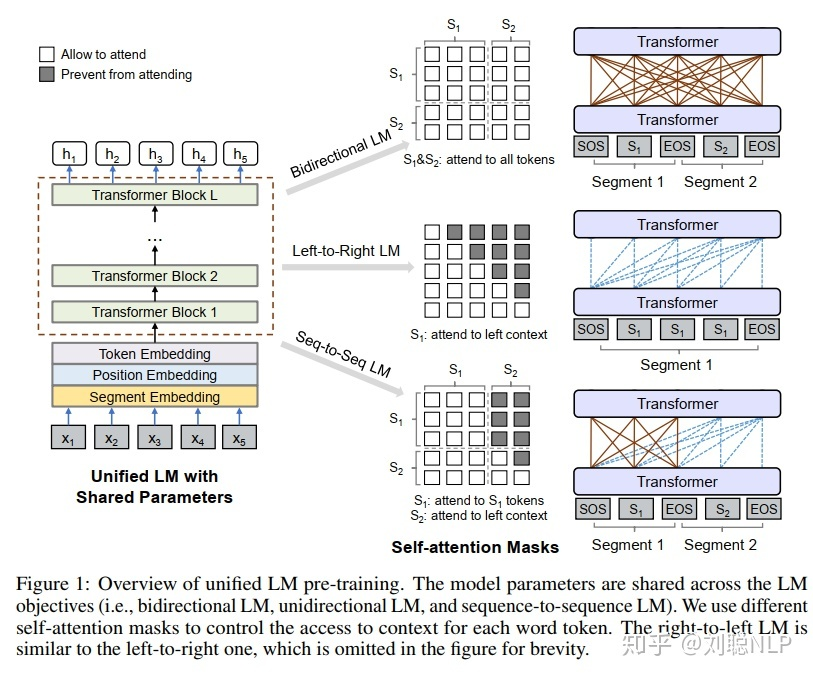
unilm_v1
直接copy刘聪nlp的结论啦~
看上去结构比较简单
UniLM模型参数通过最小化预测token和标准token的交叉嫡来优化。三种类型的完型填空任务可以 完成不同的语言模型运用相同的程序程序训练。
- 单向语言模型:有从右到左和从左到右两者,以从左到右为例进行介绍。每个特殊标记 [Mask] 的预测,仅采用它自身和其左侧的token进行编码。例如,我们预测序列 (x_{1} x_{2}[operatorname{mas} k] x_{4}) 中的 [Mask] ,我们仅可以利用 (x_{1}) 、 (x_{2}) 和它自身进行编码。具体操作,如图1所示,使用一个上三 角矩阵来作为掩码矩阵。阴影部分为 (-infty) ,空白部分为0。
这个结构主要是为了生成任务。和elmo的双向感觉有那么一丢丢的相似
- 双向语言模型:跟Bert模型一致,每个特殊标记 [Mask] 的预测,可以使用所有的token进行编 码。例如,我们预测 序列 (x_{1} x_{2}[) mask (] x_{4}) 中的 (mathbf{[ M a s k l}), 我们仅可以利用 (x_{1}, x_{2}, x_{4}) 和 它自身进行编码。具体操作,如图1所示,使用全0矩阵来作为掩码矩阵。
这个和bert中的mlm是一致的
- 序列到序列语言模型:如果预测的特殊标记 [Mask] 出现在第一段文本中时,仅可以使用第一段 文本中所有的token进行预测; 如果:如果预测的特殊标记 (mathbf{I M a s k} mathbf{~ 出 现 在 第 二 段 文 本 中 时 , 可 以 ~}) 采用第一段文本中所有的token, 和第二段文本中该预测标记的左侧所有tokne以及它本身。例如, 我们预测序列 ([S O S] x_{1} x_{2}[operatorname{mask} 1] x_{4}[operatorname{EOS}] x_{5} x_{6}[) mask 2(] x_{8}[E O S]) 中的 [mask1] 时,除去
去 [SOS] 和 (left[mathrm{EOS} ight.) ], 我们仅可以利用 (x_{1}) 行编码。具体操作,如图1所示。
由于在训练时,将源文本和目标文本结合进入模型,使模型可以含蓄地学习到两个文本之间关系, 可以做到seq-to-seq的效果。
这个笔者感觉是增加了一个句子编码的位置信息,可以充分利用向量的信息。
NSP任务:对于双向语言模型,与bert模型一样,也进行下一个句子预测。如果是第一段文本的下 一段文本,则预测1; 否则预测0。