多模态数据融合时,一般包括:early fusion, late fusion, intermediately 三种,如下图所示。神经科学指出,mid-level feature fusion 有助于学习,但是当前方法仍大多使用 late fusion,这是因为多模态的数据往往因为 different or unaligned spatial dimensions,难以融合。另外一个原因是,单模态特征提取往往解决的较好,可以利用预训练模型中的权重,而中间层融合需要改变网络结构,因此预训练的权重就无法使用了。
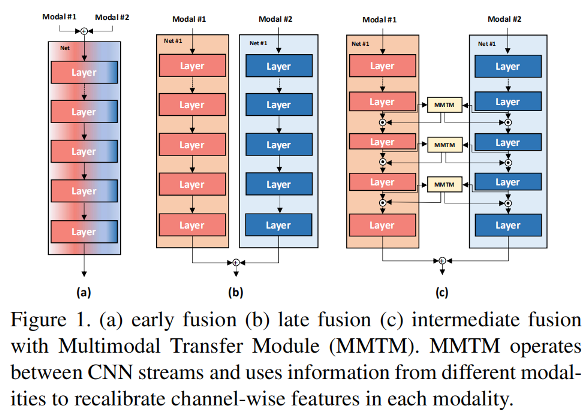
为了解决mid-level feature fusion的问题,作者提出了 multimodal transfer module (MMTM) ,可以 recalibrate the channel-wise features of different CNN streams. 该模块结构如下图所示,包括 squeeze 和 multimodal excitation 两个步骤。
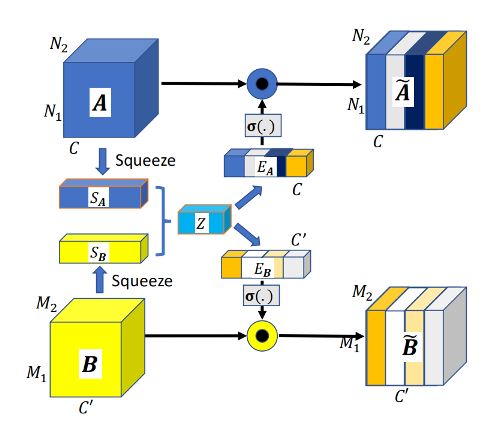
Squeeze: 使用全局池化把 feature map 压缩为一维向量 (S_A) 和 (S_B)。
Multimodal excitation: A数据的通道维数为(C),B数据的通道维数为(C'),这一步需要生成两个exictation signal, (E_Ainmathbb{R}^C), (E_Binmathbb{R}^{C'}) ,达到下面的 gating mechnism:
首先将(S_A) 和 (S_B) 建立一个联合表达 (Z),通过全连接实现,然后使用两个独立的全连接层得到 (E_A)和(E_B)。其中,(Z)的维度是 ((C+C')/4)。
该模块很简单,但是却在 gesture recognition,audio-visual speech enhancement,以及 human action recognition 中取得了非常好的效果。