本周记录两个论文,Visual saliency transformer 和 Dynamic grained encoder for VIT。
1、【ICCV2021】Vision saliency transformer
这个工作来自起源人工智能研究院和西北工业大学,是想用 Transformer 强大的长距离建模能力解决RGBD显著性检测问题。但是,VIT是在16x16的patch上提取特征,RGBD是逐像素的给出图像中的标签,如何解决这个问题尚不明确。
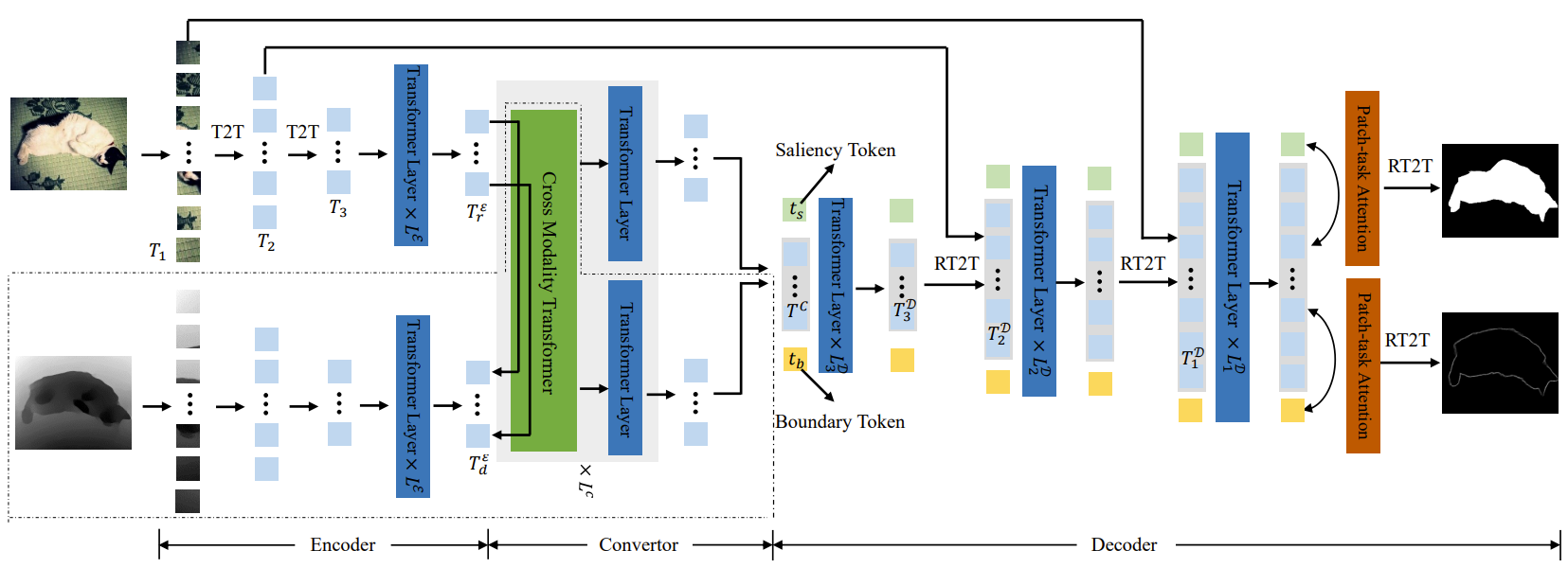
作者提出了如下图所示的框架,结构我个人理解有些像UNET,只不过卷积部分是用 T2T (token-to-token)来替换了。
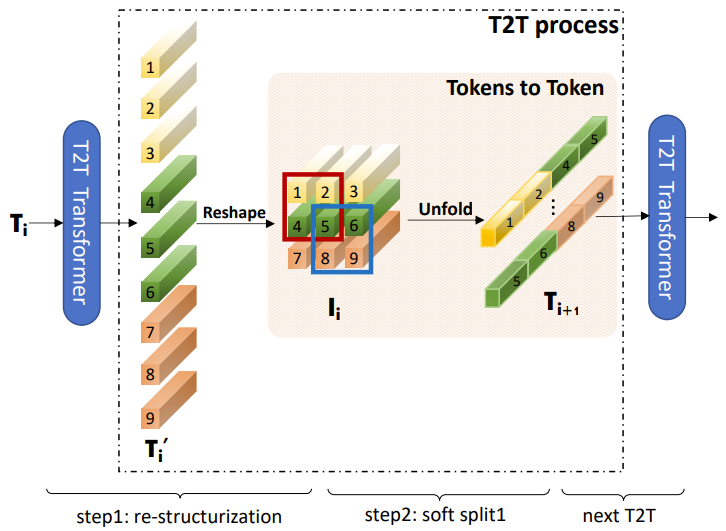
T2T来自于新加坡国立大学的 Tokens-to-Token VIT ,结构如下图所示,比如说输入9个token,首先reshape成一个3X3的矩阵,然后用2X2的窗口融合,然后形成4个新的token输入到下一阶段。个人感觉这个操作可以实现多个token间信息的融合,同时降低了特征的尺度,有些类似卷积,进行特征的加工同时会降低feature map的尺寸。
RGB图像和D图像间的融合使用的是简单的“Scaled Dot-Product Attention”,具体如下:
特征融合以后重要的关键步骤就是如何由低分辨恢复到高分辨率了。这里作者提出了 reverse token-to-token方法,本质上就是把T2T反过来了,不再过多介绍。
2、【NeurIPS2021】Dynamic Grained Encoder for Vision Transformers
