- 注:完全搬自wikipedia,仅用于总结之用
-
冒泡排序
它重复地走访过要排序的数列,一次比较两个相邻元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
时间复杂度:(平均/最坏) O(n2) 需要O(n)额外空间
void bubble_sort(int *arr, int len) { int i, j, temp; for (i = 0; i < len - 1; i++) { for (j = 0; j < len - 1 - i; j++) if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } }
-
选择排序
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
时间复杂度:(平均/最坏) O(n2) 键的交换次数:O(n)
void selection_sort(int *arr, int len) { int i, j, min, temp; for (i = 0; i < len - 1; i++) { min = i; for (j = i + 1; j < len; j++) {
if (arr[min] > arr[j]) min = j; }//找出剩余未排序数组的最小值的位置
temp = arr[min]; arr[min] = arr[i]; arr[i] = temp; } }
-
插入排序
使用了减治法。通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。基于递归思想。从底至上使用迭代,效率会更高。
(对数组A[0 ... n-1] 进行排序,可以假设较小的A[0 ... n-2] 排序的问题已经解决了,得到一个大小为n-1的有序数组,所需要考虑的问题就是如何将元素A[n-1]插入有n-1个元素的有序数组。可以按照从右到左扫描此有序数组,选择合适的位置插入。显然,这是归。 )
图示:
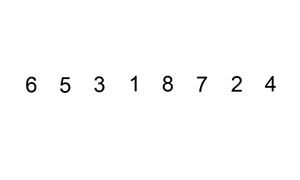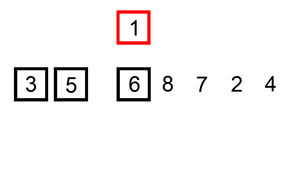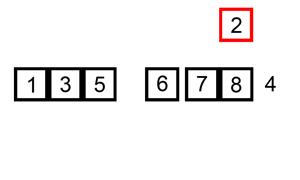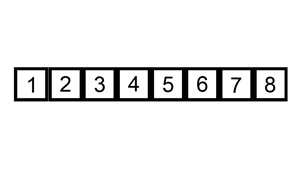
(署名:由Swfung8 - 自己的作品,CC BY-SA 3.0,https://commons.wikimedia.org/w/index.php?curid=14961606)
时间复杂度:(平均/最坏) O(n2)
void insertion_sort(int *A, int len) { int i, j; int temp; for (i = 1; i < len; i++) { temp = A[i]; //與已排序的數逐一比較,大於temp時,該數向後移 for (j = i - 1; j >= 0 && A[j] > temp; j--) //判决条件中A[j]>temp是终止条件 A[j + 1] = A[j]; A[j+1] = temp; //被排序数放到正确的位置 } }
- 希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法,实质是分组插入排序。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
一个更好理解的希尔排序实现:将数组列在一个表中并对列排序(用插入排序)。重复这过程,不过每次用更长的列来进行。最后整个表就只有一列了。将数组转换至表是为了更好地理解这算法,算法本身仅仅对原数组进行排序(通过增加索引的步长,例如是用i += step_size而不是i++)。
void shellSort(int* a,int n){ int gap,i,j; int tmp; for(gap = n>>1;gap > 0; gap >>= 1) for(i = gap;i < n; i++){ tmp = a[i]; for(j = i- gap;j >= 0 && a[j] > tmp;j -= gap) a[j + gap] = a[j]; a[j + gap] = tmp; } }
- 归并排序
分治法:
1) 将一个问题划分为同一类型的若干子问题,子问题最好规模相同。
2) 对这些子问题求解(一般使用递归方法,但在问题规模足够小的时候,有时也会利用另一个算法)。
3) 有必要的话,合并这些子问题的解,已得到原始问题的答案。
归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。
void merge(int *a, int first, int mid, int last) { int i = first, j = mid + 1; int m = mid, n = last; int k = 0; int* b = (int*)malloc((last-first + 1)* sizeof(int));//注意:元素个数为last-first+1,而不是last-first if (b ==NULL) { printf("malloc error! "); return 0; } while (i <= m && j <= n) b[k++] = (a[i] <= a[j]) ? a[i++] : a[j++]; while (i <= m) b[k++] = a[i++]; while (j <= n) b[k++] = a[j++]; for (i = first,k = 0; i <= last; i++,k++) a[i] = b[k];//注意:每次迭代first都是变化的,这个时候需要将数组b中的元素代会数组a,注意i的起始值 free(b);//释放堆上的变量 } //合并两个有序的序列
