在深度学习中,样本量和参数有什么关系呢?
是不是样本量越大?参数越多?模型表现会越好?
参数越多自然想到可能会出现过拟合,样本量与参数量应该保持怎样的关系?
参考论文Scaling Laws for Neural Language Model
summary
文章主要讨论了如下几个问题
**Performance depends strongly on scale, weakly on model shape: **Model performance depends most strongly on scale, which consists of three factors: the number of model parameters (N) (excluding embeddings), the size of the dataset (D), and the amount of compute (C) used for training. Within reasonable limits, performance depends very weakly on other architectural hyperparameters such as depth vs. width. (Section 3)
模型效果更多的依赖于参数的规模,较少的依赖于模型的形状
模型的性能依赖于模型的规模,模型的规模主要由三部分组成:模型参数N(包括emb的数量),数据集的大小D,还有算力C,模型性能主要受限于这三个因素,和模型的深度和宽度关系不大。
这部分在文章第三部分讨论
Smooth power laws Performance has a power-law relationship with each of the three scale factors (N, D, C) when not bottlenecked by the other two, with trends spanning more than six orders of magnitude (see Figure 1). We observe no signs of deviation from these trends on the upper end, though performance must flatten out eventually before reaching zero loss. (Section 3)
平滑幂定律
影响模型性能的三个要素之间存在幂指数的关系,每个参数并受另外两个参数影响。在fig1中有超过6个数量的对比。本文实验中没有很大的偏离现象,在达到零损失之前,性能最终会趋于平缓。

The test loss of a Transformer trained to autoregressively model language can be predicted using a power-law when performance is limited by only either the number of non-embedding parameters (N), the dataset size (D), or the optimally allocated compute budget (C_{min }) (see Figure 1):
一个transformer模型的训练损失可以使用下面的公式衡量
- For models with a limited number of parameters, trained to convergence on sufficiently large datasets:
如果受模型参数限制,那模型效果主要依赖样本量
- For large models trained with a limited dataset with early stopping:
样本量有限的大模型,训练会早停
