一、背景与算法介绍
Transformer结构被广泛应用与自然语言处理中,并且在许多任务上都产生了当前最好的效果。为了达到进一步的效果,研究人员已经开始训练更大的Transformer模型。在某些报告的最大配置中,每层参数的数量超过了5亿(0.5B),而层的数量增加到了64层。Transformer模型也用于越来越长的序列中,在一个单独处理的样本中,序列的长度能达到11k,也就是包含11000个tokens每个序列,甚至还有更长的序列存在。这种大规模的长序列模型,虽然产生了较好的效果,但由于资源的限制,使得这一趋势正在打破NLP的研究发展。许多大型Transformer模型只能在大型工业研究实验室中进行实际训练,而这些并行训练的模型甚至不能在单个GPU上进行微调,因为它每训练一步,都需要多个加速器的硬件资源。
这些大规模的Transformer模型真的需要这么多资源,还是因为不高效导致的呢?参考一下下面的i计算:单层的参数在5亿个,需要内存约2GB;每一层的激活结果,为64K tokens, embedding size是1024,batch size是8,共计64k *1k *8=5亿个floats,又需要2GB的内存。如果只是这种单层的内存需求,我们使用单个加速器就很容易满足一个甚至长到64k的序列上。但是在多层上,内存的消耗就是惊人的:
- 由于每一层需要存储激活结果,所以N层网络消耗的内存是单层的N倍。
- Transformer每一层中间的前馈全连接网络的维度dff要比注意力层的dmodel大的多,所以消耗的内存更多。
- 序列长度为L的attention在时间和空间的复杂度都是O(L2),所以一个包含64K个tokens长的序列,都将会消耗巨大的内存。
本文引入的Reformer model将通过下面的技术解决这些问题:
- 可逆神经网络,将只需要存储一层的激活结果即可,N的因素消失了。
- 分块计算前馈全连接层,节省内存。
- 采用局部敏感哈希技术,近似计算注意力,将时空开销从O(L2)变为O(L)。
我们学习这些技术,并且发现跟标准Transformer相比几乎没什么影响。可逆神经网络确实改变了模型结构,但是通过实验发现,也几乎没有什么影响。最后,注意力中的局部敏感哈希是一个更大的变化,可以影响训练动态,这取决于所使用的并发哈希的数量。我们研究了这个参数,找到了既能高效使用,又能产生与全注意力相接近的效果。
我们在合成任务上进行了实验,一个是长度为64K的文本任务(enwik8),一个长度为12K的图像生成任务(imagenet-64generation)。在这两个实验中都表明,Reformer 与标准Transformer结果相当,但运行得更快,特别是在文本任务上,具有一个数量级的内存效率提升。
二、局部敏感哈希Attention
Transformer的标准注意力计算公式如下:

具体详细计算过程不再赘述,可参考Attention is all you need.
内存高效的注意力:
为了计算注意力机制的内存使用情况,我们集中看一下上述公式的注意力计算。先假设Q,K,V的shape都是[batch_size,length,dmodel],这里的主要关注点在QKT,其shape为[batch_size,length,length]。实验中,我们训练的序列长度为64K,这种情况下即便batch_size=1,QKT也是一个64k * 64K的矩阵,如果是32-bit floats的话,也将消耗内存16GB,这将阻挡Transformer在长序列上的使用。其实,QKT矩阵并不需要完全存储在内存中,可以每次分别计算一个qi,计算一次 softmax(qi*KT/√dk) *V 存储在内存中,然后在反向传播的时候计算相应的梯度信息。这种方式可能效率有点低下,但却是非常节省内存的。
Shared-QK Transformer:
在标准Transformer中,Q,K,V是由激活结果A分别通过三个线性层映射得到。但是这里引入了LSH attention,我们需要Q和K是相同的(备注:其实这里让Q和K相同并不是LSH必须,LSH只需要让Q、K变成单位向量即可,因为要在单位球面上进行相似查找,本文让Q和K一样只是为了方便批处理,加速计算),让Q和K通过相同的线性映射即可实现该目的。我们称这样的模型为shared-QK Transformer,实验结果表明共享Q、K并没有影响Transformer的表现效果。
LSH attention:
正如上面介绍的,我们每一次只计算一个qi和K的结果,但是我们需要和K中的每一个元素都计算吗?其实不是,我们只需要关心与qi相近的keys即可,K中的每一个元素从宏观上理解就是一个word。假设K的长度为64K,也就是有64K个tokens,我们只需要考虑其中的32或者64个最近的keys,那效率将大大提升。如何得到这最近的keys呢?利用Locality sensitive hashing就可以实现,它的基本思路就是距离相近的向量能够很大概率hash到一个桶内,而相距较远的向量hash到一个桶内的概率极低。
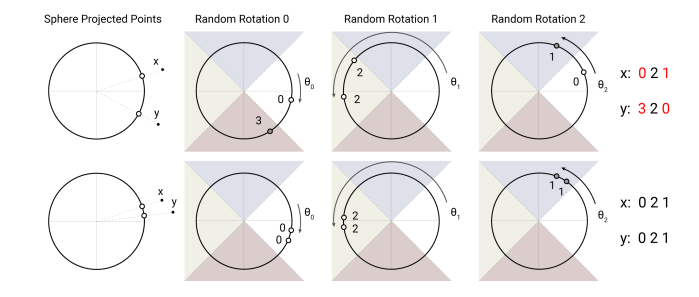
上图是LSH的一个简单示意图,在示意图的上部分,x和y不属于近邻,所以在三次随意旋转后,有两次投影都不一样;而在示意图的下部分,x和y相距很近,在三次的随意旋转后,三次都投影都一样,这就是LSH的基本原理。LSH原理的详细解释可以参考Locality Sensitive Hashing(局部敏感哈希)之cross-polytope LSH。
下面我们正式介绍LSH attention,首先重写标准的attention公式,对于位置i的单个query的一次计算如下:
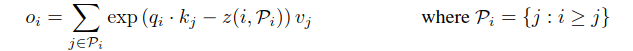
Pi或者:

Pi就是位置i的query需要关注的tokens集合,h代表hash函数,z表示分区函数(即softmax中的规格化项,相当于somax中的分母),为了简便,这里省去了√dk 。
对于一个长序列,为了便于统一批处理,修改计算公式如下:
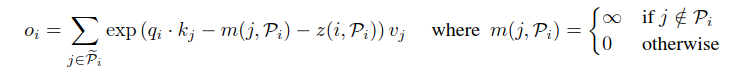
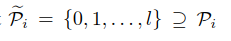
通过公式可以看到,如果不属于Pi的,都置为∞,相当于mask掉了,L是序列的长度。
Hash桶容易产生不均匀的分配,跨桶处理是比较困难的;另外,一个桶内的queries和keys数量不一定相等,事实上,有可能存在桶中只有queries而没有keys的情况。为了避免这种情况,首先通过kj=qj / ||qj|| 确保h(kj)=h(qj);其次,我们外部根据桶号、桶内部依据序列位置对queries进行排序,排序后定义一个置换i->si。排序后的注意力矩阵,同一个桶的将聚集在对角线附近,方便批量处理,提升速度,这点就跟上述说的Shared-QK一样,如下图c-d:
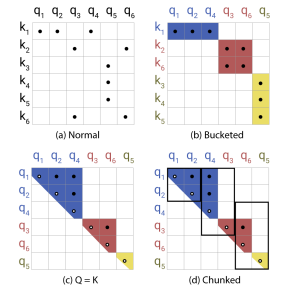
我们可以遵循一种批处理方法,其中m个连续查询的块(排序后)相互关联,后面的块往前看一个块。按照我们之前的符号,设置如下:
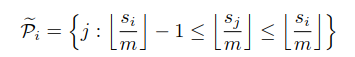
在实际中我们设置m=2L / nbuckets,L是序列的长度,每个桶的平均大小是L / nbuckets,所以我们前提假设一个桶成长为平均大小的2倍的概率是极低的。LSH attention的整个处理流程总结在下图中:

多轮LSH attention:
单个hash函数,总不可避免的会出现个别相近的items却被分到不同的桶里,多轮hash {h(1),h(2),...}可以减少这种情况的发生:
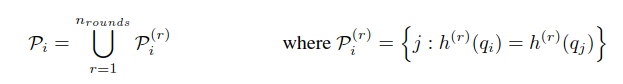
这里的多轮 LSH attention可以并行执行。
三、可逆Transformer
可逆残差网络:
可逆残差网络的主要思想是:在反向传播计算的时候,只使用模型参数就可以从下一层的激活结果中恢复任何给定层的激活结果,从而不用保存中间层的激活结果。标准的残差层从输入x到输出y的映射公式是:y=x+F(x),但是可逆层的输入输出都是成对的:(x1,x2)->(y1,y2),计算公式如下:

逆向计算公式如下:

可逆残差网络细节可以参考大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
可逆Transformer
我们将可逆残差网络的思想应用到Transformer中,在可逆块中结合了自注意力层和前馈网络层。结合上面的可逆残差公式,F函数变成了自注意力层,G函数变成了前馈网络层,注意的是每层的归一化处理放在了残差块里面。

可逆Transformer不需要在每一层中存储激活结果,在后面实验部分,我们对比使用了相同数量的参数,其表现与标准Transformer一样。
分块:
每一层Transformer中前馈网络所用的中间向量维度dff=4k甚至更高维度,依然非常占用内存;然而,一个序列中各个tokens在前馈网络层的计算是相互独立的,所以这部分计算可以拆分为c个组块:
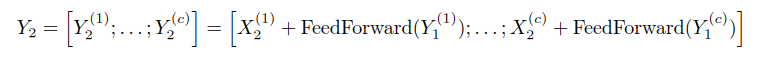
这一层通常是对所有位置并行操作批量完成的,但是一次只对一个块执行操作可以减少内存;可逆计算和反向传播也是分块进行的。对于字典比较大的模型,在计算 log-probabilities输出和loss的时候,也是一次计算一个组块。
四、实验分析
通过实验来展示上面介绍的技术效果,我们逐个分析上面的技术,从而能够更清晰的看出哪种组合能够影响实验结果。我们在 imagenet64和enwik8-64K 任务上进行实验,这里使用3层模型进行实验,以便与标准Transformer进行对比。参数设置,dmodel = 1024, dff = 4096, nheads = 8。
Shared-QK效果
共享QK通过设置kj=qj / ||qj||实现,并且阻止注意力放到自己token上面,除非没有上下文。从下图实验结果可以看出共享QK机制并没有比标准注意力机制效果差。
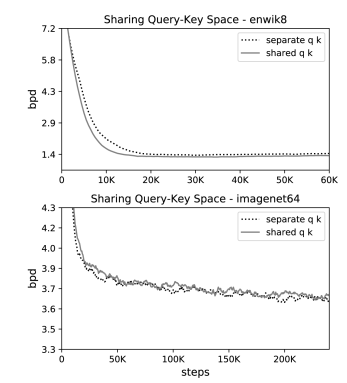
同时,在enwik8-64K实验上,似乎训练的速度更快一些。
可逆层的效果
这里还是用标准Transformer跟可逆网络层对比,二者所使用的参数基本一样,学习曲线图如下:

二者曲线基本一致,这说明可逆网络结构在节省内存的前提下,并没有损伤精度。
LSH attention in Transformer
相比全注意力机制,LSH注意力是一个近似的方法,从下面的实验图可以看出随着hash函数的增加,精确度也越来越高。
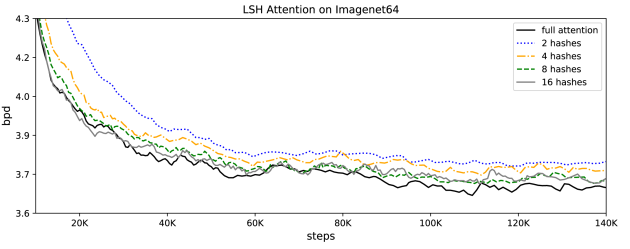
从图中可以看出,在nrounds = 8的时候,精确度已经跟全注意力机制相匹敌了;但是hash函数越多,计算代价就越高,所以这个超参数可以根据实际计算资源进行调整。
实验也对比了不同注意力机制的速度,如下图:
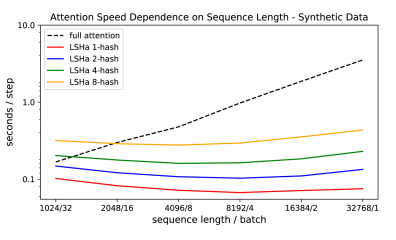
可以看出,随着序列长度的不断增加,标准注意力机制变得越来越慢,而LSH注意力机制基本变化不大,提速效果非常明显。
参考链接:
论文:https://arxiv.org/abs/2001.04451
github:https://github.com/google/trax/tree/master/trax/models/reformer
https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html