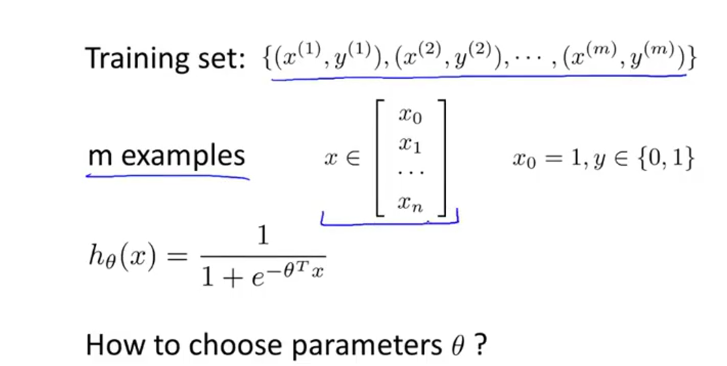
以上是之前我们所学习的sigmoid函数以及logistic函数,下面是我们代价函数的普遍定义形式: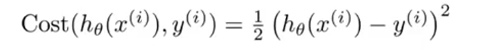
虽然普遍形式是有了,当然这个函数也仅仅是对第i个x才成立,如果想要得到连续的x的值则需要不断累加第i个的代价的值。如果想要上面的那种形式来作为代价函数,那么我们得到的代价函数不是凸函数因此不可能进行优化,于是引入了下面的这种形式来进行的,其具体形式是怎样的呢?我们来看看: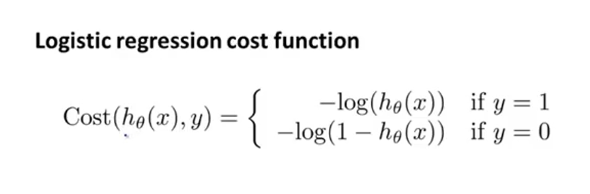
代价函数是使用实际的值和拟合的值进行做差。另一个需要提到的点是我们在做逻辑回归的时候,所使用的值都是已经标定好了的值,我们知道每一个点所对应的y的值,也知道没有一个点的x的特征值,因此我们仅需要做的是拟合出一个适合这个x/y的模型即可。下面我们把这个逻辑回归的损失函数写成一个连续的等式:
当然这是为什么?我们可以看看统计学当中的极大似然估计就知道了,但就目前而言我们并不需要详细了解这个过程。