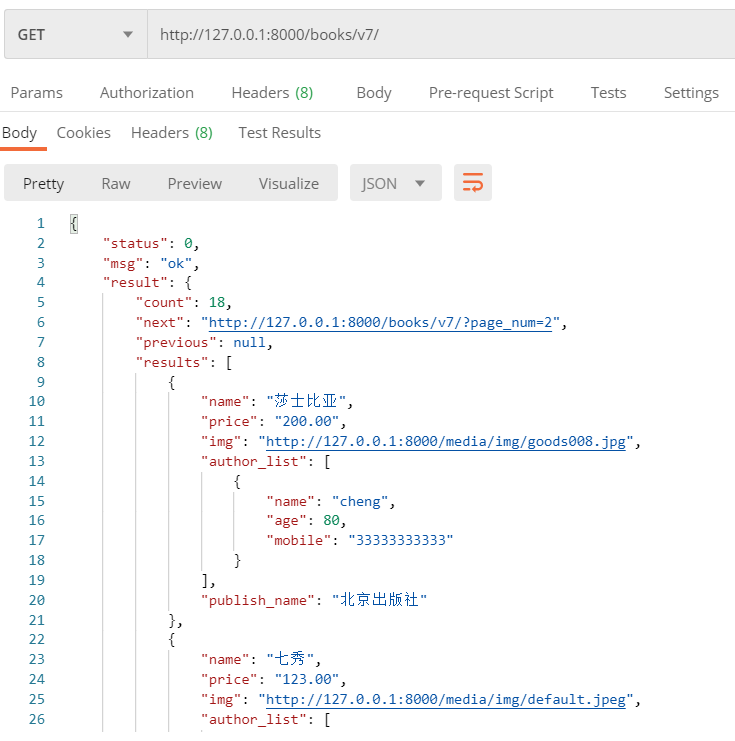
分页器/过滤器只有在视图类继承GenericAPIView或者viewsets的类的时候才会自动执行分页, 如果继承的是常规APIView,则需要自己调用分页API,以确保响应中包含分页数据。
我们可以看到在GenericAPIView类中定义了过滤类属性 filter_backends = api_settings.DEFAULT_FILTER_BACKENDS 和分页类属性 pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
对应的方法是 filter_queryset(self, queryset) 和 paginator(self) , 可以看到settings默认的过滤器类是空列表 'DEFAULT_FILTER_BACKENDS': [] , 分页器类是None 'DEFAULT_PAGINATION_CLASS': None
过滤器(Filter)
过滤器的作用就是将查询的数据进行过滤和排序, 且过滤和排序规则可以用户在url中指定. 如只查询名称中带有'记'的内容, 并将查询结果按创建降序排序
在rest_framework.filters中定义了两个过滤器类, OrderingFilter 和 SearchFilter
SearchFilter(查询过滤器)
支持基于简单的单个查询参数的搜索, 在SearchFilter类中我们可以看到两个关键类属性(search_param / lookup_prefixes)和一个实例方法(get_search_fields)
class SearchFilter(BaseFilterBackend): # URL中表示查询的关键字, 默认为search search_param = api_settings.SEARCH_PARAM # 查询内容的前缀符号 ''' ^ 以指定内容开始 = 完全匹配 @ 全文搜索(目前只支持Django的MySQL后端) $ 正则搜索 ''' lookup_prefixes = { '^': 'istartswith', '=': 'iexact', '@': 'search', '$': 'iregex', } # 在类属性search_fields中获取查询针对的字段, 可以是一个可迭代对象 def get_search_fields(self, view, request): return getattr(view, 'search_fields', None)
在使用SearchFilter类时必须在类视图中定义search_fields, 但是search_fields 只支持文本类型字段,例如 CharField 或 TextField 。
并且可以使用双下划线对ForeignKey或ManyToManyField执行关系查询, 如查询出版社的名称字段, 则为publish__name
class BookAuthViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet): ......代码省略 # 过滤器 filter_backends = [SearchFilter] search_fields = ['name', 'publish__name']
