吴恩达讲深度学习
为什么要学习深度学习
1.数据量更大
2.算法越来越优
3.业务场景越来越多样化
4.学术界or工业界越来越卷(私以为!)
从逻辑回归讲起
逻辑回归是最简单的二分类模型,也可以说是后续深度神经网络的基础框架.达叔的算法知识第一课.
逻辑回归的参数是W和b,也是主要学习的参数矩阵
(hat{y}=sigmaleft(w^{T} x+b
ight),) where (sigma(z)=frac{1}{1+e^{-z}})
Given (left{left(x^{(1)}, y^{(1)}
ight), ldots,left(x^{(m)}, y^{(m)}
ight)
ight},) want (hat{y}^{(i)} approx y^{(i)})
损失函数/误差函数主要是衡量单一样例的模型训练效果的,希望模型得到的(hat{y}^{(i)})是无限趋近于实际的值 (y^{(i)}),二成本函数是 用来衡量参数w和参数b的效果的.
逻辑回归的梯度下降
(z=w^{T} x+b)
(hat{y}=a=sigma(z))
(mathcal{L}(a, y)=-(y log (a)+(1-y) log (1-a)))
导数的细节
- 函数的导数就是函数的斜率
向量化
为什么要向量化实现,因为对比for循环来说,向量化的方式可以大大减小运行时间。下面给出达叔给出的例子
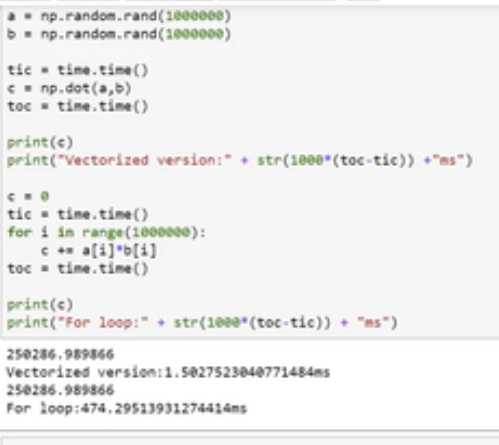
上面是向量化的实现方式,而下面是for循环的实现方式,可以提升300倍,所以写代码的时候尽量避免for循环,numpy和pandas是两个不错的选择.
因此在实现一个算法时候考虑到了矩阵的向量化的形式。
python中的广播
感觉达叔讲的这个广播机制更像是numpy中的矩阵方法教学,能够使代码写起来方便简洁
第二部分深度学习内容
从神经网络讲起
- 神经网络中输入层一般不算在神经网络层里面,是第0层,因此神经网络的层数是从隐藏层开始数起
- 神经网络也是向量化的实现方式

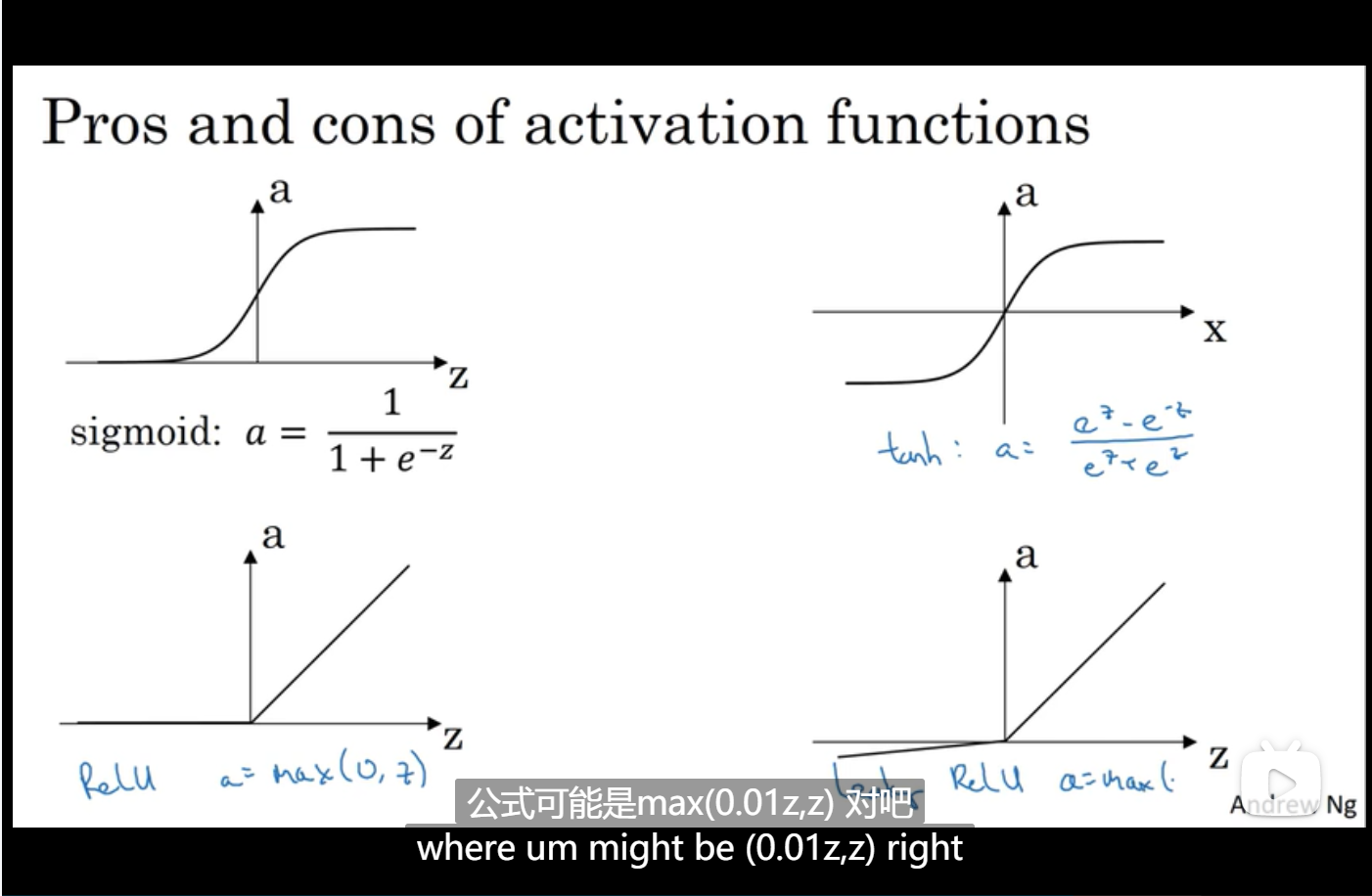
激活函数
为什么要进入非线性的激活层
andrew的解释是:为了使计算更加有趣,因为使用线性的几乎使没有用的,,使用线性激活方式的只有一个场景:回归问题
激活函数的作用:是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。简单来说起到一个映射的作用,不同层的激活函数有可能不一样。
sigmoid 映射到(0,1),只能用到二分类上面,或者一般不用
tanh 映射到(-1,1)
relu 也就是修正函数,映射到[0,+无穷],在0处的导数是0
leaky relu,在0处的导数缓慢的接近于0
直观理解反向传播
反向传播就是不断地反向求偏导数,因为前向传播也是用到了微积分的链式乘法法则,因此反向求导时候需要用到链式求导法则,不断的求偏导

随机初始化
主要是对每个神经元上面的权重进行随机初始化
- 若初始的权重全部的设置为0,则梯度下降法是无效的,因为每次梯度的更新都没有变化,都是0,