RBM网络可以做特征选择,去除冗余和不相关特征,减少计算量,提高准确度
1、原理概述
对于已经训练完成的RBM网络,可以认为已经建立起了特征之间的相关联系。对于任意特征i,如果可以通过其他特征经由rbm网络计算得出,那么我们就可以认为这个特征i是冗余的。具体怎么计算呢?首先定义v'为v的重构(见上一篇概念理解部分),那么对任意特征i,可定义重构误差ei(也就是vi和v‘i相差多少,当然不是做简单加减,具体见下方),然后使用训练数据对RBM网络进行两次测试,第一次使用原始数据,第二次把特征i的值变成零再测试,如果两次运行的结果,变成0之后的误差不变或者更小了,那么就认为,这个特征i是冗余的。
2、具体过程
特征选择通过三个步骤进行:1)初始训练:对包含所有特征的训练数据进行rbm训练;2)特征消除:通过初始训练的rbm去除额外特征;3)主训练:在包含选定特征的训练数据上用初始训练的rbm训练dbm。
1)RBM网络训练,详细见上篇,此处为方便阅读,首先把相关公式做如下处理
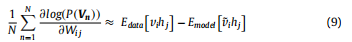
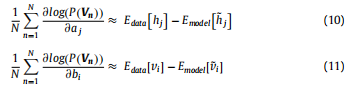
即:将梯度公式直接由期望形式表达。其中Edata表示由训练数据得出的期望,Emodel表示所有可能情况下该模型的期望,其中第二项中v(上滑~)表示使用吉布斯采样得到近似数据
2)特征消除
该算法从所有输入特征的集合开始,利用训练后的rbm来评价每组特征的效果。
定义重建误差
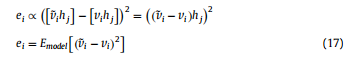
从形式上看,ei就是i特征的重建相对于原始输入值的方差,也就是偏离程度,先称作原始重建误差
然后,对某个我们想判断的特征i,设置对应单元vi=0,然后把数据输入rbm网络,并计算
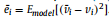
注意这里的v(上标—)是设置vi=0后得到的vi的重建。则ei(上标—)即为设置后的重建误差。先称作对比重建误差
下面对两个重建误差作比较,如果对比重建误差<原始重建误差,就说明特征i的vi=0之后,比他原来的值得到的结果同优或更优,即此i为荣誉特征,舍弃。反之采纳。
注:个人理解标注,首先这个过程使用的是已经建立好的RBM。其次,对重建误差的计算,要使用训练集所有元素的特征i,也即ei所求是每一个训练元素输入到RBM中其i特征的重建相对于自己原始输入偏差值的加和
3)使用选择特征和对应权重初始化RBM网络并进行训练DBM等
3、算法伪代码(两种)


参考资料:
[1] Aboozar Taherkhani, Deep-FS: A feature selection algorithm for Deep Boltzmann Machines, 2018