这里通过使用Scrapy对链家上的成都新房进行爬取
所需信息,房源名称,售价,大小,位置
创建Spider
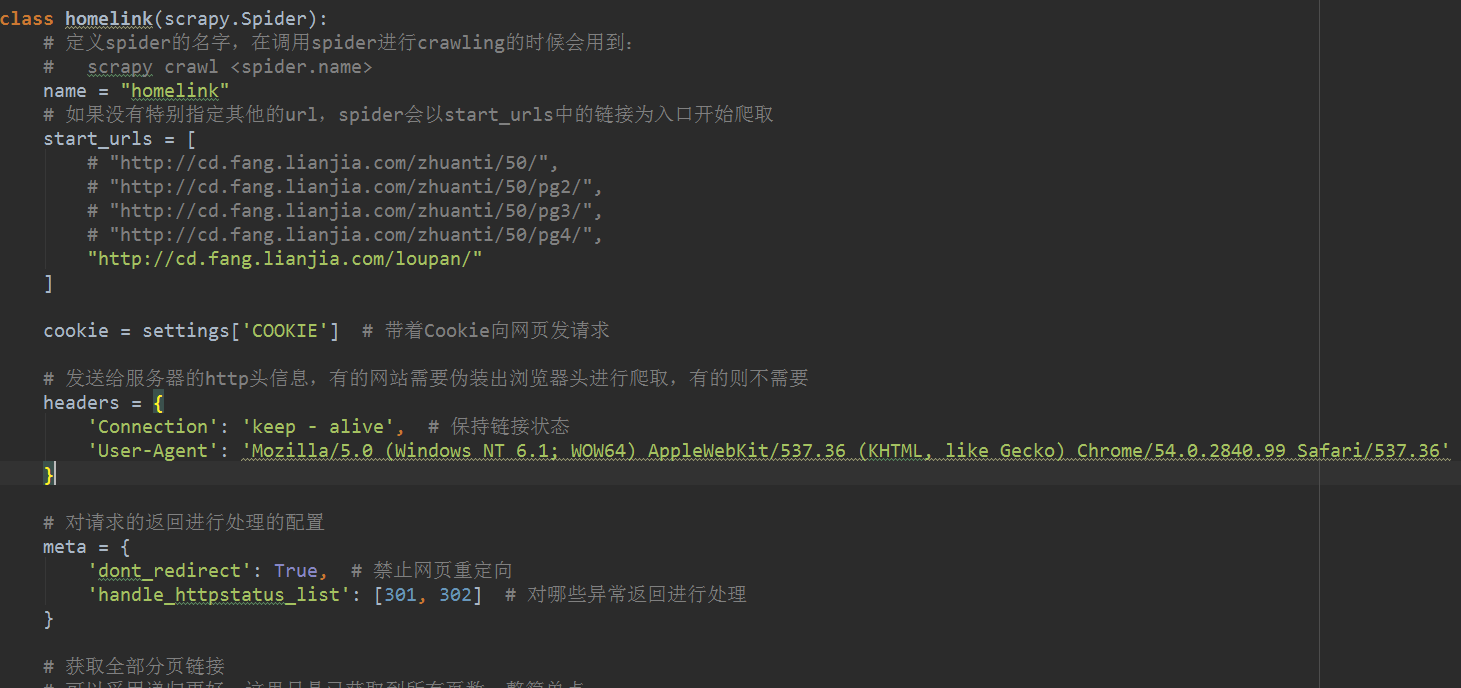
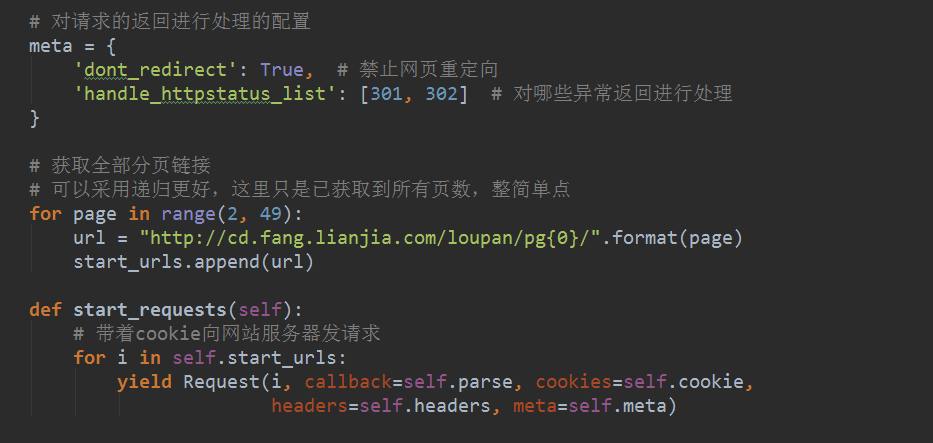
import scrapy class homelink(scrapy.Spider): # 定义spider的名字,在调用spider进行crawling的时候会用到: # scrapy crawl <spider.name> name = "homelink" # 如果没有特别指定其他的url,spider会以start_urls中的链接为入口开始爬取 start_urls = [ "https://m.lianjia.com/cd/loupan/" ] # 获取全部分页链接 # 可以采用递归更好,这里只是已获取到所有页数,整简单点 for page in range(1, 50): url = "https://m.lianjia.com/cd/loupan/pg{0}/".format(page) start_urls.append(url) # parse是scrapy.Spider处理http response的默认入口 # parse会对start_urls里的所有链接挨个进行处理 def parse(self, response): pass
分析网站:
链接新房售价页面,每个房源对应一个item_list,找到房源名称div,。
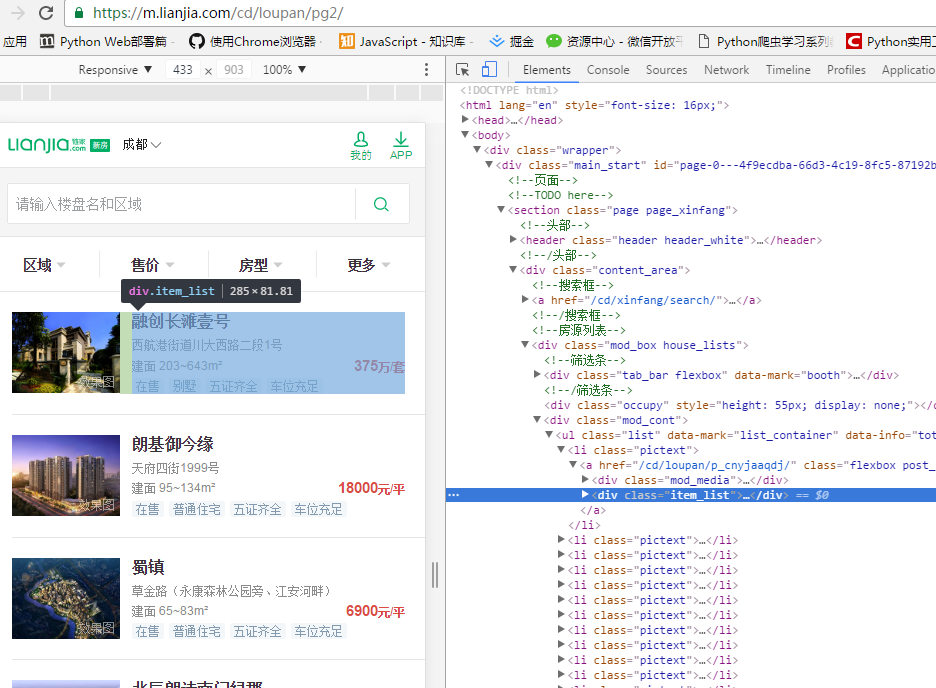
进一步分析每个房源信息,包括所对应的售价,位置信息,看似比较简单。
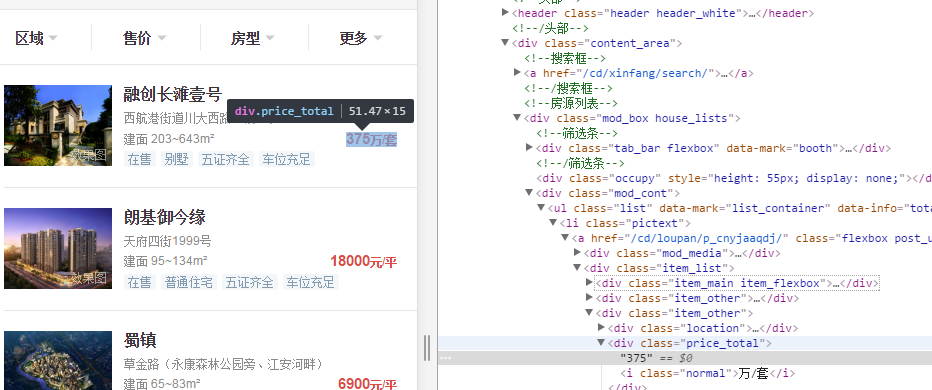
接下来就是直接在spider回调函数中通过selector 把所要的信息拿出来,so easy。
简单代码完整后:
