今天我们来看一下redis的数据类型。既然redis的键值对可以保存不同类型的值,那么很自然就需要对键值对的类型进行检查以及多态处理。下面我们将对redis所使用的对象系统进行了解,并分别观察字符串、哈希表、列表、集合和有序集类型的底层实现。
3.1 对象处理机制
在redis的命令中,用于对键进行处理的命令占了很大一部分,而对于键所保存的值的类型(键的类型),键能执行的命令又各不相同。如:LPUSH和LLEN只能用于列表键,而SADD和SRANDMEMBER只能用于集合键。又比如DEL、TTL和TRPE可以用于任何类型的键,所以要正确实现这些命令,必须为不同类型的键设置不同的处理方式;redis的每一种数据类型,比如字符串、列表、有序集,它们都拥有不止一种底层实现,这说明每当对某种数据进行处理的时候,程序必须根据键所采取的编码进行不同的操作。
综上:操作数据类型的命令除了要对键的类型进行检查之外,还需要根据数据类型的不同编码进行多态处理。
3.1.1 redisObject 数据结构,以及redis的数据类型
redisObject是redis类型系统的核心,数据库中的每个键、值,以及redis本身处理的函数,都表示为这种数据类型。
/* * Redis 对象 */ typedef struct redisObject { // 类型 unsigned type:4; // 对齐位 unsigned notused:2; // 编码方式 unsigned encoding:4; // LRU 时间(相对于server.lruclock) unsigned lru:22; // 引用计数 int refcount; // 指向对象的值 void *ptr; } robj;
type、encoding和ptr是最重要的三个属性。
type记录了对象所保存的值的类型,它的值可能是以下常量中的一个:
/* * 对象类型 */ #define REDIS_STRING 0 // 字符串 #define REDIS_LIST 1 // 列表 #define REDIS_SET 2 // 集合 #define REDIS_ZSET 3 // 有序集 #define REDIS_HASH 4 // 哈希表
encoding记录了对象所保存的值的编码,它的值可能是以下常量中的一个:
