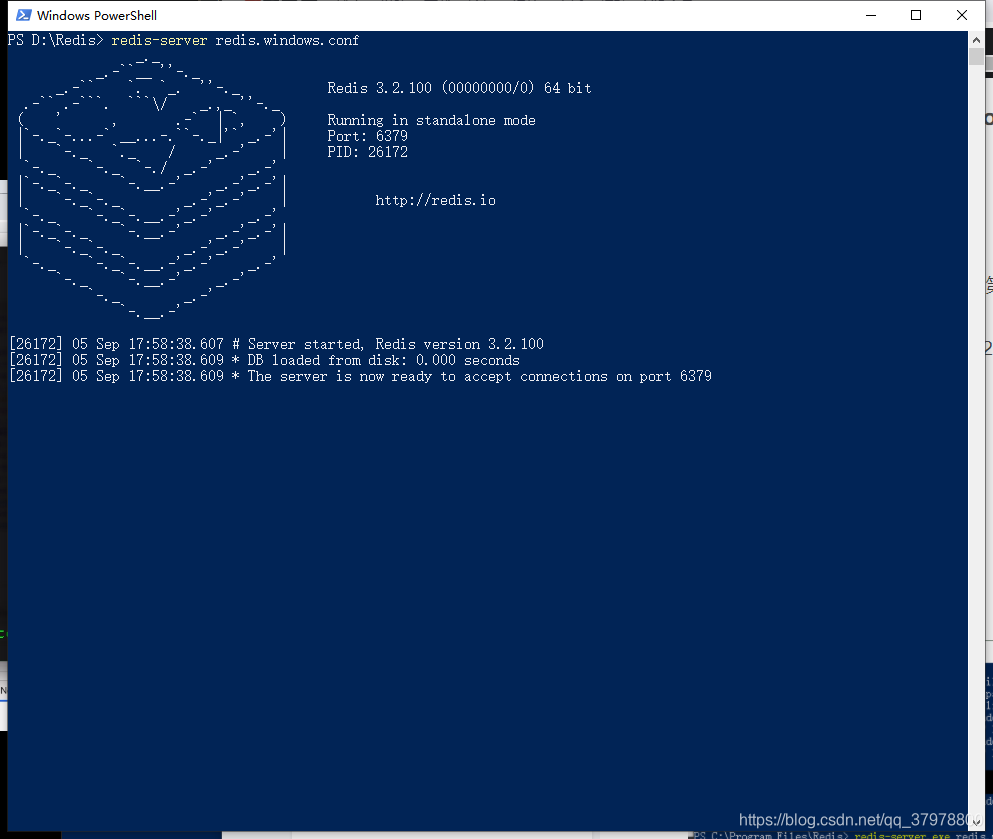
启动redis服务端
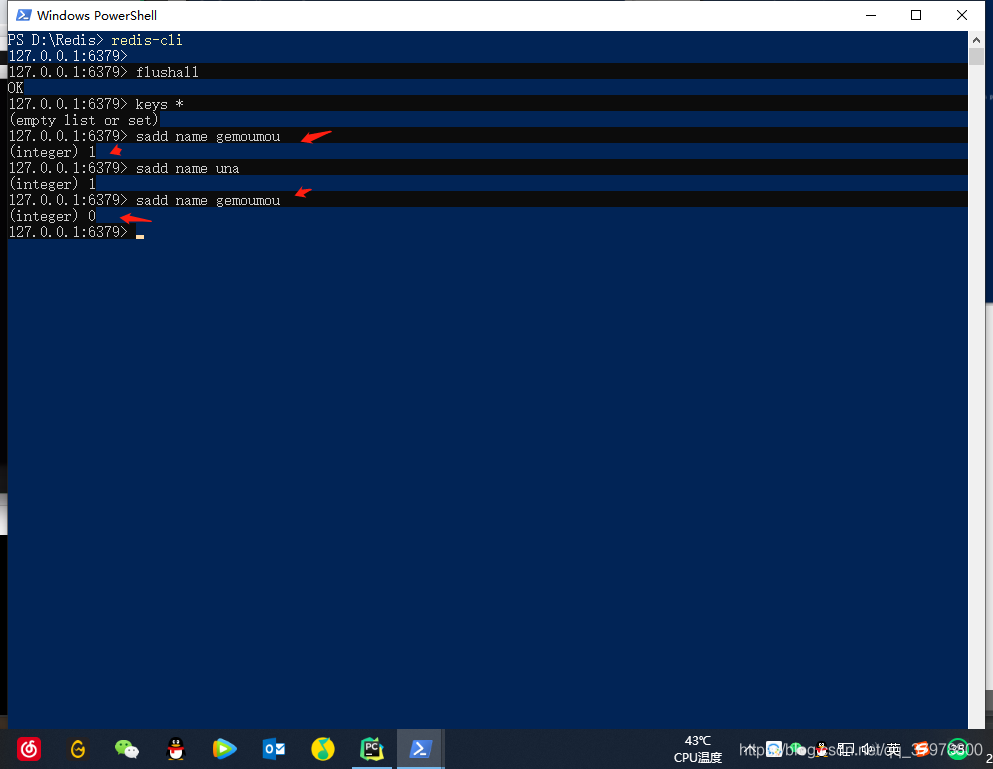
启动redis客户端
我们插入一个gemoumou set显示1 再次插入显示为0 说明无法插入
zls.py (爬虫源文件)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from zlsPro.items import ZlsproItem
class ZlsSpider(CrawlSpider):
name = 'zls'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567kan.com/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1.html']
conn = Redis(host="127.0.0.1",port=6379) # 链接redis服务器
rules = (
Rule(LinkExtractor(allow=r'page/d+.html'), callback='parse_item', follow=False),# 页码链接
)
def parse_item(self, response):
# 解析电影的名称+电影详情页的url
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
title = li.xpath('./div/a/@title').extract_first()