- When training with a limited amount of compute, a sufficiently large dataset, an optimally-sized model, and a sufficiently small batch size (making optimal (^{3}) use of compute):
对于算力受限,充足的样本量+最优的模型+较小的bz
Universality of overfittingPerformance improves predictably as long as we scale up (N) and (D) in tandem, but enters a regime of diminishing returns if either (N) or (D) is held fixed while the other increases. The performance penalty depends predictably on the ratio (N^{0.74} / D), meaning that every time we increase the model size (8 mathrm{x}), we only need to increase the data by roughly (5 mathrm{x}) to avoid a penalty. (Section 4())
过拟合的普遍性
同时增加N和D模型表现就会提升,但是N和D保持不变模型表现保持不变。模型表现主要取决于一个比例系数 (N^{0.74} / D),这个系数的啥意思?就是模型参数增加8倍,训练集的量要增加5倍。
这个是本文给出的参数量和训练样本的一个关系。
Universality of trainingTraining curves follow predictable power-laws whose parameters are roughly independent of the model size. By extrapolating the early part of a training curve, we can roughly predict the loss that would be achieved if we trained for much longer. (Section 5)
训练的普遍性
训练曲线也是呈现幂指函数,模型的参数和模型的大小无关。从初期收敛曲线可知,如果训练时间长,造成的损失将会更多。
Transfer improves with test performanceWhen we evaluate models on text with a different distribution than they were trained on, the results are strongly correlated to those on the training validation set with a roughly constant offset in the loss - in other words, transfer to a different distribution incurs a constant penalty but otherwise improves roughly in line with performance on the training set. (Section 3.2.2)
迁移学习提升测试集的表现
当评估与训练时不同分布的文本模型时,结果与训练验证集上的模型有很强的相关性,损失的偏移量大致不变——换句话说,迁移到不同的分布会带来不变的惩罚,但在其他方面会根据训练集上的性能得到大致的改善。
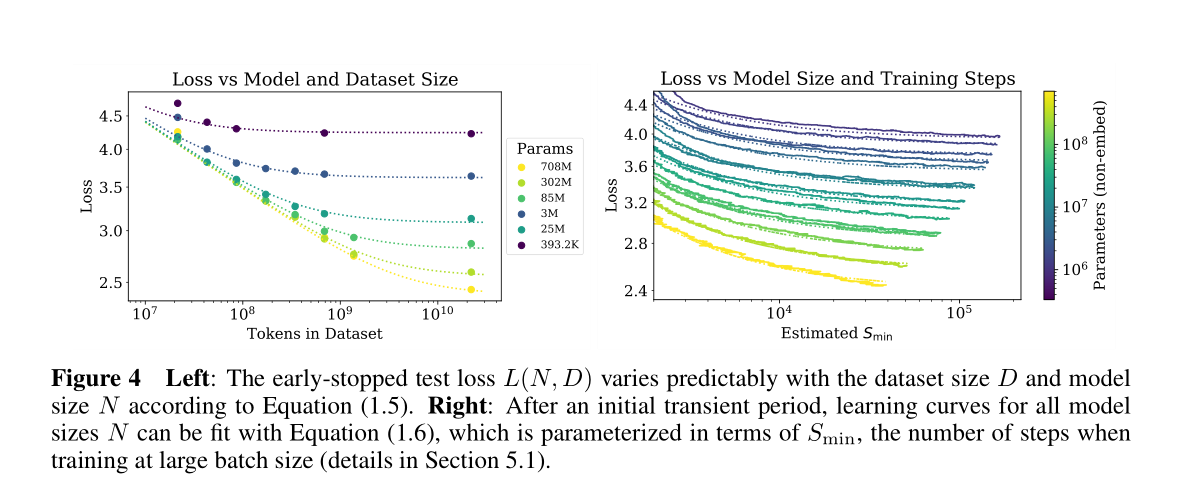
