现在假设一个 B 继承自 A ,因此,B* 可以用作 A*。类似的,一个B&可以用作 A&。但是,一个 A 不一定是一个 B,因此,A*不能用作B*。一般而言,如果一个类Derived有一个公有基类Base,那么我们就可以将一个Derived* 赋予一个Base* 类型的变量而无须显式类型转换。而相反的转换,即从Base* 到Derived* ,必须是显式的。例如:
void g(Manager mm,Employee ee) { Employee* pe = &mm; //正确:每个Manager都是一个Employee Manager* pm = ⅇ //错误:并不是每个Employee都是一个Manager pm->level = 2; //灾难:ee不包括level pm = static_cast<Manager*>(pe); //暴力转换;可奏效,因为pe指向Manager mm pm->level = 2; //没问题:pm指向Manager mm,包含level }
换句话说,若通过指针和引用进行操作,派生类对象可以当做其基类对象处理,反过来则不能。
将一个类用作基类等价于定义一个该类的(无名)对象;因此,类必须定以后才能用作基类。
虚函数
虚函数机制运行程序员在基类中声明函数,然后在每个派生类中重新定义这些函数,从而解决了类型域方法固有的问题。(类型域方法的问题:随着程序规模的增加,问题就变得严重。类型域的使用违反了模块化和数据隐藏的思想。使用类型域的每一个函数都必须了解包含类型域的类的派生类的实现细节。而且,所有派生类都可以访问类型域这样的公共数据,这似乎会诱使人们添加更多这样的数据。公共基类从而变成所有“有用信息”的仓库,这最终会使得基类和派生类的实现变得错综复杂。)
如果派生类中的一个函数的名字和参数类型与基类中的一个虚函数完全相同,称之为覆盖(override)了虚函数的基类版本。首次声明虚函数的类必须定义它。即使没有派生类,也可以定义虚函数,而一个派生类如果不需要虚函数,可以不定义它。
具有虚函数的类型称为多态类型,或运行时多态类型;在C++中为了获得运行时多态行为,必须调用virtual成员函数,对象必须通过指针或者引用进行访问。当直接操作一个对象时(而不是通过指针或引用),编译器了解其确切类型,从而就不需要多态了。
默认情况下,覆盖虚函数的函数自身也可变为virtual的。在派生类中可以重复关键字virtual,但并不是必须,不建议重复virtual.
显然,为了实现多态,编译器必须在每个含virtual的基类的对象中保存某种类型的信息,并利用它选择虚函数的合适版本。在一个典型的C++实现中,这只会占用一个指针大小的空间:常用的编译器实现技术是将虚函数名转换为函数指针表中的一个索引。这个表称为虚函数表(the virtual function table)或简称vbtl。每个具有虚函数的类都有自己的vbtl,用来表示它的虚函数。
下图取自C++程序设计语言 504页:
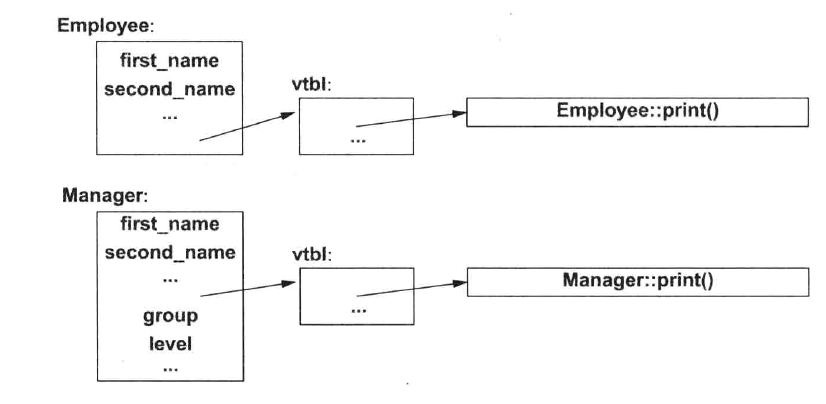
vbtl中的函数令对象能正确使用,即使调用者不了解对象的大小和数据布局也没有关系。调用者的实现只需了解在一个Employee中vbtl的位置以及每个虚函数的索引是多少就可以了。
使用作用域解析运算符::调用函数(如Manager::print())能保证不使用virtual机制:
void Manager::print() const { Employee::printf(); //不是一个调用 cout << " level" << level << ' '; //... }