/* * 对象编码 */ #define REDIS_ENCODING_RAW 0 // 编码为字符串 #define REDIS_ENCODING_INT 1 // 编码为整数 #define REDIS_ENCODING_HT 2 // 编码为哈希表 #define REDIS_ENCODING_ZIPMAP 3 // 编码为zipmap #define REDIS_ENCODING_LINKEDLIST 4 // 编码为双端链表 #define REDIS_ENCODING_ZIPLIST 5 // 编码为压缩列表 #define REDIS_ENCODING_INTSET 6 // 编码为整数集合 #define REDIS_ENCODING_SKIPLIST 7 // 编码为跳跃表
ptr是一个指针,指向实际保存值的数据结构,这个数据结构由type和encoding属性决定。举个例子, 如果一个redisObject 的type 属性为REDIS_LIST , encoding 属性为REDIS_ENCODING_LINKEDLIST ,那么这个对象就是一个Redis 列表,它的值保存在一个双端链表内,而ptr 指针就指向这个双端链表;
下图展示了redisObject 、Redis 所有数据类型、以及Redis 所有编码方式(底层实现)三者之间的关系:

注意:REDIS_ENCODING_ZIPMAP没有出现在图中,因为在redis2.6开始,它不再是任何数据类型的底层结构。
3.1.2 命令的类型检查和多态
当执行一个处理数据类型命令的时候,redis执行以下步骤:
1)根据给定的key,在数据库字典中查找和他相对应的redisObject,如果没找到,就返回NULL;
2)检查redisObject的type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误;
3)根据redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构;
4)返回数据结构的操作结果作为命令的返回值。
比如现在执行LPOP命令:
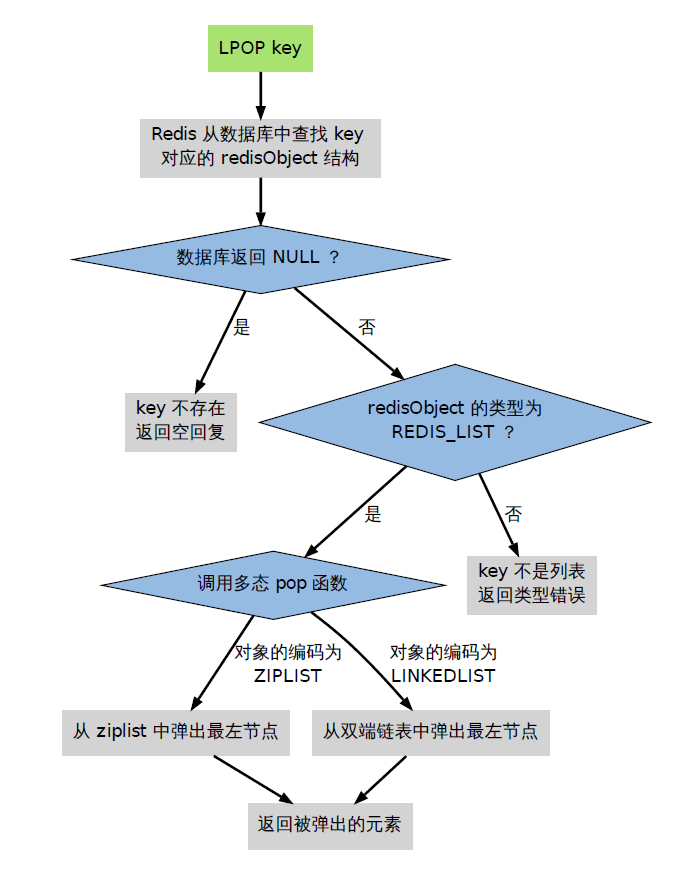
3.1.3 对象共享
redis一般会把一些常见的值放到一个共享对象中,这样可使程序避免了重复分配的麻烦,也节约了一些CPU时间。
redis预分配的值对象如下:
1)各种命令的返回值,比如成功时返回的OK,错误时返回的ERROR,命令入队事务时返回的QUEUE,等等
2)包括0 在内,小于REDIS_SHARED_INTEGERS的所有整数(REDIS_SHARED_INTEGERS的默认值是10000)