Sample efficiencyLarge models are more sample-efficient than small models, reaching the same level of performance with fewer optimization steps (Figure 2) and using fewer data points (Figure 4).
抽样的有效性大型模型比小型模型更具有样本效率,可以用更少的优化步骤达和较少的样本点到相同的性能水平结果参考如下fig2,fig4
这个感觉更多的是迁移学习的作用,大模型训练好了迁移到下游任务做微调。
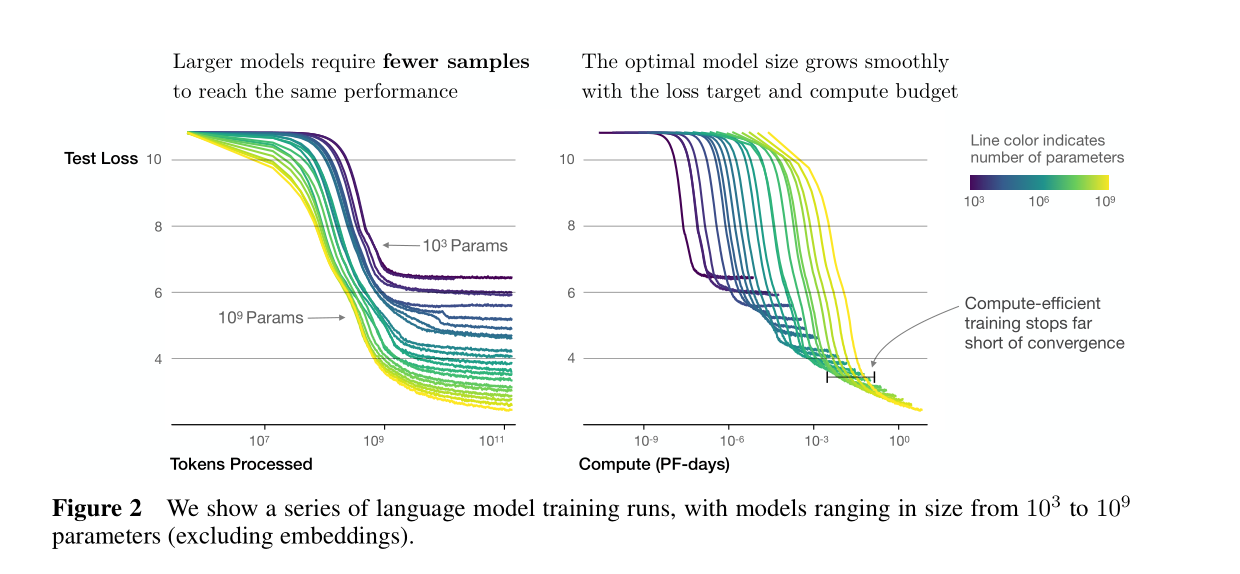
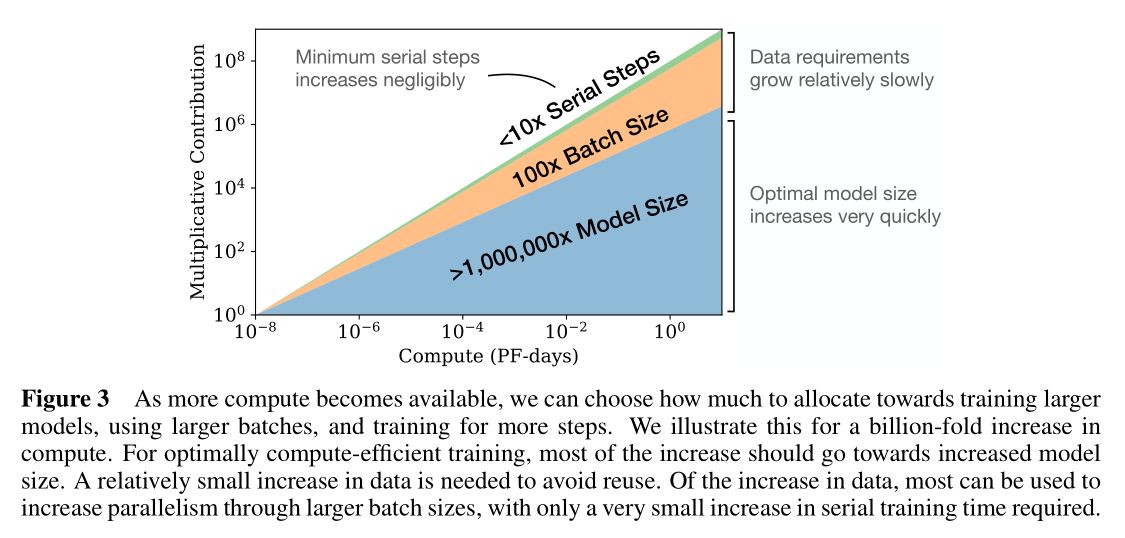
Convergence is inefficientWhen working within a fixed compute budget (C) but without any other restrictions on the model size (N) or available data (D), we attain optimal performance by training very large models and stopping significantly short of convergence (see Figure 3). Maximally compute-efficient training would therefore be far more sample efficient than one might expect based on training small models to convergence, with data requirements growing very slowly as (D sim C^{0.27}) with training compute. (Section 6)
收敛效率比较低
当算力是固定的时但对模型大小(N)或可用数据(D)没有任何其他限制时,通过训练非常大的模型并停止明显低于收敛速度来获得最优性能(见图3)。因此,计算效率最高的训练将远比基于训练小模型以收敛的预期的样本效率更高,数据需求增长非常缓慢,如使用训练计算的(D sim C^{0.27})。
简单的来说就是算力足够,模型参数和训练集越大越好。
Optimal batch size The ideal batch size for training these models is roughly a power of the loss only, and continues to be determinable by measuring the gradient noise scale [MKAT18]; it is roughly (1-2) million tokens at convergence for the largest models we can train. (Section 5.1)
Taken together, these results show that language modeling performance improves smoothly and predictably as we appropriately scale up model size, data, and compute. We expect that larger language models will perform better and be more sample efficient than current models.
优化batchsize
训练这些模型的理想批量大小大致仅是损失的一个幂次。并继续通过测量梯度噪声来确定bz[MKAT18];它大约是1-2百万的token在训练至最后收敛。
总的来说这些结果表明,当适当地扩大模型规模、数据和计算时,语言建模性能会平稳和可预测地提高,期望更大的语言模型会比当前的模型表现得更好,样本效率更高.这就是本文的初步结论。