否则,Manager::print()会面临一个无限递归。使用限定名还有另外一个效果,即,如果一个虚函数也是一个inline,对于使用::限定的调用就可以进行内联替换。这给程序员提供了一个方法高效处理某些重要的特殊情形---一个虚函数对相同对象调用另一个虚函数,函数Manager::print()就是这样一个例子。由于在调用 Manager::print()时已经确定了对象的类型,就没有必要再次动态确定Employee::print()了。
覆盖控制:
如果在派生类中声明一个函数,其名字和类型都与基类中的一个虚函数完全一样,则派生类中的这个函数就覆盖了基类中的版本。但在更大的类层次中,很难保证真的覆盖了想要覆盖的函数。考虑如下代码:
struct B0{ void f(int) const; virtual void g(double); }; struct B1 : B0{/*...*/}; struct B2 : B1{/*...*/}; struct B3 : B2{/*...*/}; struct B4 : B3{/*...*/}; struct B5 : B4{/*...*/}; struct D:B5{ void f(int) const; //覆盖基类中的f() void g(int); //覆盖基类中的g() virtual int h(); //覆盖了基类中的h() };
这段代码展示3个错误,如果是在一个真实的类层次中,类B0...B5有很多成员且散布在很多头文件中,这些错误就很难发现。它们是:
B0::f()不是virtual的,因此不能覆盖它,只会隐藏; D::g()的参数类型与B0::g()不同,因此如果它覆盖了什么东西,也不会是虚函数B0::g()。最可能的是,D::g()只能隐藏了B0::g(); 在B0中没有名为h()的函数,如果D::h()覆盖了什么东西,也不会是B0中的函数。可能性最大的是它引入的是一个全新的虚函数。 对于小型程序而言,实现正确的覆盖并不难,但对大型类层次,需要特定的控制机制了:
1 virtual:函数可能被覆盖
2 =0:函数必须是virtual的,且必须被覆盖
3 override:函数要覆盖基类中的一个虚函数
4 final:函数不能被覆盖
如果不使用这些覆盖控制,一个非static成员函数为虚函数当且仅当它覆盖了基类中的一个virtual函数。
override:我们可以显式的说明想要覆盖:
struct D : B5{ void f(int) const override; //错误:B0::f()不是虚函数 void g(int) override; //错误:B0::f()接受一个double参数 virtual int h() override; //错误:不存在函数h()可覆盖 };
这个定义中的3个声明都是错误的(假定中间层基类不提供相关函数)。在一个有很多虚函数的大型或者复杂类层次中,virtual和override最好的使用方式是前者只用来引入新的虚函数,而后者指出函数要覆盖某个虚函数。使用override有点啰嗦,但能澄清程序员意图。
说明符override出现在声明的最后。例如:
void f(int) const noexcept override;//正确:(如果有一个合适的f()可覆盖) override void f(int) const noexcept;//语法错误 void f(int) override const noexcept;//错误
说明符override不是函数类型的一部分,而且在类外定义中不能重复;而且override不是关键字,它是所谓的 上下文关键字。即,override在某些上下文中有特殊含义,但在其他地方可用作标识符。另外一个上下文关键字是final
final:final上下文关键字的目的是防止被覆盖,在一个函数尾部加上final,子类中再对其进行覆盖会发生错误。具体参考:链接
using 基类成员:
函数重载不会跨越作用域。