最近真的被mask搞得晕晕的,还是需要好好的看下哦
1、padding mask:处理非定长序列,区分padding和非padding部分,如在RNN等模型和Attention机制中的应用等
2、sequence mask:防止标签泄露,如:Transformer decoder中的mask矩阵,BERT中的[Mask]位,XLNet中的mask矩阵等
PS:padding mask 和 sequence mask非官方命名
嗯,上面的解释还是很晕的,还是要具体解读一下的
本文参考知乎:https://zhuanlan.zhihu.com/p/139595546
后面读了具体论文之后如有错误再修改
RNN中的Mask
对于RNN等模型,本身是可以直接处理不定长数据的,因此它不需要提前告知 sequence length,如下是pytorch下的LSTM定义:
nn.LSTM(input_size, hidden_size, *args, **kwargs)
但是在实践中,为了 batch 训练,一般会把不定长的序列 padding 到相同长度,再用 mask 去区分非 padding 部分和 padding 部分。
区分的目的是使得RNN只作用到它实际长度的句子,而不会处理无用的 padding 部分,这样RNN的输出和隐状态都会是对应句子实际的最后一位。另外,对于token级别的任务,也可以通过mask去忽略 padding 部分对应的loss。
不过,在 pytorch 中,对 mask 的具体实现形式不是mask矩阵,而是通过一个句子长度列表来实现的,但本质一样。实现如下,sentence_lens 表示的是这个batch中每一个句子的实际长度。
Attention中Mask
在 Attention 机制中,同样需要忽略 padding 部分的影响,这里以transformer encoder中的self-attention为例:
防止标签泄露
在语言模型中,常常需要从上一个词预测下一个词,但如果要在LM中应用 self attention 或者是同时使用上下文的信息,要想不泄露要预测的标签信息,就需要 mask 来“遮盖”它。不同的mask方式,也对应了一篇篇的paper,这里选取典型的几个。
Transformer中的Mask
Transformer 是包括 Encoder和 Decoder的,Encoder中 self-attention 的 padding mask 如上,而 Decoder 还需要防止标签泄露,即在 t 时刻不能看到 t 时刻之后的信息,因此在上述 padding mask的基础上,还要加上 sequence mask。
sequence mask 一般是通过生成一个上三角矩阵来实现的,上三角区域对应要mask的部分。
在Transformer 的 Decoder中,先不考虑 padding mask,一个包括四个词的句子[A,B,C,D]在计算了相似度scores之后,得到下面第一幅图,将scores的上三角区域mask掉,即替换为负无穷,再做softmax得到第三幅图。这样,比如输入 B 在self-attention之后,也只和A,B有关,而与后序信息无关。
self-attention中,Q和K在点积之后,需要先经过mask再进行softmax,因此,对于要屏蔽的部分,mask之后的输出需要为负无穷,这样softmax之后输出才为0。
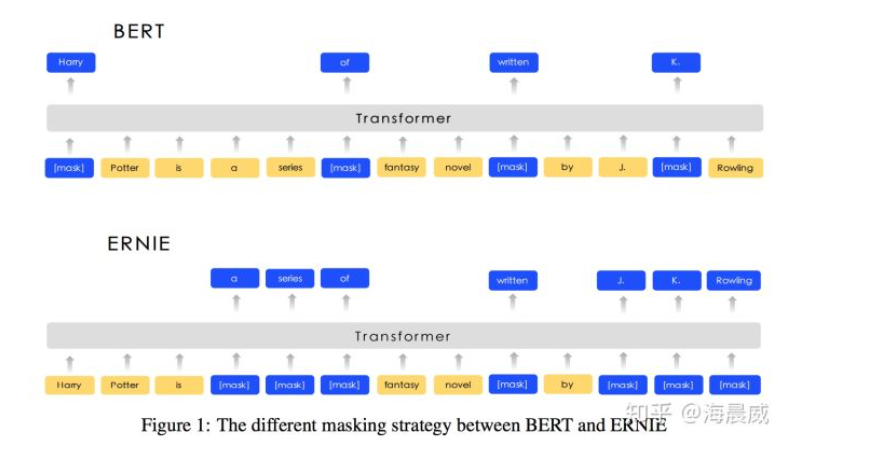
BERT中的Mask
BERT实际上是Transformer的Encoder,为了在语言模型的训练中,使用上下文信息又不泄露标签信息,采用了Masked LM,简单来说就是随机的选择序列的部分token用 [Mask] 标记代替。
这波Mask操作,思想很直接,实现很简单,效果很惊人。