默认情况下,搜索不区分大小写,并使用部分匹配的模式。实际上,可以同时有多个搜索参数,用空格和/或逗号分隔。 如果使用多个搜索参数,则仅当所有提供的模式都匹配时才在列 表中返回对象。
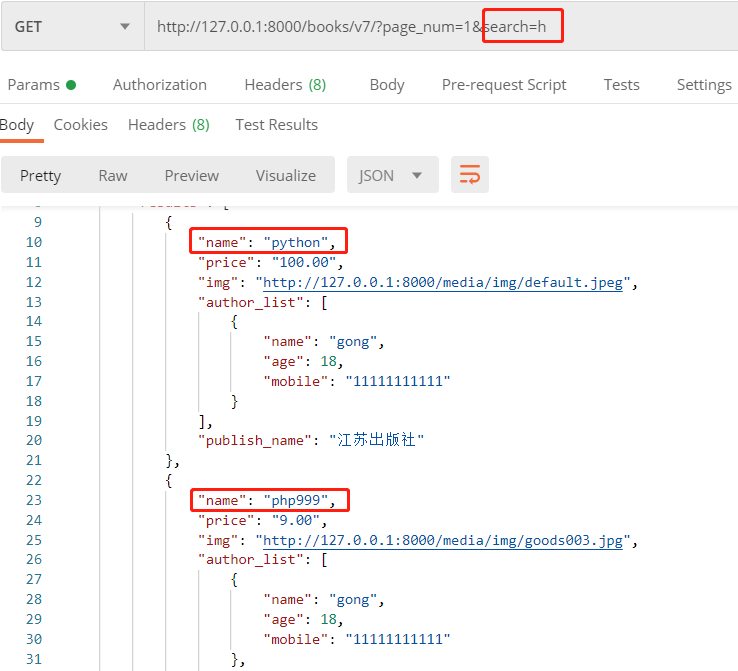
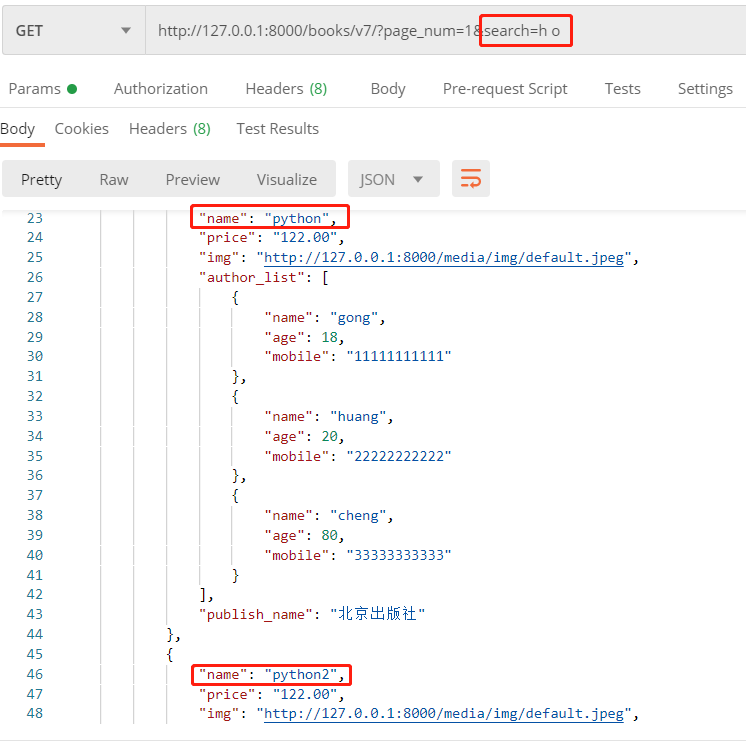
如查询书籍名称, 通过 search=h 能查出 python 和 php, 而通过 search=h o 只能查出python
OrderingFilter(排序过滤器)
该过滤器主要实现排序功能, 在OrderingFilter类中我们可以看到两个关键类属性(ordering_param / ordering_fields)和一个实例方法(get_default_ordering)
class OrderingFilter(BaseFilterBackend): # URL中表示排序的关键字, 默认为ordering ordering_param = api_settings.ORDERING_PARAM # 在类属性中指定只能通过这些字段进行排序 # 若未指定或指定为'__all__'则表示可以通过所有表字段进行排序 ordering_fields = None # 在类属性ordering中获取默认的排序字段 def get_default_ordering(self, view): ordering = getattr(view, 'ordering', None) if isinstance(ordering, str): return (ordering,) return ordering
我们可以继承该类创建自己的排序类, 主要是想要限制可排序的字段, 这有助于防止意外的数据泄漏,例如不小心允许用户针对密码字段或其他敏感数据进行排序。
class MyOrderingFilter(OrderingFilter): # 指定可以在哪些字段上进行排序过滤, 不指定或者指定为 __all__表示可以对所有字段排序 ordering_fields = ['name', 'create_time', 'price']
然后在视图类中指定排序器类, 并设置默认的排序字段(负号表示降序)
class BookAuthViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet): # 过滤器 filter_backends = [SearchFilter, MyOrderingFilter] # 查询的字段 search_fields = ['name', 'publish__name'] # 默认排序字段, 负号表示降序 ordering = ['-price', 'name']
分页器(Pagination)
分页器的作用就是将查询的数据分页返回给前端, 这样可以减少前后台数据传输的大小, 让用户只查询指定部分的数据, 减少了无用数据的展示. 如只查询第三页的内容, 每页展示10条数据.
