一、风险模型
1)在抽取样本的时候,最少需要有两期表现才可以,逾期超过15的label=1,逾期小于5天的label=0,因为逾期小于5天的有些可能是因为忘记的,意愿上并不愿意真正逾期。正负样本比例,不一定非得按自然分布来,逾期样本可以适当多一些,这样更能准确反映负样本的信息。
2)如何根据测试样本的score分数划线筛选客户呢?(前提:测试样本共计13400个,其中1142个逾期的,逾期率为8.5%)
- 根据score分进行排序,由高到底进行排序,高分的代表风险高。
- 取风险最高的top12%的用户,约1623个,逾期347个,占比26%左右,占整个逾期比例为30.3%。也就说根据测试样本结果,如果按风险最高的top12%划风险线,线为0.246,则可以筛选出30.3%的逾期客户。
- 取风险最高的top21%,约2811个,逾期501,占比17.8%,占整个逾期43.9%。
- 从2和3得出,取top12%的时候,里面筛选的逾期比例26%高于top21%的17.8%,所以按top12%筛选合适,因为如果按21%筛选了,虽然绝对逾期人数筛选出来更多了,但是相对逾期客户比例少了,也就是后面增加9%的用户性价比不如top12%的,冤枉了更多好人。
二、营销模型
1)抽取样本的时候,注册或者进件的可以混在一起作为正样本,比例可以按6:4,因为进件率基本就在40%左右。负样本就是营销无反应的那批客户。
2)建模的时候,由于电话或短信营销往往集中在几天,所以负样本就往往集中在一个月的几天,比如抽取9,10,11月作为样本,那负样本都只集中在这三个月的中的某几天,正样本还分布比较均匀一些。这种情况的样本,如果按时间排序分配test、valid、train,经实际测验发现,会造成test的ks值高于valid,valid的ks值会高于train,不符合常规结果。其原因就是负样本分布及其不均衡导致的,比如11月的负样本在1,2,3三天,这样造成test的样本集里面,负样本可能没有,或者占比一点点。解决办法就是打散了随机分配三种样本,比例还可以是6:2:2。