归并排序主要有两类主要的变化形式,首先,算法可以自底而上合并数组的一个个元素对,然后再合并这些有序对,以此类推(如果元素数量不算2的幂,算法的效率也没有质的变化)。这就避免了使用堆栈处理递归调用时的时间和空间开销,效率更高些,但可读性差,又称为二路合并排序。其次,可以把数组划分为待排序的多个部分,再对它们进行递归排序,最后将其合并在一起。
|
迭代法
空间复杂度:O(1) |
递归法:
空间复杂度:O(n) + O(logn) |
 个序列,排序后每个序列包含两个元素
个序列,排序后每个序列包含两个元素 个序列,每个序列包含四个元素
个序列,每个序列包含四个元素时间复杂度:(最好/平均/最坏) O(nlog2n)
//递归法(自顶而下法) void mergesort(int* a, int first, int last) { if (first < last) { int mid = (first + last) / 2; mergesort(a, first, mid); //左边有序 mergesort(a, mid + 1, last); //右边有序 merge(a, first, mid, last); //再将二个有序数列合并 } } void mergeSort(int* a, int n) { mergesort(a, 0, n - 1); }
//迭代法(自底而上法)
void mergePass(int *a, int seg, int n) { int i = 0; // 归并seg长度的两个相邻子表 for (i = 0; i + 2 * seg - 1 < n; i = i + 2 * seg) { Merge(a, i, i + seg - 1, i + 2 * seg - 1); } // 余下两个子表,后者长度小于gap(考虑到奇数) if (i + gap - 1 < n) { merge(a, i, i + seg - 1, n - 1); } } void mergeSort(int* a) { int seg; for (seg = 1; seg < n; seg *= 2;) { mergePass(a, seg, n); }
-
快速排序
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。
步骤为:
- 从数列中挑出一个元素,称为"基准"(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
快速排序是二叉查找树(二叉查找树)的一个空间最优化版本。不是循序地把数据项插入到一个明确的树中,而是由快速排序组织这些数据项到一个由递归调用所隐含的树中。这两个算法完全地产生相同的比较次数,但是顺序不同。对于排序算法的稳定性指标,原地分区版本的快速排序算法是不稳定的。其他变种是可以通过牺牲性能和空间来维护稳定性的。
时间复杂度:平均:O(nlogn) 最坏:O(n2) 空间:O(logn)
同样分为迭代实现和递归实现。代码为迭代实现:
//递归法实现快排 void swap(int * x,int * y){ int * t = *x; *x = *y; *y = t; } void quickSort(int* a,int start,int end){ if(start >= end) return; int mid = a[end]; int left = start,right = end -1; while(left < right) { while(a[left] < mid && left < right)//选取mid作为基准点 left++; while (a[right] >= mid && left < right)//注意:是大于等于 right--; swap(&a[left], &a[right]); } if(a[lest] >= a[end]) swap(a+left,a+end); else left++; quickSort(a,start,left-1);//注意:选择的基准不在参与迭代排序 quickSort(a,left+1,end); } void quick_sort(int *a,int n) { quickSort(a,0,n-1); }
参考blog:blog1
-
堆排序
是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
时间复杂度:O(N*logN)
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
通常堆是通过一维数组来实现的。在数组起始位置为0的情形中:
- 父节点i的左子节点在位置(2*i+1);
- 父节点i的右子节点在位置(2*i+2);
- 子节点i的父节点在位置floor((i-1)/2);
参考链接: blog1