在rest_framework.pagination中定义了三个分页器类, PageNumberPagination 和 LimitOffsetPagination 和 CursorPagination
PageNumberPagination
在PageNumberPagination类中定义了几个关键的类属性
class PageNumberPagination(BasePagination): # 每页的数据量大小, 默认为None page_size = api_settings.PAGE_SIZE # url中页码的参数名 page_query_param = 'page' # 也可以通过url参数控制每页的数据量大小 page_size_query_param = None # url中最大能输入的页码数 max_page_size = None
我们可以直接使用该类作为分页器类, 也可以创建继承该类的自定义分页器类, 只需要重写这些类属性就可以了, 如:
class MyPageNumberPagination(PageNumberPagination): # 每页的数据量大小, 默认为None page_size = 2 # url中页码的参数名 page_query_param = 'page_num' # 也可以通过url参数控制每页的数据量大小 page_size_query_param = 'page_size' # url中最大能输入的页码数 max_page_size = 10
实际效果为:
1. url中不输入任何参数, 那么自动展示第一页, 且每页展示2条数据
2. url中加入参数 page_num=n , 则展示第n页的数据, 且每页展示2条数据
3. url中再加入参数 page_size=m, 则该页展示的数据为m条, 而不只是2条
4. url中参数 page_num=n, 若n大于10 , 则报错页码错误
LimitOffsetPagination
该分页器类似于mysql的limit和offset, 即从第一条数据开始往下偏移offset条数据, 从第offset数据开始拿limit条数据展示出来
同样在LimitOffsetPagination类中定义了几个关键的类属性, 我们可以自定义分页器类继承该类:
class MyLimitOffsetPagination(LimitOffsetPagination): # 每次展示的数据量大小, 默认为None default_limit = 4 # url中每次展示数据量大小的参数名 limit_query_param = 'limit' # url中偏移量的参数名 offset_query_param = 'offset' # 每次展示的数量的最大值 max_limit = 10
实际效果为:
1. url中不输入任何参数, 那么偏移量offset=0, 展示第一到第四条数据
2. url中加入参数 limit=n , 那么偏移量offset=0, 展示第一到第n条数据
3. url中再参数 offset=m, 那么偏移量offset=m, 展示第m到第m+n条数据
4. url中参数 limit=n, 若n大于10 , 则报错页码错误
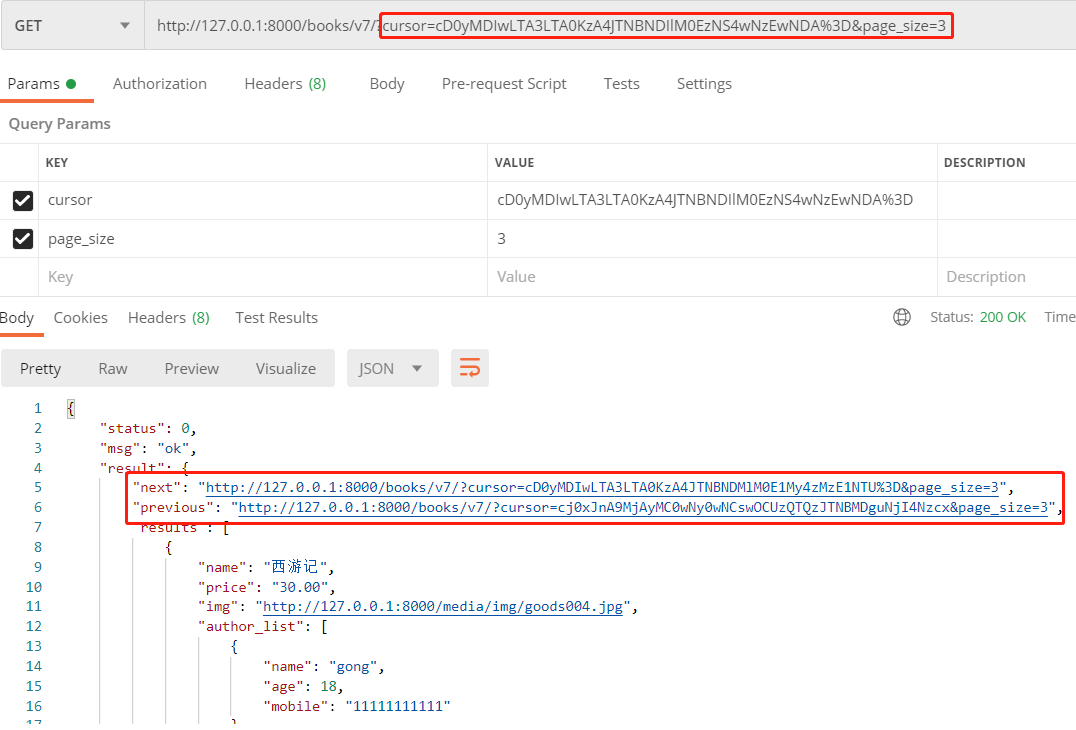
CursorPagination
该分页器与 PageNumberPagination 分页器功能类似, 只是url中不再是page=n, 而是 cursor=cD0yMDIwLTA3LT, 也就是说这个分页器将url的页码数进行了加密, 这样导致不能在url中随意输入想要跳转的页码, 只能通过放回的json字符串得知上一页的url和下一页的url, 这样能够起到保护数据的作用.