这个也是告诉我们,正负样本比例在train,valid,test三个集里面一定要一致切相对均衡。
三、营销联合建模案例一(BJ)
在进行营销建模的时候,正负样本各10万,PR曲线和KS曲线分别出现了如下奇怪的图形,此时KS=0.34,auc=0.71,top35recall=0.51:
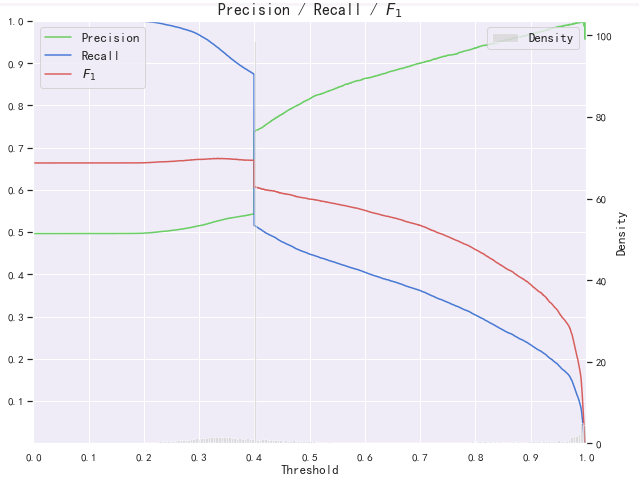
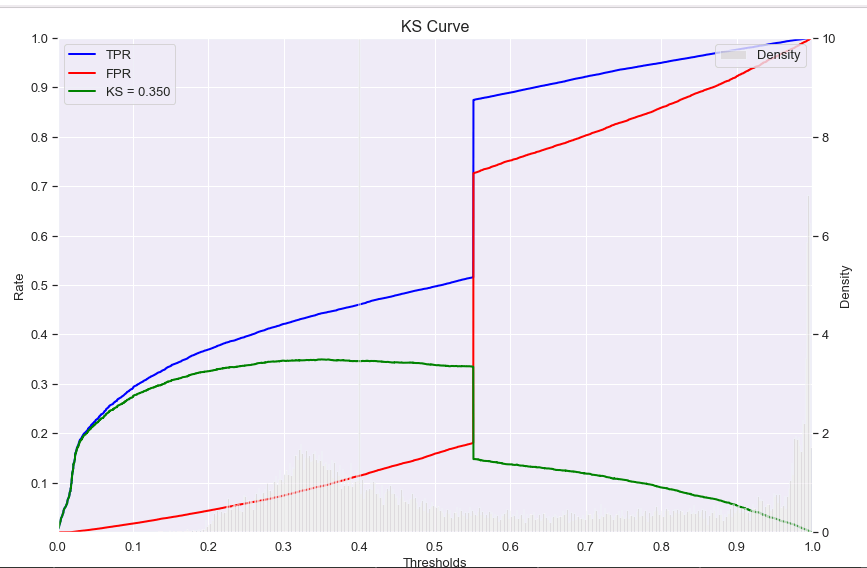
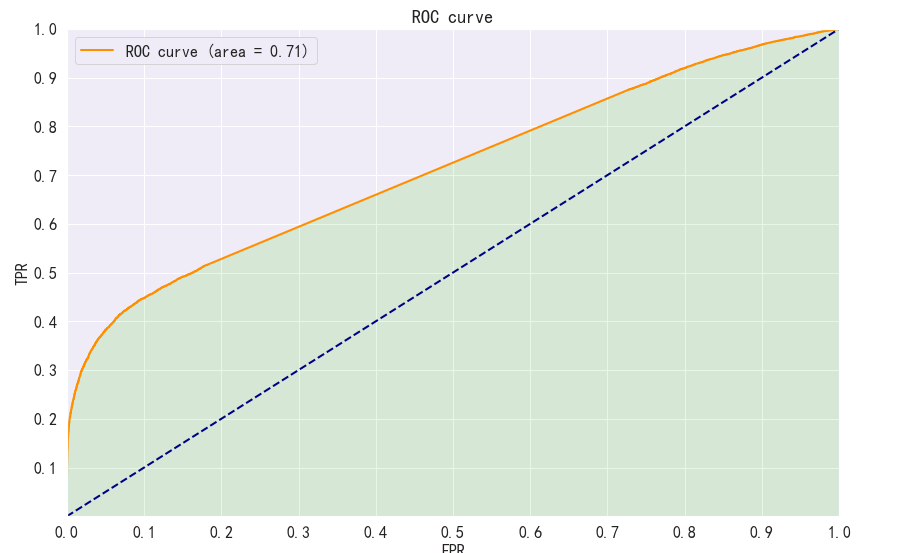
如上图PR曲线和KS曲线均出现了断崖式的奇怪形状,而且ROC曲线前部分还可以,后半部分接近直线了,也比较一般。经过看人数分组和分数分组才发现,是有将近1.8万人最后预测的分数一模一样,这就很奇怪了,怎么会这么多人分数一模一样呢?
把1.8万人提出来分别看各个特征才发现,原来这部分人的所有特征都为NULL,也就是与第三方撞库的时候没有匹配上,而在建模前也没有剔除这部分用户。剔除这部分用户后曲线一切变正常了,此时KS=0.466,AUC=0.792,top35%recall=0.554,如下:

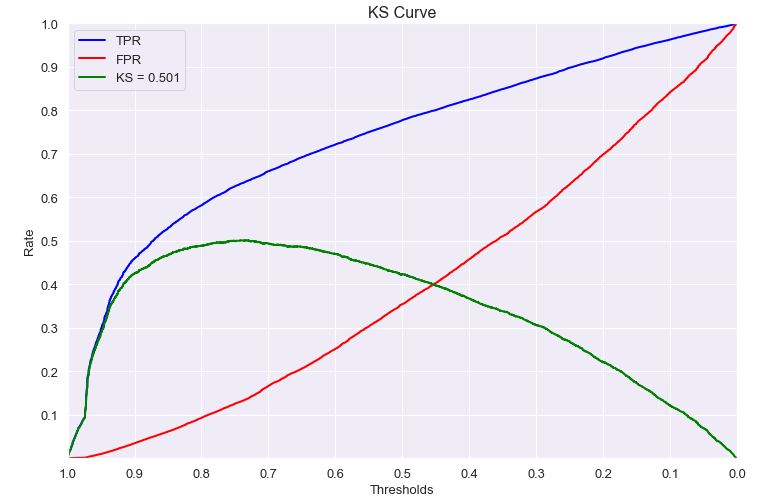

总结:
1)建模前一定要把缺失率非常高的用户剔除掉,尤其接近100%缺失率的用户,否则影响模型效果。
2)曲线不正常了,一定要细细分析一下什么原因,往往都是数据有问题造成的,通过曲线异常能帮助找出数据的问题。