detail_url = "https://www.4567kan.com" + li.xpath('./div/a/@href').extract_first()
ex = self.conn.sadd("movie_urls",detail_url)
# ex ==1 插入成功 ex == 0 插入失败
if ex == 1: # 说明detail_url 表示的数据没有存在记录表中
# 爬取数据,发起请求
item = ZlsproItem()
item["title"] = title
print("有新数据更新,正在爬取新数据:",title)
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={"item":item})
else: # 存在记录表中
print("暂无数据更新")
def parse_detail(self,response):
# 解析电影简介
desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item = response.meta["item"]
item["desc"] = desc
print(desc)
yield item
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZlsproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
desc = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ZlsproPipeline:
def process_item(self, item, spider):
spider.conn.lpush('movie_data',item)
return item
settings.py
# Scrapy settings for zlsPro project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zlsPro'
SPIDER_MODULES = ['zlsPro.spiders']
NEWSPIDER_MODULE = 'zlsPro.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = "ERROR"
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zlsPro.middlewares.ZlsproSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'zlsPro.middlewares.ZlsproDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zlsPro.pipelines.ZlsproPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
结果
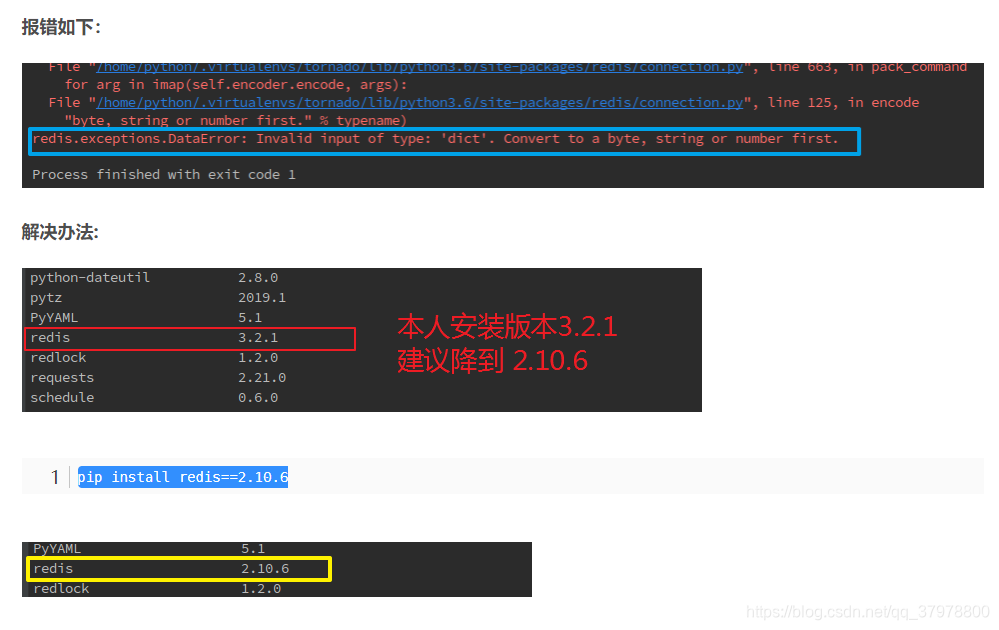

因数据存在所以暂无数据

因为网站中有4个电影无法打开
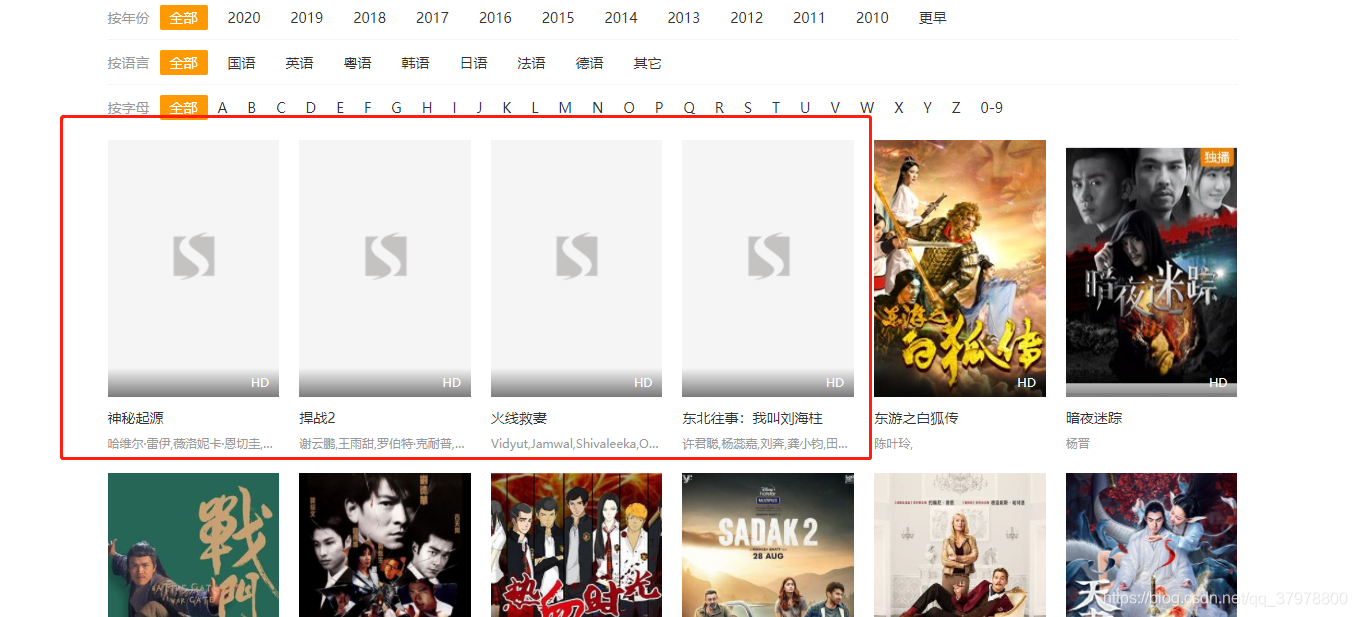
所以结果少了4个