# -*- coding: utf-8 -*- import scrapy class homelink(scrapy.Spider): # 定义spider的名字,在调用spider进行crawling的时候会用到: # scrapy crawl <spider.name> name = "homelink" # 如果没有特别指定其他的url,spider会以start_urls中的链接为入口开始爬取 start_urls = [ # "http://cd.fang.lianjia.com/zhuanti/50/", # "http://cd.fang.lianjia.com/zhuanti/50/pg2/", # "http://cd.fang.lianjia.com/zhuanti/50/pg3/", # "http://cd.fang.lianjia.com/zhuanti/50/pg4/", "https://m.lianjia.com/cd/loupan/" ] # 获取全部分页链接 # 可以采用递归更好,这里只是已获取到所有页数,整简单点 for page in range(1, 50): url = "https://m.lianjia.com/cd/loupan/pg{0}/".format(page) start_urls.append(url) # parse是scrapy.Spider处理http response的默认入口 # parse会对start_urls里的所有链接挨个进行处理 def parse(self, response): # 获取当前页面的房屋列表 # print 'xxx', response # house_lis = response.xpath('//ul[@class="house-lst"]/li/div[@class="info-panel"]') # all_page = response.xpath('//*[@id="matchid"]/div/div/div') loupan = response.xpath("//div[@class='item_list']") with open("homelink.log", "ab+") as f: for house_li in loupan: title = house_li.xpath( './div[@class="item_main item_flexbox"]/span[@class="name