同样在CursorPagination类中定义了几个关键的类属性, 我们可以自定义分页器类继承该类:
class MyCursorPagination(CursorPagination): # url中游标变量名 cursor_query_param = 'cursor' # 每页的数据量大小, 默认为None page_size = 4 # 排序方式, 负号-create_time表示倒序 ordering = 'create_time' # 也可以通过url参数控制每页的数据量大小 page_size_query_param = 'page_size' # url中最大能输入的页码数 max_page_size = None
实际效果为:
1. url中不输入任何参数, 展示第一页的4条数据, 并在返回的json数据中可以拿到下一页的地址
2. url中加入参数 page_size=m, 则该页展示的数据为m条, 而不只是2条
版本(Versioning)
RESTful规范指出api最好都有版本控制, 而版本控制由传入的请求决定,可以放在URL上,也可以放在请求头中
DRF的版本模块对于版本信息所处的位置都有对应的类控制, 最终版本信息会放在request.version 属性中。 默认情况下,版本控制没有启用, request.version 将总是返回 None 。
源码流程
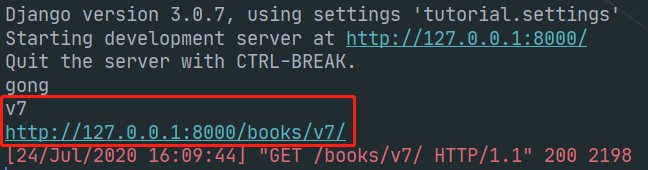
在dispatch中的 self.initial(request, *args, **kwargs) 中, 执行三大认证之前, 调用了 determine_version() 将版本的信息赋给了request对象,
def initial(self, request, *args, **kwargs): ......代码省略 # Determine the API version, if versioning is in use. version, scheme = self.determine_version(request, *args, **kwargs) request.version, request.versioning_scheme = version, scheme # Ensure that the incoming request is permitted # 认证 self.perform_authentication(request) # 权限 self.check_permissions(request) # 限流 self.check_throttles(request)
在 determine_version() 方法中拿到了配置的版本控制器类, 并调用了版本类的 determine_version() 方法, 说明版本类必须有 determine_version() 这个方法
def determine_version(self, request, *args, **kwargs): """ If versioning is being used, then determine any API version for the incoming request. Returns a two-tuple of (version, versioning_scheme) """ if self.versioning_class is None: return (None, None) scheme = self.versioning_class() return (scheme.determine_version(request, *args, **kwargs), scheme)
结合上一步操作, 我们可以看到赋给request对象的版本信息为: request.version 表示的是版本的信息, request.versioning_scheme 表示的是版本类的实例对象
版本类的设置 versioning_class 可以在类视图中设置, 也可以在项目的settings中设置, 一般我们会在settings中全局设置
在rest_framework.versioning中也定义了几个版本控制类:
BaseVersioning:基类,用于继承
AcceptHeaderVersioning(BaseVersioning):版本信息放在请求头中时使用
URLPathVersioning(BaseVersioning):版本信息放在URL中时使用
NamespaceVersioning(BaseVersioning):版本信息放在URL配置中时使用
HostNameVersioning(BaseVersioning):版本信息放在域名中时使用
QueryParameterVersioning:版本信息放在URL的参数中时使用
他们都重写了两个方法:
determine_version(): 用于获取版本号
reverse(): 用于反向解析, 其功能就是继承的Django的反向解析 django.urls.reverse, 即通过urls.py配置文件中的name参数和request即可反向解析到具体的url地址
版本类的用法
这里以常见的 URLPathVersioning 为例, 其他的类修改响应的配置即可:
1. 在视图类中定义类属性 versioning_class (这是局部配置, 也可在项目的settings中进行全局配置), 为了查看获取到的版本信息, 我们把request.version和反向解析到的地址也打印一下
class BookAuthViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet): .....代码省略 # 版本 versioning_class = URLPathVersioning def list(self, request, *args, **kwargs):print(request.version) print(request.versioning_scheme.reverse(viewname='v7', request=request))
2. 在urls.py中设置path路径, 设置了一个version变量, 并设置了name属性, 用于反向解析
urlpatterns = [ ... path('<version>/', views.BookAuthViewSet.as_view({'get': 'list'}), name='v7'), ]
我们访问url查看结果, 接口数据返回正常, 控制台也打印出了版本信息和反向解析的地址