注意:共享对象只能被字典和双向链表这类能带有指针的数据结构使用。像整数集合和压缩列表这些只能保存字符串、整数等自勉之的内存数据结构
3.1.4 引用计数以及对象的消毁:
* 每个redisObject结构都带有一个refcount属性,指示这个对象被引用了多少次;
* 当新创建一个对象时,它的refcount属性被设置为1;
* 当对一个对象进行共享时,redis将这个对象的refcount加一;
* 当使用完一个对象后,或者消除对一个对象的引用之后,程序将对象的refcount减一;
* 当对象的refcount降至0 时,这个RedisObject结构,以及它引用的数据结构的内存都会被释放。
3.1.5 小结:
* redis使用自己实现的对象机制来实现类型判断、命令多态和基于引用次数的垃圾回收;
* redis会预分配一些常用的数据对象,并通过共享这些对象来减少内存占用,和避免频繁的为小对象分配内存。
3.2 字符串
REDIS_STRING(字符串)是redis使用最广泛的数据类型,他除了是set、get等命令的操作对象之外,数据库中的所有键,以及执行命令时提供给redis的参数都是用这种类型保存的。
3.2.1 字符串编码:
字符串类型分别使用REDIS_ENCODING_INT和REDIS_ENCODING_RAW两种编码:
* REDIS_ENCODING_INT使用long类型来保存long类型值;
* REDIS_ENCODING_RAW使用sdshdr 结构来保存sds(即是 char*)、long long 、double 和 long double 类型值。
换句话来说,在redis中,只有能表示为long类型的值,才会以整数的形式保存,其他类型的整数、小数和字符串,都是用sdshdr结构来保存。
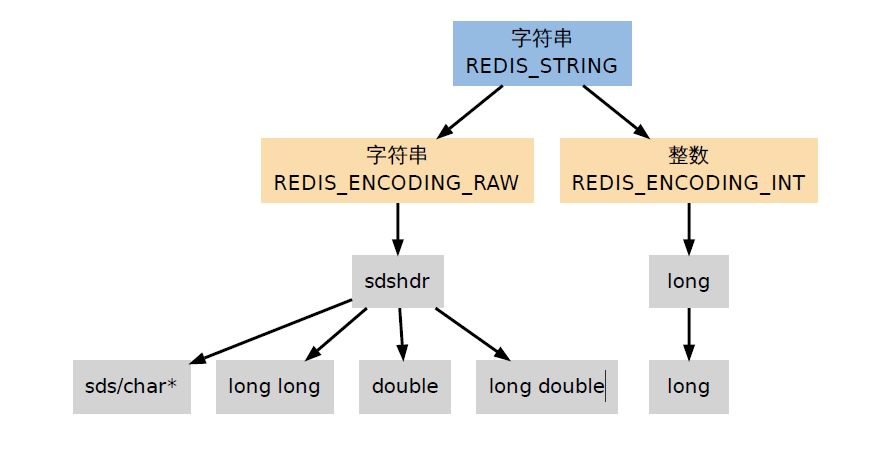
新创建的字符串默认使用REDIS_ENCODING_RAW 编码,在将字符串作为键或者值保存进数据库时,程序会尝试将字符串转为REDIS_ENCODING_INT 编码。
3.3 哈希表
REDIS_HASH(哈希表)是HSET、HLEN等命令的操作对象。他使用REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_HT 两种编码方式:
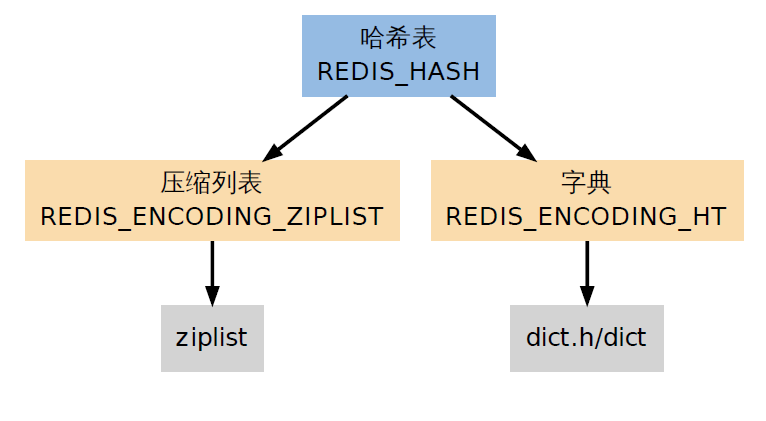
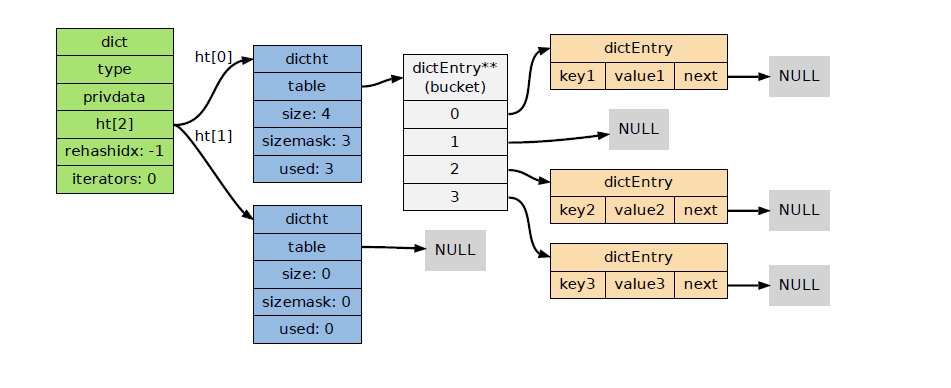
