Fully Associative Caches:
definition: A fully associative cache consists of a single set (i.e., E = C/B) that contains all of the cache lines.
只有一个set
匹配过程:

弊端和使用场景:
Because the cache circuitry must search for many matching tags in parallel, it is difficult and expensive to build an associative cache that is both large and fast. As a result, fully associative caches are only appropriate for small caches.
Issues with Writes:
前提(write hit):Suppose we write a word w that is already cached (a write hit). After the cache updates its copy of w, what does it do about updating the copy of w in the next lower level of the hierarchy?
两种处理方式:
直写:
The simplest approach, known as write-through, is to immediately write w’s cache block to the next lower level. While simple, write-through has the disadvantage of causing bus traffic with every write.
回写:
Another approach, known as write-back, defers the update as long as possible by writing the updated block to the next lower level only when it is evicted from the cache by the replacement algorithm. Because of locality, write-back can significantly reduce the amount of bus traffic, but it has the disadvantage of additional complexity. The cache must maintain an additional dirty bit for each cache line that indicates whether or not the cache block has been modified.
处理write misses的情况:
写分配:
One approach, known as writeallocate, loads the corresponding block from the next lower level into the cache and then updates the cache block. Write-allocate tries to exploit spatial locality of writes, but it has the disadvantage that every miss results in a block transfer from the next lower level to cache.
非写分配:
The alternative, known as no-write-allocate, bypasses the cache and writes the word directly to the next lower level.
总结:
Write through caches are typically no-write-allocate. Write-back caches are typically write-allocate.
CSAPP的建议:
To the programmer trying to write reasonably cache-friendly programs, we suggest adopting a mental model that assumes write-back write-allocate caches
建议的原因:
1 As a rule, caches at lower levels of the memory hierarchy are more likely to use write-back instead of write-through because of the larger transfer times.
2 Another reason for assuming a write-back write-allocate approach is that it is symmetric to the way reads are handled, in that write-back write-allocate tries to exploit locality.
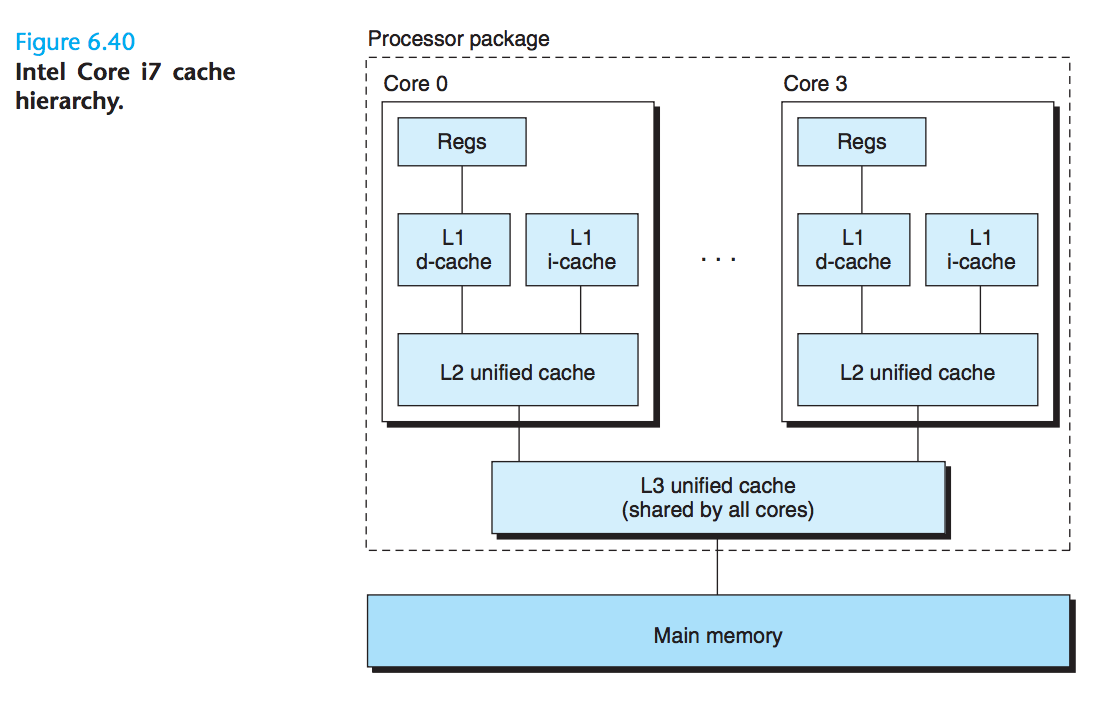
不仅能缓存数据,还能缓存指令:
A cache that holds instructions only is called an i-cache.
A cache that holds program data only is called a d-cache.
A cache that holds both instructions and data is known as a unified cache.
处理器将i-cache 和 d-cache 分开的原因:
With two separate caches, the processor can read an instruction word and a data word at the same time. I-caches are typically read-only, and thus simpler. The two caches are often optimized to different access patterns and can have different block sizes, associativities, and capacities. Also, having separate caches ensures that data accesses do not create conflict misses with instruction accesses, and vice versa, at the cost of a potential increase in capacity misses.
图示:
Performance Impact of Cache Parameters
一些Cache Performance的指标:
. Miss rate. The fraction of memory references during the execution of a program, or a part of a program, that miss. It is computed as #misses/#references.
. Hit rate. The fraction of memory references that hit. It is computed as 1 − miss rate.
. Hit time. The time to deliver a word in the cache to the CPU, including the time for set selection, line identification, and word selection.
.Hit time is on the order of several clock cycles for L1 caches.
. Miss penalty.Any additional time required because of a miss.
一些关于Cache的折中分析:
Impact of Cache Size
On the one hand, a larger cache will tend to increase the hit rate. On the other hand, it is always harder to make large memories run faster. As a result, larger caches tend to increase the hit time.
Impact of Block Size
On the one hand, larger blocks can help increase the hit rate by exploiting any spatial locality that might exist in a program. However, for a given cache size, larger blocks imply a smaller number of cache lines, which can hurt the hit rate in programs with more temporal locality than spatial locality. Larger blocks also have a negative impact on the miss penalty, since larger blocks cause larger transfer times. Modern systems usually compromise with cache blocks that contain 32 to 64 bytes.
Impact of Associativity(E)
The advantage of higher associativity (i.e., larger values of E) is that it decreases the vulnerability of the cache to thrashing due to conflict misses. However, higher associativity comes at a significant cost. Higher associativity is expensive to implement and hard to make fast. It requires more tag bits per line, additional LRU state bits per line, and additional control logic. Higher associativity can increase hit time, because of the increased complexity, and it can also increase the miss penalty because of the increased complexity of choosing a victim line.
问题的关键和工程应用:
The choice of associativity ultimately boils down to a trade-off between the hit time and the miss penalty. Traditionally, high-performance systems that pushed the clock rates would opt for smaller associativity for L1 caches (where the miss penalty is only a few cycles) and a higher degree of associativity for the lower levels, where the miss penalty is higher.
Impact of Write Strategy
直写:
Write-through caches are simpler to implement and can use a write buffer that works independently of the cache to update memory.
回写:
On the other hand, write-back caches result in fewer transfers, which allows more bandwidth to memory for I/O devices that perform DMA. Further, reducing the number of transfers becomes increasingly important as we move down the hierarchy and the transfer times increase.