这个论文的思路非常有趣,将动态网络的思路应用在了 VIT 中,作者宋林为西安交大博士生,一直从事动态网络相关的研究,已经成体系了。作者指出 VIT 的一个痛点就是计算复杂度非常高,如果将动态网络的思想融合进来,可以有效提高推理的速度。
总体框架如下图所示,主要有改动在Q部分,通过分析不同区域的特征,动态自适应的按1X1,2X2,4X4的尺寸进行token建模,降低了Q里面 token的数量,K和V没有变化。 其中,虚线部分只在训练中会用到,推理时不会用到。
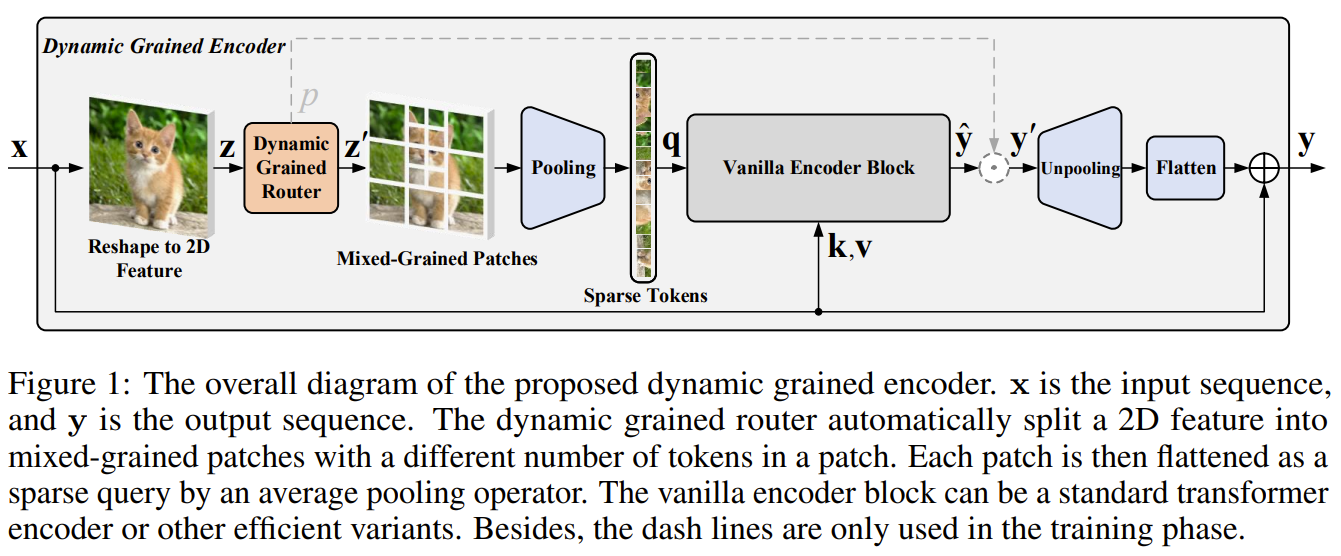
可以看出,论文的核心在于 Dynamic grained encoder (DGE)部分,如下图所示,一个图像首先分为四个region,每个region依次划分为1个、4个、9个多尺度的区域,然后上半部分用 pooling + MLP 的方法得到一组3维向量,分别代表三种划分的权重,选择权重最大的作为依据进行 token 划分。本质上,就是在 token 建模时,建立了多种尺度划分方法,使用了动态路由机制来选择一种划分进行 token 建模。作者去年的代表作也是 CVPR2020 上著名的把动态路由机制用于语义分割,这个工作是把动态路由机制应用于 Transformer 了。 因为 ArgMax 是不可以反向传播的,这里使用了动态网络里的神器 Gambel 方法来解决这个问题,这个方法在很多动态网络里都有应用,不再多介绍了。

论文里的可视化分析结果非常有趣,如下图所示,可以看出,平滑的背景往往选择使用较大的尺度进行 token 建模,有细节纹理的区域会选择较小的尺度进行 token 建模,这和人的感知是基本一致的,因为重要的目标区域需要提取更加丰富的特征,而平滑背景区域不需要提取丰富的特征。