text_cut"]/text()').extract_first() where = house_li.xpath( './div/span[@class="location text_cut"]/text()').extract_first() area = house_li.xpath( './div/div[@class="location"]/text()').extract_first() price = house_li.xpath( './div/div[@class="price_total"]/text()').extract_first() # print "Title: {0} Price:{1} Link: {2} Area: {3} ".format(title.encode('utf-8'), price, where, # print "Title:{0} Price:{1} Area:{2} Link:{3} ".format(title.encode('utf-8'), price, area.encode('utf-8'), # where.encode('utf-8')) f.writelines( "Title:{0} Price:{1} Area:{2} Link:{3} ".format(title.encode('utf-8'), price, area.encode('utf-8').strip().replace( ' ', ''), where.encode('utf-8').strip().replace( ' ', '')))
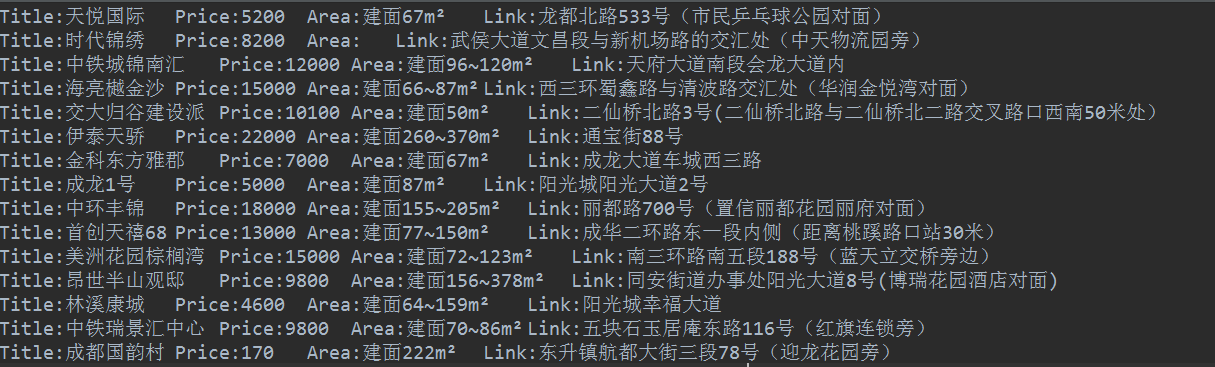
生成结果如下(后面可以整个数据库存起来,分析下各区域房价走势。。呵呵呵):
PS:
1. 不知道为啥从链家首页进入所有新房页面,会跳转到移动版。。
2. https网站直接爬取会被禁止,可设置ROBOTSTXT_OBEY = False。
3. 写文件的时候老是最后两行空行,后来发现是原始数据里面很多空格,需要去掉。。坑!
补充:
对于有些网站防爬虫的,可以设置一些cookie, header模拟浏览器。