3.3.1 字典编码的哈希表:
哈希表所使用的字典的键和值都是字符串对象。
3.3.2 压缩列表编码的哈希表:
当使用REDIS_ENCODING_ZIPLIST 编码哈希表时,程序通过将键和值一同推入压缩列表,从而形成保存哈希表所需的键-值对结构:

新添加的key-value会被添加到压缩列表的表尾。当进行查找/删除或更新操作时,程序先定位到键的位置,然后再通过对键的位置来定位值的位置。
创建空白哈希表时,程序默认使用REDIS_ENCODING_ZIPLIST 编码,当以下任何一个条件被满足时,程序将编码从切换为REDIS_ENCODING_HT :
• 哈希表中某个键或某个值的长度大于server.hash_max_ziplist_value (默认值为64)。
• 压缩列表中的节点数量大于server.hash_max_ziplist_entries (默认值为512 )。
3.4 列表
REDIS_LIST(列表)是LPUSH、LRANGE等命令的操作对象,他使用REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_LINKEDLIST这两种方式编码:
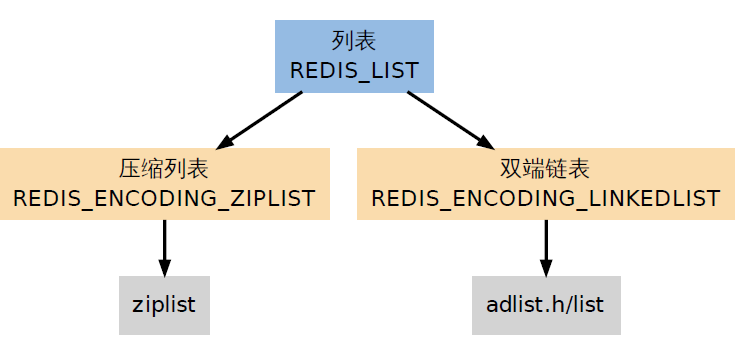
3.4.1 编码的选择:
创建新列表时Redis 默认使用REDIS_ENCODING_ZIPLIST 编码,当以下任意一个条件被满足时,列表会被转换成REDIS_ENCODING_LINKEDLIST 编码:
• 试图往列表新添加一个字符串值, 且这个字符串的长度超过server.list_max_ziplist_value (默认值为64 )。
• ziplist 包含的节点超过server.list_max_ziplist_entries (默认值为512 )。
3.4.2 阻塞的条件:
BLPOP、LRPOP和BRPOPLPUSH三个命令都可能造成客户端被阻塞,所以我们将这些命令统称为列表的阻塞原语。
阻塞原语并不是一定会造成客户端阻塞:
• 只有当这些命令被用于空列表时,它们才会阻塞客户端。
• 如果被处理的列表不为空的话,它们就执行无阻塞版本的LPOP 、RPOP 或RPOPLPUSH命令。
如下:
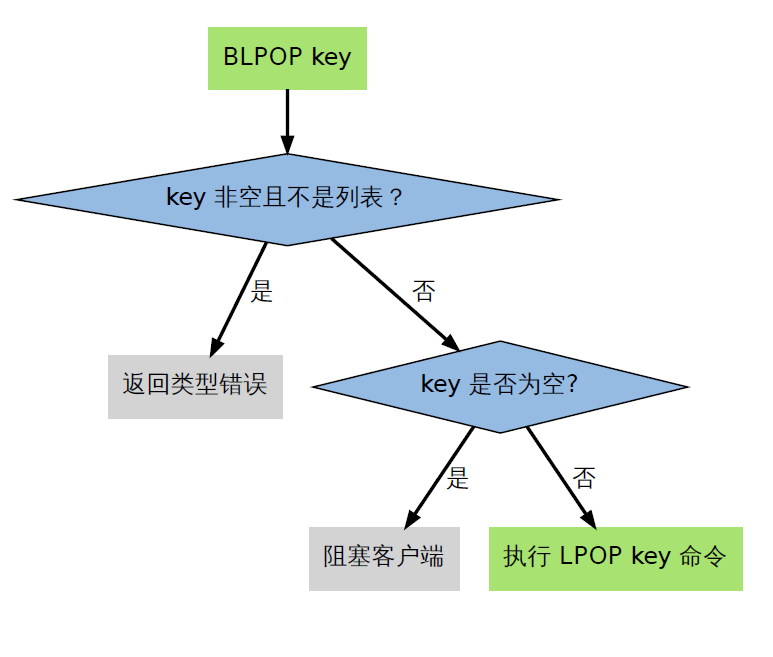
3.4.3 阻塞的过程:
当一个阻塞原语的处理目标为空值时,执行该阻塞原语的客户端就会被阻塞。阻塞一个客户端需要执行以下步骤:
1)将客户端的状态设置为“正在阻塞”,并记录阻塞这个客户端的各个键,以及阻塞的最长时限(timeout)等数据;
2)将客户端的信息记录到server.db[i]->blocking_keys中(其中i为客户端所使用的数据库号码);
3)继续维持客户端和服务器之间的网络连接,但不再向客户端传送任何信息,造成客户端阻塞。
步骤2 是将来解除阻塞的关键,server.db[i]->blocking_keys 是一个字典,字典的键是那些造成客户端阻塞的键,而字典的值是一个链表,链表里保存了所有因为这个键而被阻塞的客户端(被同一个键所阻塞的客户端可能不止一个):

当客户端被阻塞后,脱离阻塞状态有以下3种方法:
1)被动脱离:有其他客户端为造成阻塞的键推入了新元素;
2)主动脱离:到达执行阻塞原语时设定的最大阻塞时间;
3)强制脱离:客户端强制终止和服务器的连接,或者服务器停机。
3.4.4 阻塞因LPUSH、RPUSH、LINSERT等添加命令而被取消
通过将新元素推入造成客户端阻塞的某个键中,可以让相应的客户端从阻塞状态中脱离出来(取消阻塞的客户端数量取决于推入元素的数量);这3个添加元素命令在底层实现上都是pushGenericCommand函数去执行的。
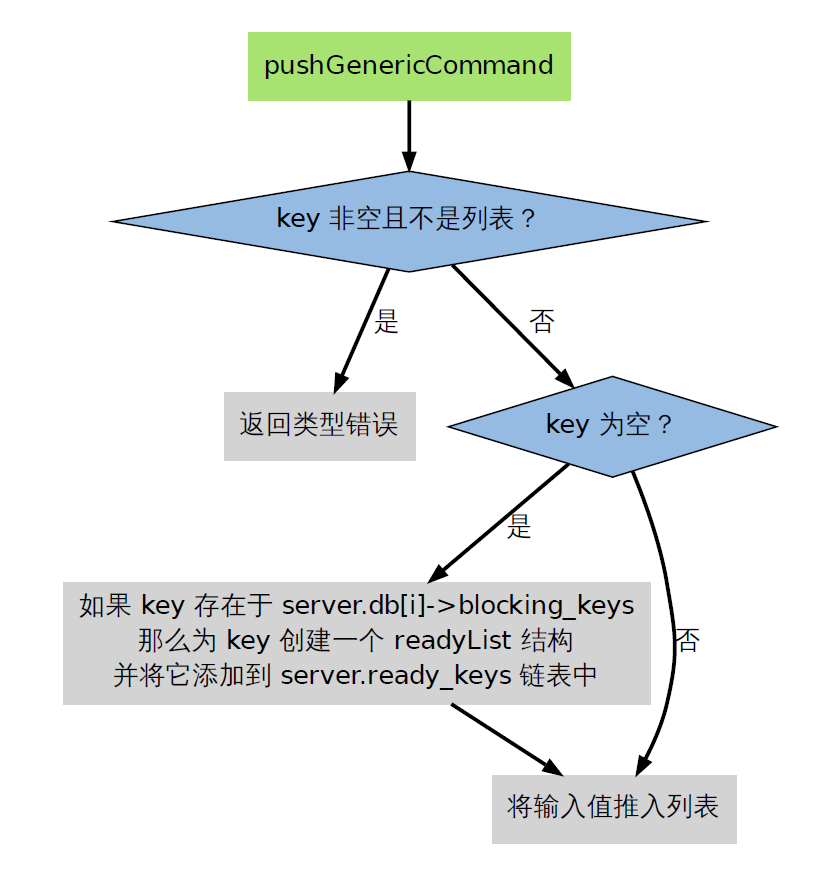
当向一个空键推入新元素时,pushGenericCommand 函数执行以下两件事:
1. 检查这个键是否存在于前面提到的server.db[i]->blocking_keys 字典里,如果是的话,那么说明有至少一个客户端因为这个key 而被阻塞,程序会为这个键创建一个redis.h/readyList 结构,并将它添加到server.ready_keys 链表中。
2. 将给定的值添加到列表键中。
readyList的结构如下:
typedef struct readyList { redisDb *db; robj *key; } readyList;
key属性指向造成阻塞的键,而db则指向该键所在的数据库。
比如说:假设某个非阻塞客户端正在使用0 号数据库,而这个数据库当前的blocking_keys属性的值如下:
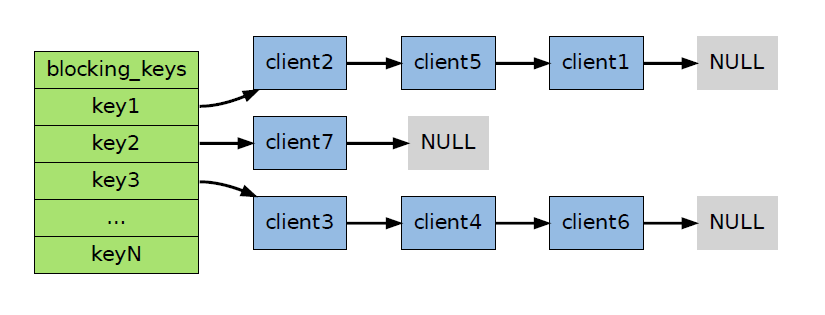
如果这时客户端对该数据库执行PUSH key3 value ,那么pushGenericCommand 将创建一个db 属性指向0 号数据库、key 属性指向key3 键对象的readyList 结构,并将它添加到服务器server.ready_keys 属性的链表中:
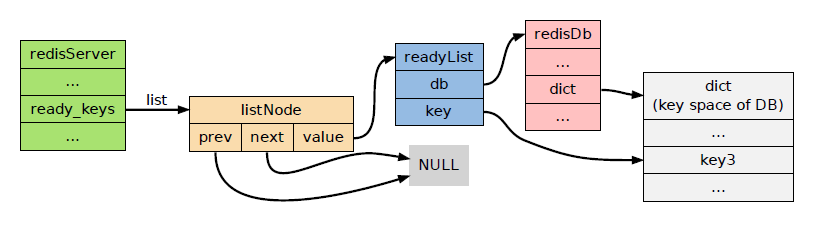
此时pushGenericCommand 函数完成了以下两件事:
1)将readyList添加到服务器;
2)将新元素value添加到键key3;
虽然key3已经不再是空键,但到目前为止,被key3阻塞的客户端还没有任何一个呗解除阻塞状态。这时redis会调用handleClientsBlockedOnLists函数,执行步骤如下:
1. 如果server.ready_keys 不为空, 那么弹出该链表的表头元素, 并取出元素中的readyList 值。
2. 根据readyList 值所保存的key 和db ,在server.blocking_keys 中查找所有因为key而被阻塞的客户端(以链表的形式保存)。
3. 如果key 不为空,那么从key 中弹出一个元素,并弹出客户端链表的第一个客户端,然后将被弹出元素返回给被弹出客户端作为阻塞原语的返回值。
4. 根据readyList 结构的属性,删除server.blocking_keys 中相应的客户端数据,取消客户端的阻塞状态。
5. 继续执行步骤3 和4 ,直到key 没有元素可弹出,或者所有因为key 而阻塞的客户端都取消阻塞为止。
6. 继续执行步骤1 ,直到ready_keys 链表里的所有readyList 结构都被处理完为止。
3.4.5 先阻塞先服务(FBFS)策略
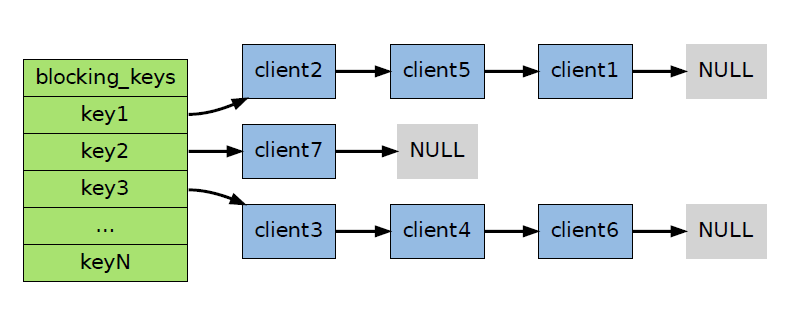
值得一提的是,当程序添加一个新的被阻塞客户端到server.blocking_keys 字典的链表中时,它将该客户端放在链表的最后,而当handleClientsBlockedOnLists 取消客户端的阻塞时,它从链表的最前面开始取消阻塞:这个链表形成了一个FIFO 队列,最先被阻塞 的客户端总值最先脱离阻塞状态,Redis 文档称这种模式为先阻塞先服务(FBFS,first-block-first-serve)。举个例子,在下图所示的阻塞状况中,如果客户端对数据库执行PUSH key3 value ,那么只有client3 会被取消阻塞,client6 和client4 仍然阻塞;如果客户端对数据库执行PUSH key3 value1 value2 ,那么client3 和client4 的阻塞都会被取消,而客户端client6 依然处于阻塞状态:
3.4.6 阻塞因超过最大等待时间而被取消
每次Redis 服务器常规操作函数(server cron job)执行时,程序都会检查所有连接到服务器的客户端,查看那些处于“正在阻塞”状态的客户端的最大阻塞时限是否已经过期,如果是的话,就给客户端返回一个空白回复,然后撤销对客户端的阻塞。
3.5 集合
REDIS_SET(集合) 是SADD。SRANGMEMBER等命令的操作对象,它使用REDIS_ENCODING_INTSET和REDIS_ENCODING_HT两种方式编码:

3.5.1 编码的选择:
第一个添加到集合的元素,决定了创建集合时所使用的编码:
• 如果第一个元素可以表示为long long 类型值(也即是,它是一个整数),那么集合的初始编码为REDIS_ENCODING_INTSET 。
• 否则,集合的初始编码为REDIS_ENCODING_HT 。
3.5.2 编码的切换:
如果一个集合使用REDIS_ENCODING_INTSET 编码,那么当以下任何一个条件被满足时,这个集合会被转换成REDIS_ENCODING_HT 编码:
• intset 保存的整数值个数超过server.set_max_intset_entries (默认值为512 )。
• 试图往集合里添加一个新元素,并且这个元素不能被表示为long long 类型(也即是,它不是一个整数)。
3.5.3 字典编码的集合:
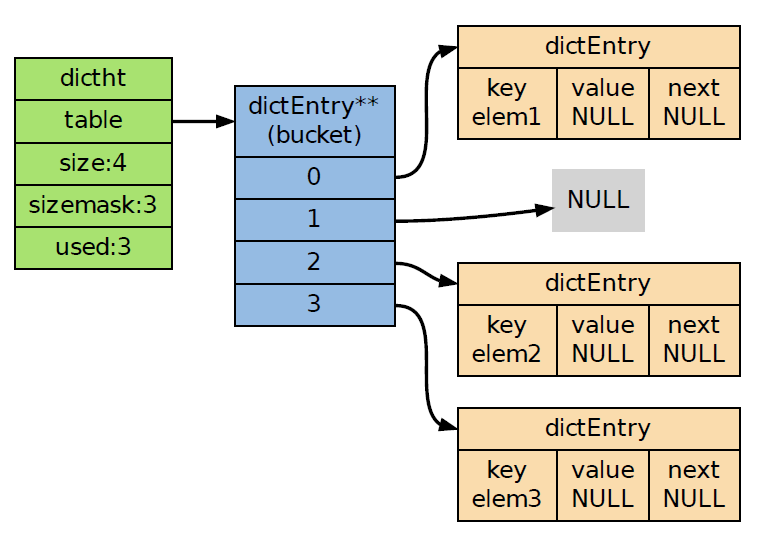
当使用REDIS_ENCODING_HT编码时,集合将元素保存到字典的键里面,而字典的值则统一设为null,如下集合的成员分别是:elem1、elem2和elem3:
3.6 有序集
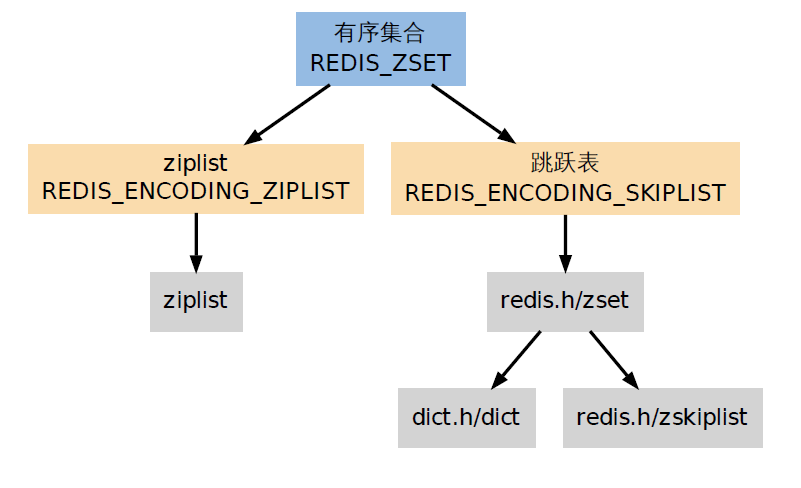
REDIS_ZSET(有序集)是ZADD、ZCOUNT等命令的操作对象,它使用REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST两种编码方式:
3.6.1 编码的选择:
在通过ZADD 命令添加第一个元素到空key 时,程序通过检查输入的第一个元素来决定该创建什么编码的有序集。如果第一个元素符合以下条件的话,就创建一个REDIS_ENCODING_ZIPLIST 编码的有序集:
• 服务器属性server.zset_max_ziplist_entries 的值大于0 (默认为128 )。
• 元素的member 长度小于服务器属性server.zset_max_ziplist_value 的值(默认为64)。否则,程序就创建一个REDIS_ENCODING_SKIPLIST 编码的有序集。
3.6.2 编码的装换:
对于一个REDIS_ENCODING_ZIPLIST 编码的有序集,只要满足以下任一条件,就将它转换为REDIS_ENCODING_SKIPLIST 编码:
• ziplist 所保存的元素数量超过服务器属性server.zset_max_ziplist_entries 的值(默认值为128 )
• 新添加元素的member 的长度大于服务器属性server.zset_max_ziplist_value 的值(默认值为64 )
3.6.3 ZIPLIST编码的有序集
每个有序集元素以两个相邻的ziplist节点表示,第一个节点保存元素的member域,第二个节点保存元素的score值;多个元素之间按score值从小到大排序,如果两个元素的score值相同,那么就按字典对member进行对比,决定哪个元素排在前面,哪个元素排在后面

3.6.4 SKIPLIST编码的有序集
当使用REDIS_ENCODING_SKIPLIST编码时,有序集元素由redis.h/zset 结构来保存
/* * 有序集 */ typedef struct zset { // 字典 dict *dict; // 跳跃表 zskiplist *zsl; } zset;
zset同时使用字典和跳跃表两个数据结构来保存有序集元素。
其中,元素的成员由一个redisObject 结构表示,而元素的score 则是一个double 类型的浮点数,字典和跳跃表两个结构通过将指针共同指向这两个值来节约空间(不用每个元素都复制两份)。
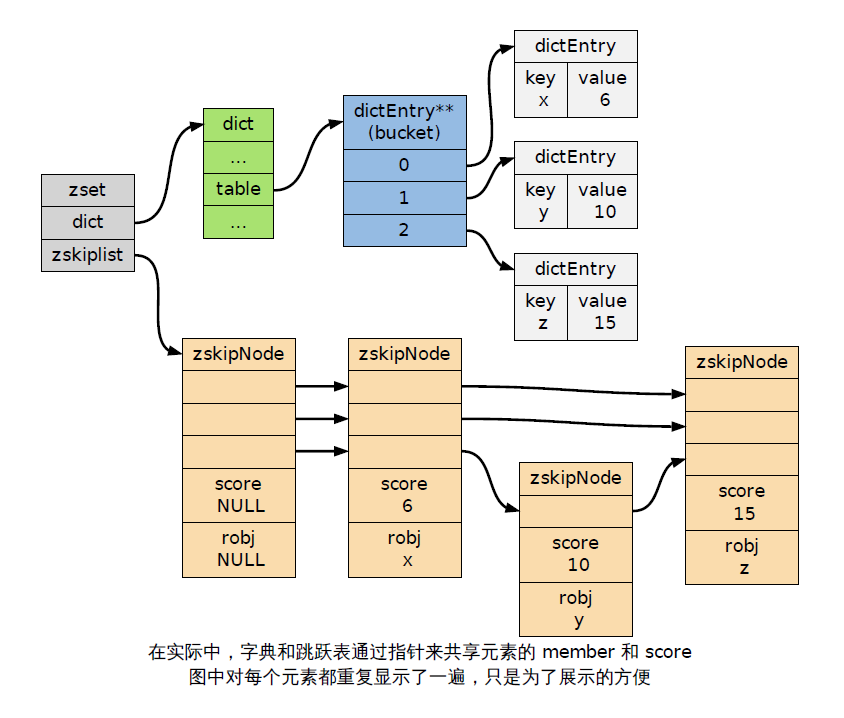
通过使用字典结构,并将member 作为键,score 作为值,有序集可以在O(1) 复杂度内:
• 检查给定member 是否存在于有序集(被很多底层函数使用);
• 取出member 对应的score 值(实现ZSCORE 命令)。
另一方面,通过使用跳跃表,可以让有序集支持以下两种操作:
• 在O(logN) 期望时间、O(N) 最坏时间内根据score 对member 进行定位(被很多底层函数使用);
• 范围性查找和处理操作,这是(高效地)实现ZRANGE 、ZRANK 和ZINTERSTORE等命令的关键。
通过同时使用字典和跳跃表,有序集可以高效地实现按成员查找和按顺序查找两种操作。